一段自动抓取互联网信息的程序,可以从一个URL出发,访问它所关联的URL,提取我们所需要的数据。也就是说爬虫是自动访问互联网并提取数据的程序。
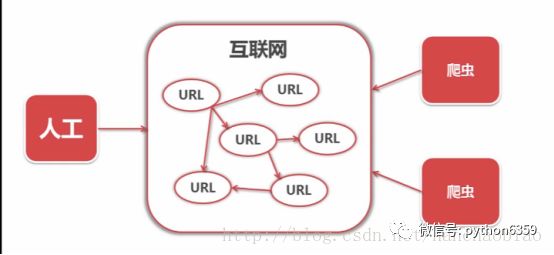
将互联网上的数据为我所用,开发出属于自己的网站或APP
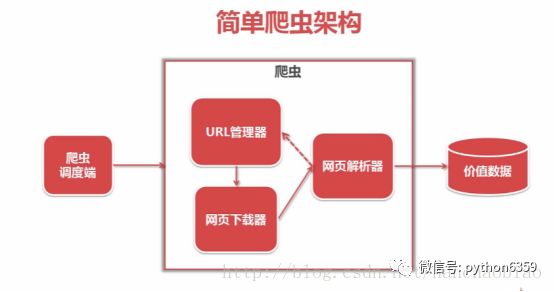
爬虫调度端:用来启动、执行、停止爬虫,或者监视爬虫中的运行情况
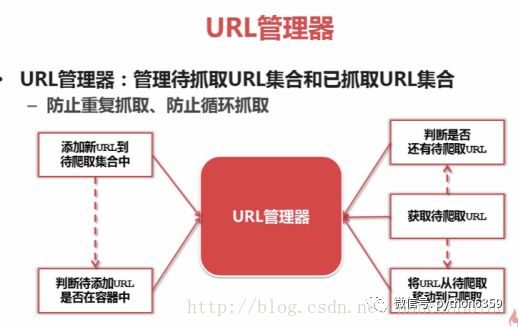
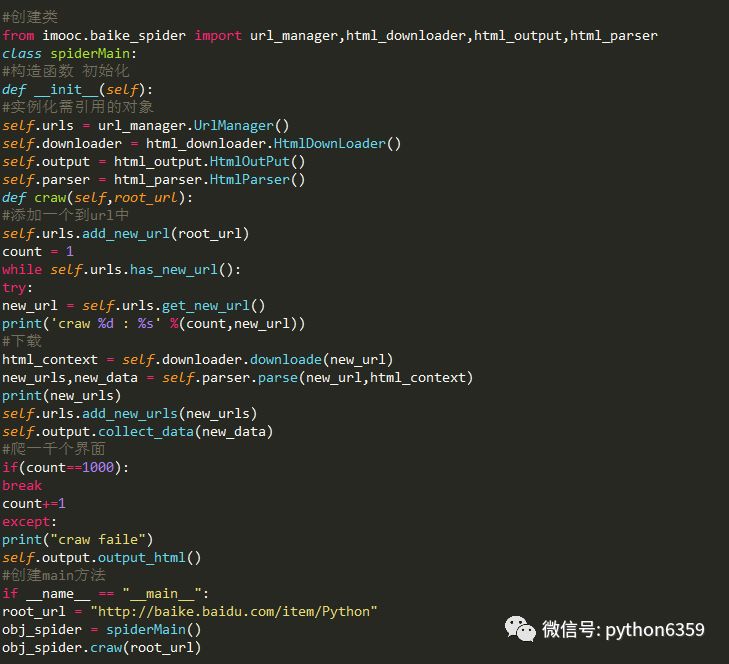
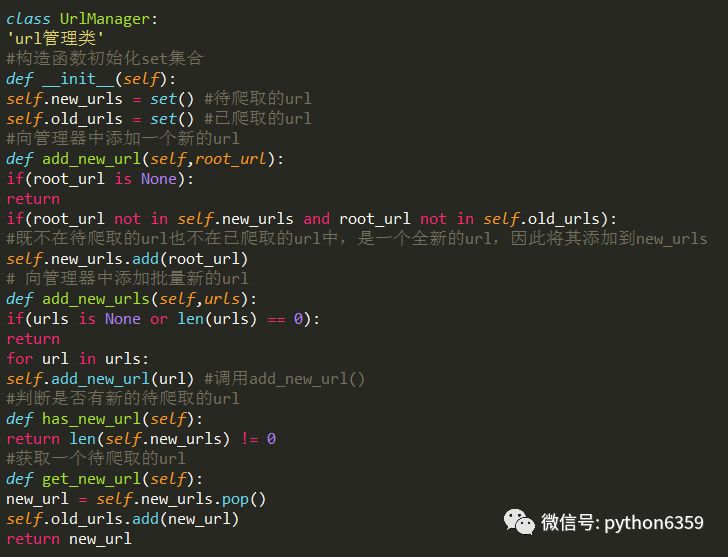
