本文将讲述 udp 协议的会话机制原理,以及基于 nginx 如何配置 udp 协议的反向代理,包括如何维持住 session、透传客户端 ip 到上游应用服务的 3 种方案等。许多人眼中的 udp 协议是没有反向代理、负载均衡这个概念的。毕竟,udp 只是在 IP 包上加了个仅仅 8 个字节的包头,这区区 8 个字节又如何能把 session 会话这个特性描述出来呢?
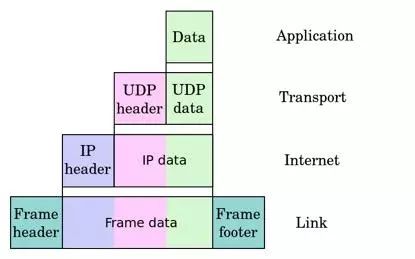
图 1 UDP 报文的协议分层
在 TCP/IP 或者 OSI 网络七层模型中,每层的任务都是如此明确:
物理层专注于提供物理的、机械的、电子的数据传输,但这是有可能出现差错的;
数据链路层在物理层的基础上通过差错的检测、控制来提升传输质量,并可在局域网内使数据报文跨主机可达。这些功能是通过在报文的前后添加 Frame 头尾部实现的,如上图所示。每个局域网由于技术特性,都会设置报文的最大长度 MTU(Maximum Transmission Unit),用 netstat -i(linux) 命令可以查看 MTU 的大小: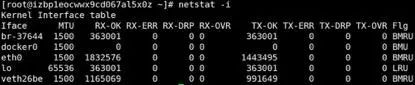
而 IP 网络层的目标是确保报文可以跨广域网到达目的主机。由于广域网由许多不同的局域网,而每个局域网的 MTU 不同,当网络设备的 IP 层发现待发送的数据字节数超过 MTU 时,将会把数据拆成多个小于 MTU 的数据块各自组成新的 IP 报文发送出去,而接收主机则根据 IP 报头中的 Flags 和 Fragment Offset 这两个字段将接收到的无序的多个 IP 报文,组合成一段有序的初始发送数据。IP 报头的格式如下图所示:
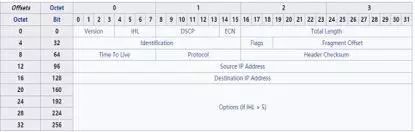
图 2 IP 报文头部
传输层主要包括 TCP 协议和 UDP 协议。这一层最主要的任务是保证端口可达,因为端口可以归属到某个进程,当 chrome 的 GET 请求根据 IP 层的 destination IP 到达 linux 主机时,linux 操作系统根据传输层头部的 destination port 找到了正在 listen 或者 recvfrom 的 nginx 进程。所以传输层无论什么协议其头部都必须有源端口和目的端口。例如下图的 UDP 头部:

图 3 UDP 的头部
TCP 的报文头比 UDP 复杂许多,因为 TCP 除了实现端口可达外,它还提供了可靠的数据链路,包括流控、有序重组、多路复用等高级功能。由于上文提到的 IP 层报文拆分与重组是在 IP 层实现的,而 IP 层是不可靠的所有数组效率低下,所以 TCP 层还定义了 MSS(Maximum Segment Size)最大报文长度,这个 MSS 肯定小于链路中所有网络的 MTU,因此 TCP 优先在自己这一层拆成小报文避免的 IP 层的分包。而 UDP 协议报文头部太简单了,无法提供这样的功能,所以基于 UDP 协议开发的程序需要开发人员自行把握不要把过大的数据一次发送。
对报文有所了解后,我们再来看看 UDP 协议的应用场景。相比 TCP 而言 UDP 报文头不过 8 个字节,所以 UDP 协议的最大好处是传输成本低(包括协议栈的处理),也没有 TCP 的拥塞、滑动窗口等导致数据延迟发送、接收的机制。但 UDP 报文不能保证一定送达到目的主机的目的端口,它没有重传机制。所以,应用 UDP 协议的程序一定是可以容忍报文丢失、不接受报文重传的。如果某个程序在 UDP 之上包装的应用层协议支持了重传、乱序重组、多路复用等特性,那么他肯定是选错传输层协议了,这些功能 TCP 都有,而且 TCP 还有更多的功能以保证网络通讯质量。因此,通常实时声音、视频的传输使用 UDP 协议是非常合适的,我可以容忍正在看的视频少了几帧图像,但不能容忍突然几分钟前的几帧图像突然插进来:-)
有了上面的知识储备,我们可以来搞清楚 UDP 是如何维持会话连接的。对话就是会话,A 可以对 B 说话,而 B 可以针对这句话的内容再回一句,这句可以到达 A。如果能够维持这种机制自然就有会话了。UDP 可以吗?当然可以。例如客户端(请求发起者)首先监听一个端口 Lc,就像他的耳朵,而服务提供者也在主机上监听一个端口 Ls,用于接收客户端的请求。客户端任选一个源端口向服务器的 Ls 端口发送 UDP 报文,而服务提供者则通过任选一个源端口向客户端的端口 Lc 发送响应端口,这样会话是可以建立起来的。但是这种机制有哪些问题呢?
