
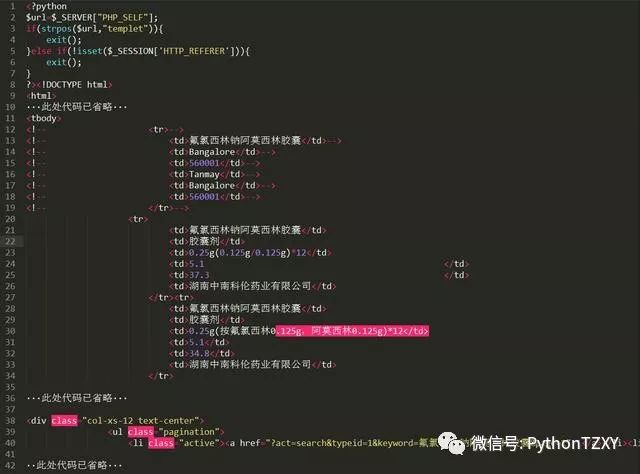
从代码的第一行可以看出该站使用的是PHP,url为“http://www.china-yao.com/?act=search&typeid=1&keyword=%E6%B0%9F%E6%B0%AF%E8%A5%BF%E6%9E%97%E9%92%A0%E9%98%BF%E8%8E%AB%E8%A5%BF%E6%9E%97%E8%83%B6%E5%9B%8A”,其中“keyword=”后跟的是“氟氯西林钠阿莫西林胶囊”的utf8编码格式,该药品的价格信息比较多,总共有3页,点开第三页后,此时url变为“http://www.china-yao.com/?act=search&typeid=1&keyword=%E6%B0%9F%E6%B0%AF%E8%A5%BF%E6%9E%97%E9%92%A0%E9%98%BF%E8%8E%AB%E8%A5%BF%E6%9E%97%E8%83%B6%E5%9B%8A&page=3”,就是在原url地址的基础上增加了“&page=3”,其中数字3表示第三页。而页码数存在于代码(
)之间。很显然,我们只需要把url中“keyword=”和“&page=”后面的信息替换掉就可以组合出带有我们需要信息的页面的url。之后把生成的url进行utf8编码后发送给网站,生成带有查询结果的页面,筛选出(
······ )之间的信息进行保存。
好了,了解到这些之后,下面我们就开始写代码了。
一、使用到的软件工具
Python 2.7
Eclipse

二、导入需要用到的模板
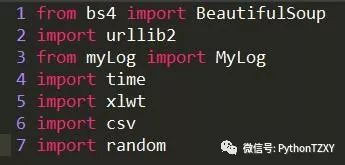
其中myLog是一个自定义模板,其实就是对logging模板的简单格式化,代码如下:
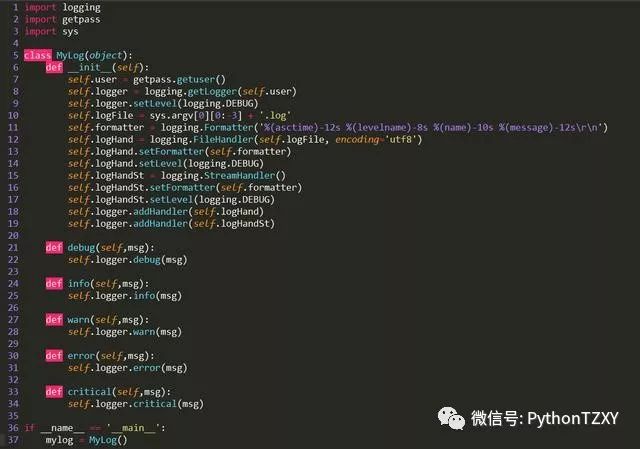
三、简单构建好框架,写出需要用到的主要函数和方法,代码如下:



不加“&page=n”的情况下,只返回查询结果第一页的信息。但查询结果总共有多少页?我们需要先提取出这个最大页数。
在页面代码

的这一段之中,有我们需要的页码值,而我们只需要最后一页,也就是最大值。
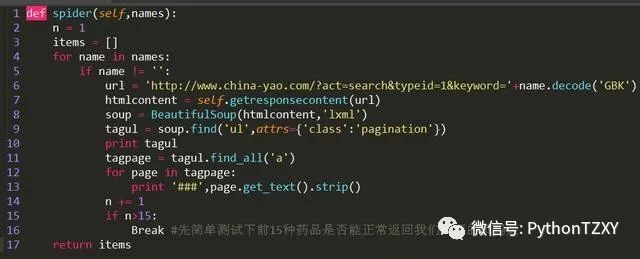
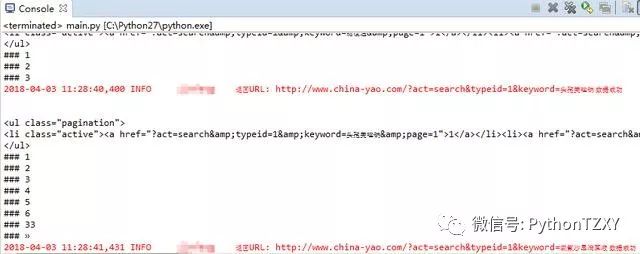
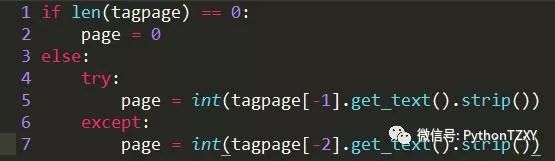
从运行结果来看,效果还算满意,通过tagul.find_all('a')得到的列表最后一条基本都是结果页面最后一页的页码。但如果结果页面过多的时候,可以看到最后一页的页码不在列表的最后,而是处于列表的倒数第二行。修改增加如下代码,利用try来让程序自动选择提取最后一行还是倒数第二行。
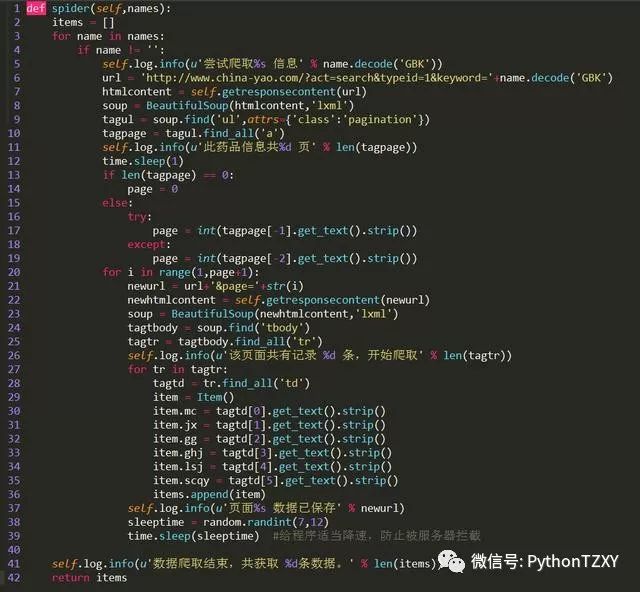
获取到最后一页查询结果的页码值后,我们就可以组合出完整的url地址了。遍历所有的url组合,提取出tbody之间的药品价格信息。方法spider的完整代码如下:
五、保存收集到的数据
添加方法pipelinespipelines_xls和pipelines_csv的代码



那么你学会了吗?