在爬虫程序中有三个模块URL管理器:对将要爬取的URL和已经爬取过的URL这两个数据的管理
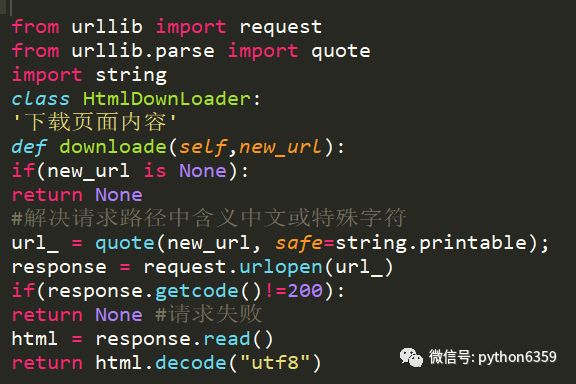
网页下载器:将URL管理器里提供的一个URL对应的网页下载下来,存储为一个字符串,这个字符串会传送给网页解析器进行解析
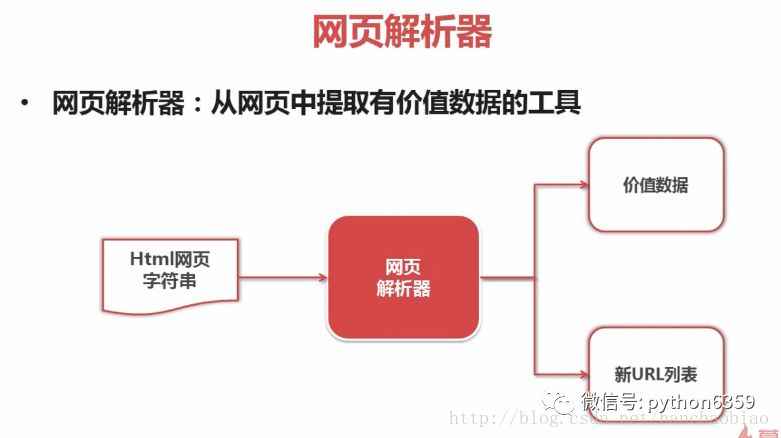
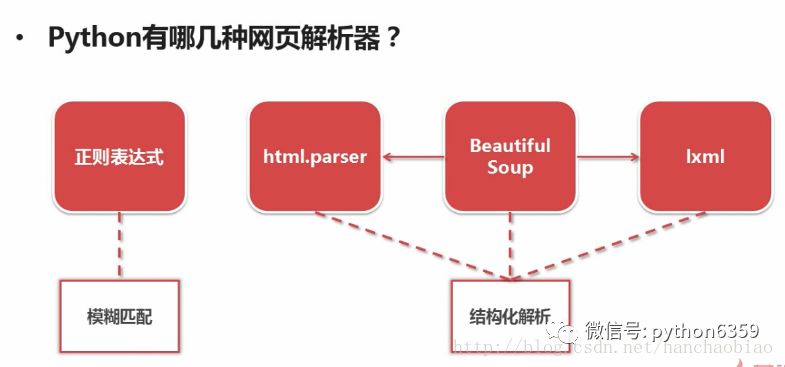
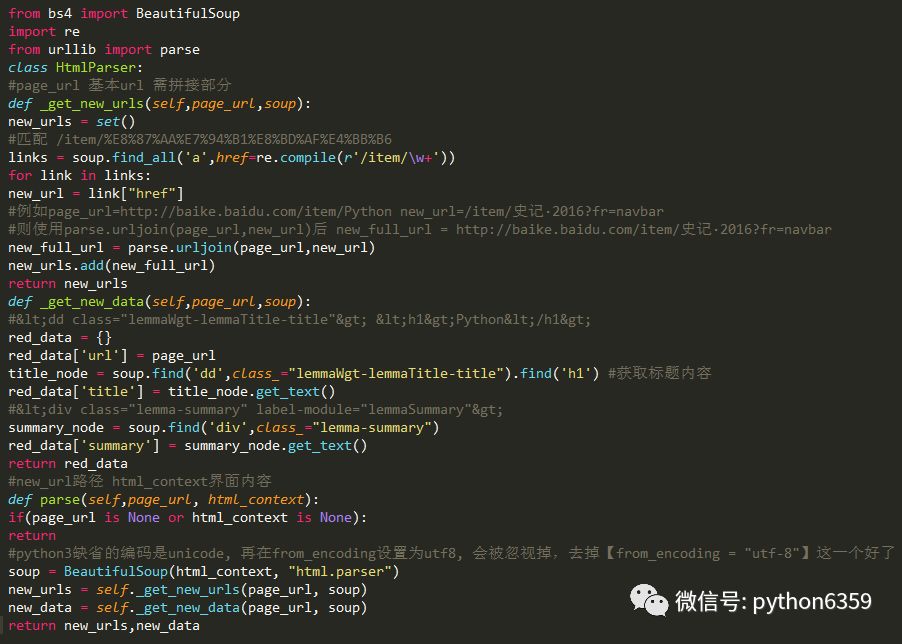
网页解析器:一方面会解析出有价值的数据,另一方面,由于每一个页面都有很多指向其它页面的网页,这些URL被解析出来之后,可以补充进URL管理器