问题一定要结合场景来看。比如:1、如果客户端是 windows 上的 chrome 浏览器,怎么能让它监听一个端口呢?端口是会冲突的,如果有其他进程占了这个端口,还能不工作了?2、如果开了多个 chrome 窗口,那个第 1 个窗口发的请求对应的响应被第 2 个窗口收到怎么办?3、如果刚发完一个请求,进程挂了,新启的窗口收到老的响应怎么办?等等。可见这套方案并不适合消费者用户的服务与服务器通讯,所以视频会议等看来是不行。
有其他办法么?有!如果客户端使用的源端口,同样用于接收服务器发送的响应,那么以上的问题就不存在了。像 TCP 协议就是如此,其 connect 方的随机源端口将一直用于连接上的数据传送,直到连接关闭。这个方案对客户端有以下要求:不要使用 sendto 这样的方法,几乎任何语言对 UDP 协议都提供有这样的方法封装。应当先用 connect 方法获取到 socket,再调用 send 方法把请求发出去。这样做的原因是既可以在内核中保存有 5 元组(源 ip、源 port、目的 ip、目的端口、UDP 协议),以使得该源端口仅接收目的 ip 和端口发来的 UDP 报文,又可以反复使用 send 方法时比 sendto 每次都上传递目的 ip 和目的 port 两个参数。
对服务器端有以下要求:不要使用 recvfrom 这样的方法,因为该方法无法获取到客户端的发送源 ip 和源 port,这样就无法向客户端发送响应了。应当使用 recvmsg 方法(有些编程语言例如 python2 就没有该方法,但 python3 有)去接收请求,把获取到的对端 ip 和 port 保存下来,而发送响应时可以仍然使用 sendto 方法。
接下来我们谈谈 nginx 如何做 udp 协议的反向代理。Nginx 的 stream 系列模块核心就是在传输层上做反向代理,虽然 TCP 协议的应用场景更多,但 UDP 协议在 Nginx 的角度看来也与 TCP 协议大同小异,比如:nginx 向 upstream 转发请求时仍然是通过 connect 方法得到的 fd 句柄,接收 upstream 的响应时也是通过 fd 调用 recv 方法获取消息;nginx 接收客户端的消息时则是通过上文提到过的 recvmsg 方法,同时把获取到的客户端源 ip 和源 port 保存下来。我们先看下 recvmsg 方法的定义:
ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags);
相对于 recvfrom 方法,多了一个 msghdr 结构体,如下所示:
struct msghdr {
void *msg_name; /* optional address */
socklen_t msg_namelen; /* size of address */
struct iovec *msg_iov; /* scatter/gather array */
size_t msg_iovlen; /* # elements in msg_iov */
void *msg_control; /* ancillary data, see below */
size_t msg_controllen; /* ancillary data buffer len */
int msg_flags; /* flags on received message */
};
其中 msg_name 就是对端的源 IP 和源端口(指向 sockaddr 结构体)。以上是 C 库的定义,其他高级语言类似方法会更简单,例如 python 里的同名方法是这么定义的:
(data, ancdata, msg_flags, address) = socket.recvmsg(bufsize[, ancbufsize[, flags]])
其中返回元组的第 4 个元素就是对端的 ip 和 port。
以上是 nginx 在 udp 反向代理上的工作原理。实际配置则很简单:
# Load balance UDP-based DNS traffic across two servers
stream {
upstream dns_upstreams {
server 192.168.136.130:53;
server 192.168.136.131:53;
}
server {
listen 53 udp;
proxy_pass dns_upstreams;
proxy_timeout 1s;
proxy_responses 1;
error_log logs/dns.log;
}
}
在 listen 配置中的 udp 选项告诉 nginx 这是 udp 反向代理。而 proxy_timeout 和 proxy_responses 则是维持住 udp 会话机制的主要参数。
UDP 协议自身并没有会话保持机制,nginx 于是定义了一个非常简单的维持机制:客户端每发出一个 UDP 报文,通常期待接收回一个报文响应,当然也有可能不响应或者需要多个报文响应一个请求,此时 proxy_responses 可配为其他值。而 proxy_timeout 则规定了在最长的等待时间内没有响应则断开会话。
最后我们来谈一谈经过 nginx 反向代理后,upstream 服务如何才能获取到客户端的地址?如下图所示,nginx 不同于 IP 转发,它事实上建立了新的连接,所以正常情况下 upstream 无法获取到客户端的地址:
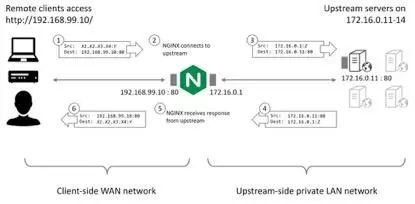
