举个例子,13 是一个素数,2 的 13-1(即 12)次方等于 4096。用它除以 13 得到 315,余数为 1。可以证明,所有 2 以外的素数都满足这个性质。但是满足这个性质的数不一定都是素数,它们被称为伪素数(又称为卡迈克尔数)。一万以内的伪素数有七个:561,1105,1729,2465,2821,6601,以及 8911。我们利用这些伪素数来对美股进行选股:选择股票编号中包含上述伪素数的股票进行投资。按照这个规则,Ametek公司(一个制造企业,股票编号03110510)脱颖而出。更令人称奇的是,它在过去 40 年取得了 95 倍的累计收益,远超道琼斯工业或标普 500 指数。
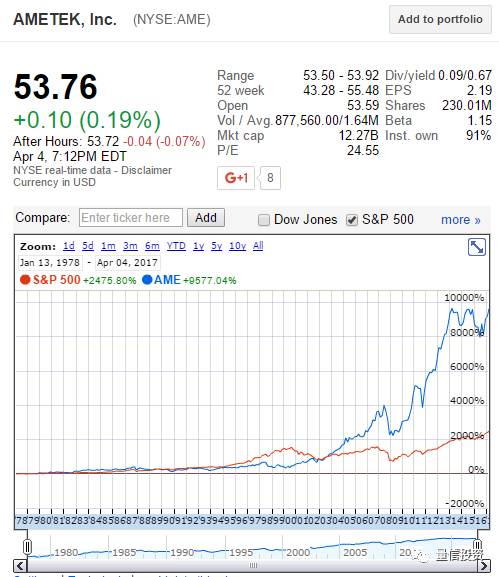
毫无疑问,这是一支非凡的股票,而我们的伪素数策略取得了巨大的成功。然而, 先别急着激动。我们需要好好审视一下:伪素数和选股到底有什么关系?答案是没有关系。那么这个策略是否真正找到了有效的选股模式?答案也是否定的。
有些人会马上跳出来说“只要管用就行,为什么有用不重要!”。这种认知是非常危险的。对于选股这种非实验性问题,由于无法通过对照实验来检验假设,那么至少从业务上明白机器学习的算法为什么有效就显得格外重要。因此,“只要管用就行”是非常不负责任的态度。
这个例子代表了很多机器学习算法的问题:我们总可以使用复杂的非线性算法(比如神经网络)、通过过度优化参数发现回测中无敌的选股模式。在这个过程中,我们已然落入了数据迁就的陷阱。
认知偏差加剧数据迁就
在以下这些条件下很容易发生数据迁就问题,很显然它们都存在于二级市场投资中
1. 存在大量的数据。
2. 很多人都在使用同样的数据进行分析。
3. 缺乏业务理论或者无法控制变量。
4. 认知偏差“只要管用就行,为什么好使不重要”。
这其中前三条是市场的客观条件,而最后一条则植根于人们的认知错误。人类认知中总是倾向于追寻不同寻常的事件。只有当一些“不同寻常”的巧合发生时,我们才往往能关注到。瑞士心理学家荣格将人们对巧合的过度关注称为共时性(synchronicity)。
共时性:指“有意义的巧合”,用于解释因果律无法解释的现象,如梦境成真,想到某人某人便出现等(“说曹操、曹操到”)。荣格认为,这些表面上无因果关系的事件之间有着非因果性、有意义的联系,这些联系常取决于人的主观经验。当两者同时发生时,便称为“共时性”现象。
通俗的说,当在时间和空间上毫无联系的两件事同时发生时,人们便会认为有一种超自然的神秘力量把它们联系在一起,并认为这种巧合具备某种意义。
比如在上面的例子中,股票标码含有伪素数和股票获得了巨大的超额收益就是一个纯粹的巧合,这样的巧合被机器学习算法发现并呈现给使用者。如果使用者不试图去理解这两者到底是否真的有关系,便会由于共时性而将这种错误的巧合赋予某种意义,即机器学习发现了一个牛逼哄哄的选股模式。
运气还是实力
前面说了这么多,目的当然不是为了否定人工智能和机器学习在二级市场的应用前景。
但我想说,对于人工智能发现的任何模式,它有效的前提是我们能够明白无误的理解它的含义。不能以此为基础便无法分辨出好的结果到底是来自运气还是实力。
我们使用顺序统计量(order statistic)解释了这样一个道理:
在众多股票中,最好的那支总会有非常优秀的收益率;在众多的策略中,最厉害的那一个总会带来令人称奇的回报率。然而,通过计算独立样本的极值(顺序统计量)分布可知,这种结果实属必然。
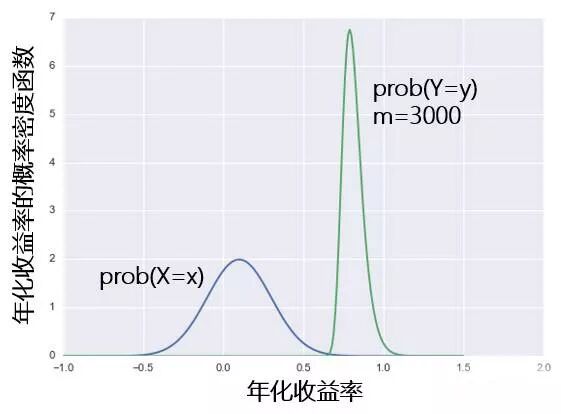
假设一个股票投资策略的年化收益率 X 符合均值为 10%,标准差为 20% 的正态分布。假设市场中有 m 个不同的策略,则它们中最好的那个的收益率 Y 是 X 的函数,Y = max(X1, X2, …, Xm)。下图是当 m = 3000 时,最好的那个的收益率分布和单一策略收益率分布的比较:最优策略的收益率分布在横坐标上向右移动且变的更窄。
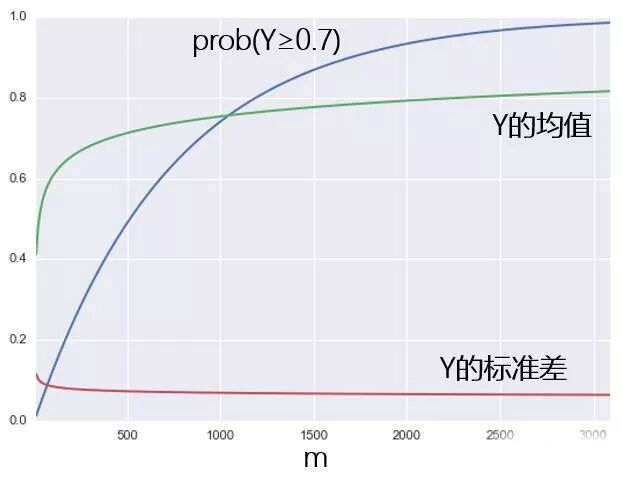
下图为 prob(Y≥0.7) 随策略个数 m 变化的结果。同时也给出了 Y 的均值和标准差随 m 的变化。随着 m 的增大,我们越来越确定总会有一些策略脱颖而出,年化收益率超过 70%。这种判断也同样可以被 Y 的均值和方差来证明:随着策略个数的增大,最优策略的年化收益率的均值在增加,且标准差在减小。
这个结果说明,当存在大量不同的策略时,最好的那一个总会异常非凡。但我们真正关心的问题是:这个策略到底是在茫茫历史数据中找到了虚假的模式,还是发现了一套真正的科学投资模式?我们必须从业务层面弄清楚它是如何工作的。