这三部门就组成了一个简单的爬虫架构,这个架构就能将互联网中所有的网页抓取下来
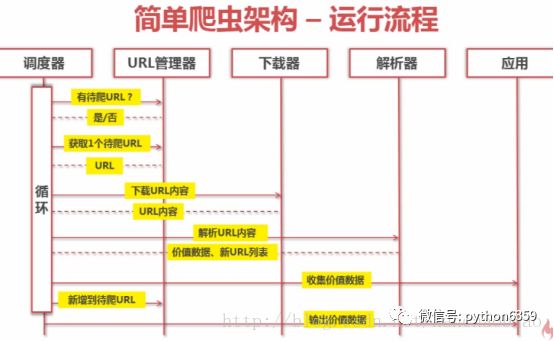
动态执行流程
防止重复抓取和循环抓取,最严重情况两个URL相互指向就会形成死循环
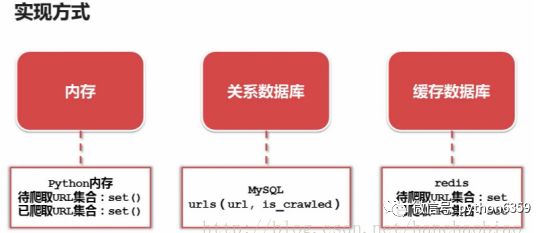
三种实现方式
Python内存set集合:set集合支持去重的作用
Mysql:url(访问路径)is_crawled(是否访问)
Redis:使用Redis性能最好,且Redis中也有set类型,可以去重。不懂得同学可以看下Redis的介绍
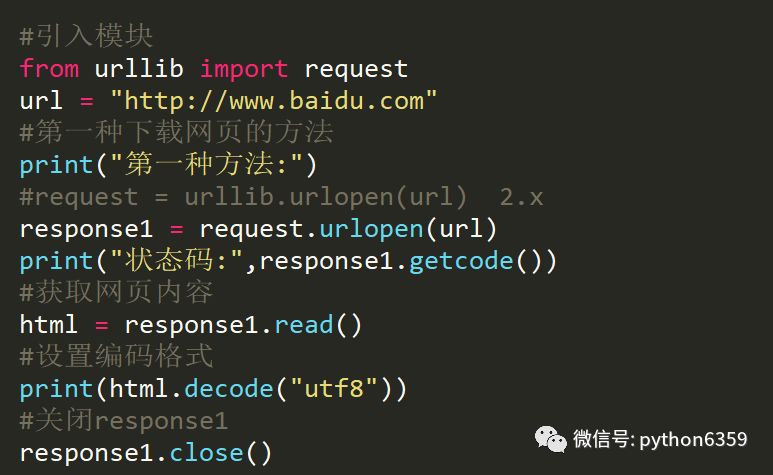
本文使用urllib实现
urllib2是python自带的模块,不需要下载。
urllib2在python3.x中被改为urllib.request
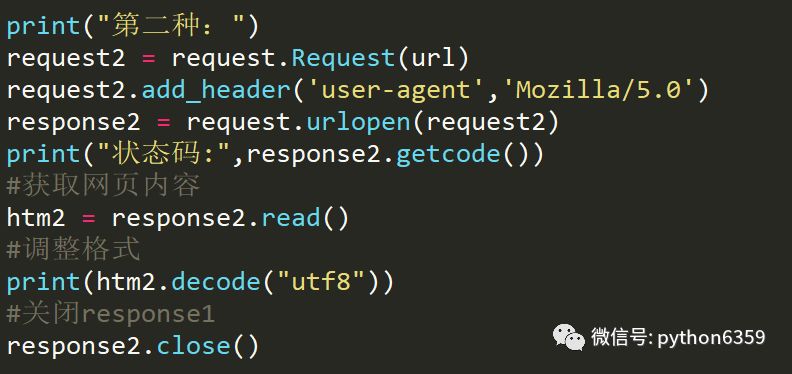
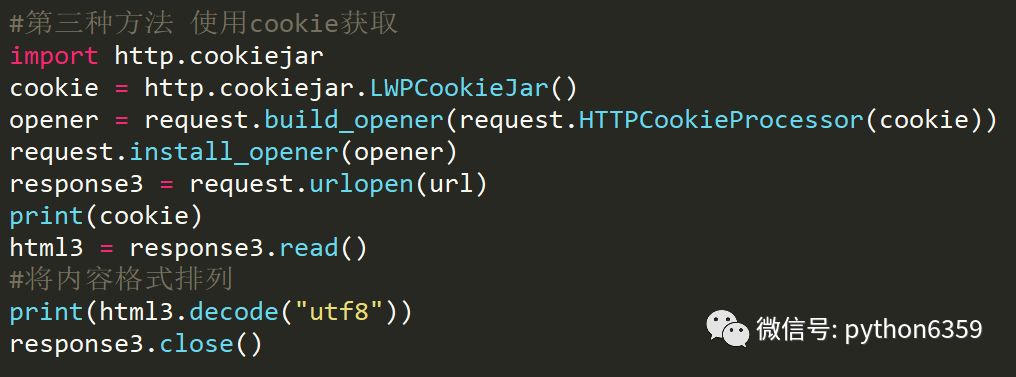
使用cookie
测试是否安装bs4



html采用官方案例

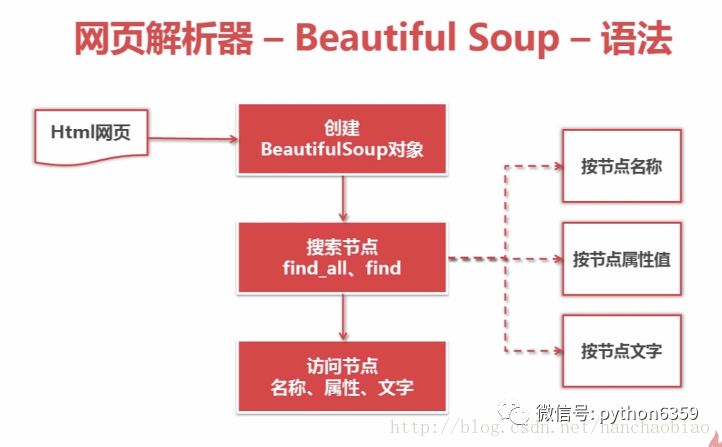
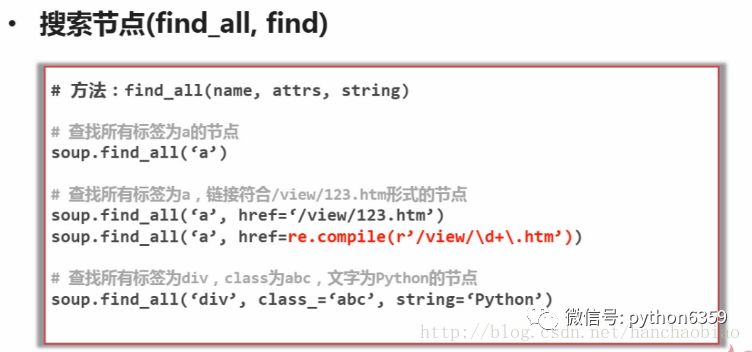
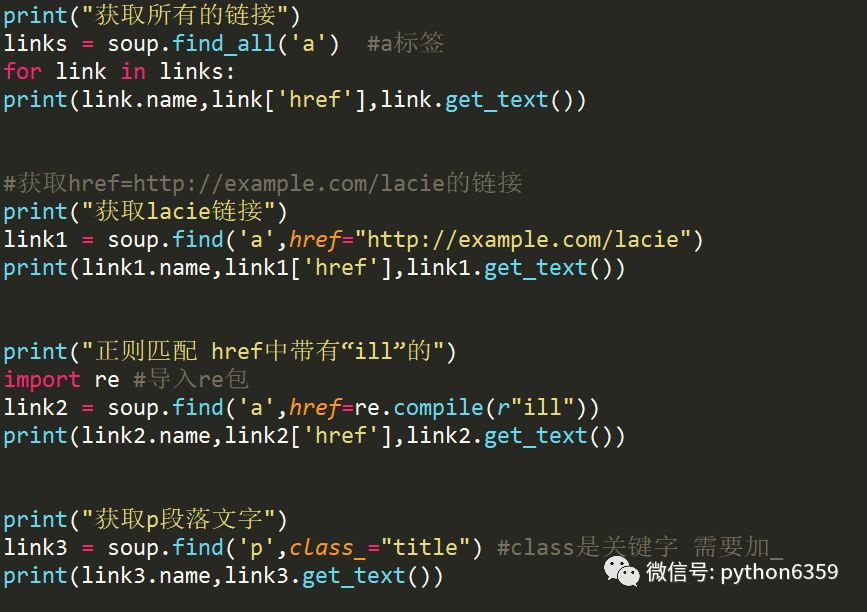
获取所有的链接
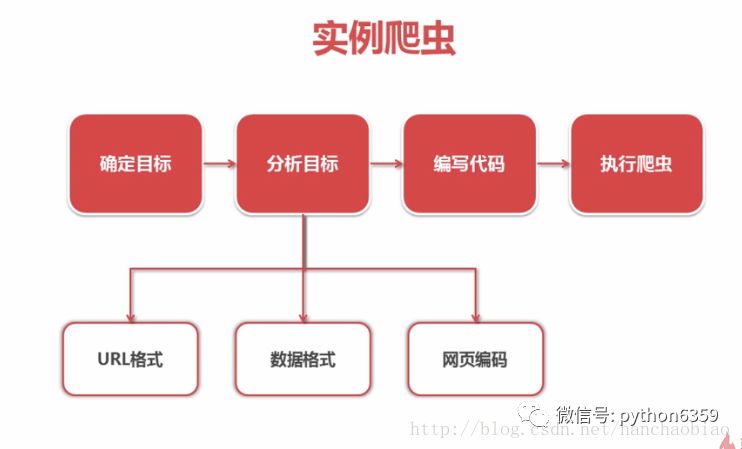
入口:http://baike.baidu.com/item/Python
分析URL格式:防止访问无用路径 http://baike.baidu.com/item/{标题}
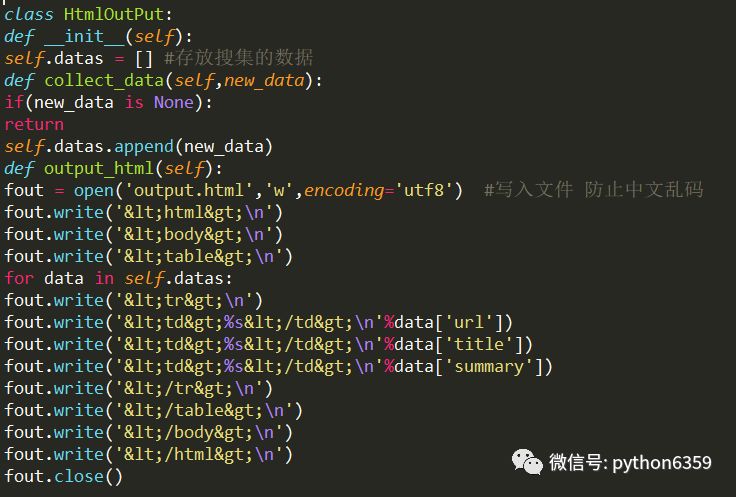
数据:抓取百度百科相关Python词条网页的标题和简介
通过审查元素得标题元素为 :class=”lemmaWgt-lemmaTitle-title”
简介元素为:class=”lemma-summary”
页面编码:UTF-8
作为定向爬虫网站要根据爬虫的内容升级而升级如运行出错可能为百度百科升级,此时则需要重新分析目标
作者:loading
源自:www.androidchina.net/8417.html
声明:文章著作权归作者所有,如有侵权,请联系小编删除