图 4 nginx 反向代理掩盖了客户端的 IP
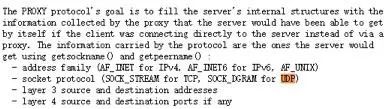
上图虽然是以 TCP/HTTP 举例,但对 UDP 而言也一样。而且,在 HTTP 协议中还可以通过 X-Forwarded-For 头部传递客户端 IP,而 TCP 与 UDP 则不行。Proxy protocol 本是一个好的解决方案,它通过在传输层 header 之上添加一层描述对端的 ip 和 port 来解决问题,例如:

但是,它要求 upstream 上的服务要支持解析 proxy protocol,而这个协议还是有些小众。最关键的是,目前 nginx 对 proxy protocol 的支持则仅止于 tcp 协议,并不支持 udp 协议,我们可以看下其代码:
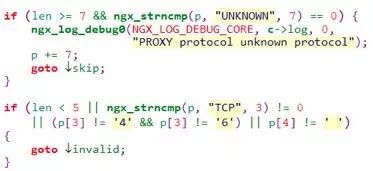
可见 nginx 目前并不支持 udp 协议的 proxy protocol(笔者下的 nginx 版本为 1.13.6)。
虽然 proxy protocol 是支持 udp 协议的。怎么办呢?可以用 IP 地址透传的解决方案。如下图所示:

图 5 nginx 作为四层反向代理向 upstream 展示客户端 ip 时的 ip 透传方案
这里在 nginx 与 upstream 服务间做了一些 hack 的行为:
nginx 向 upstream 发送包时,必须开启 root 权限以修改 ip 包的源地址为 client ip,以让 upstream 上的进程可以直接看到客户端的 IP。
server {
listen 53 udp;
proxy_responses 1;
proxy_timeout 1s;
proxy_bind $remote_addr transparent;
proxy_pass dns_upstreams;
}
upstream 上的路由表需要修改,因为 upstream 是在内网,它的网关是内网网关,并不知道把目的 ip 是 client ip 的包向哪里发。而且,它的源地址端口是 upstream 的,client 也不会认的。所以,需要修改默认网关为 nginx 所在的机器。
# route del default gw 原网关 ip
# route add default gw nginx 的 ip
3. nginx 的机器上必须修改 iptable 以使得 nginx 进程处理目的 ip 是 client 的 报文。
# ip rule add fwmark 1 lookup 100
# ip route add local 0.0.0.0/0 dev lo table 100
# iptables -t mangle -A PREROUTING -p tcp -s 172.16.0.0/28 --sport 80 -j MARK --set-xmark 0x1/0xffffffff
这套方案其实对 TCP 也是适用的。除了上述方案外,还有个 Direct Server Return 方案,即 upstream 回包时 nginx 进程不再介入处理。这种 DSR 方案又分为两种,第 1 种假定 upstream 的机器上没有公网网卡,其解决方案图示如下:
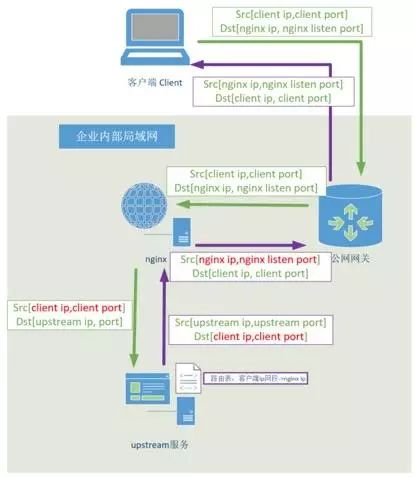
图 6 nginx 做 udp 反向代理时的 DSR 方案(upstream 无公网)
这套方案做了以下 hack 行为:
在 nginx 上同时绑定 client 的源 ip 和端口,因为 upstream 回包后将不再经过 nginx 进程了。同时,proxy_responses 也需要设为 0。
server {
listen 53 udp;
proxy_responses 0;
proxy_bind $remote_addr:$remote_port transparent;
proxy_pass dns_upstreams;
}
2. 与第一种方案相同,修改 upstream 的默认网关为 nginx 所在机器(任何 一台拥有公网的机器都行)。
# tc qdisc add dev eth0 root handle 10: htb
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.11 match ip sport 53 action nat egress 172.16.0.11 192.168.99.10
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.12 match ip sport 53 action nat egress 172.16.0.12 192.168.99.10
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.13 match ip sport 53 action nat egress 172.16.0.13 192.168.99.10
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.14 match ip sport 53 action nat egress 172.16.0.14 192.168.99.10
DSR 的另一套方案是假定 upstream 上有公网线路,这样 upstream 的回包可以直接向 client 发送,如下图所示:
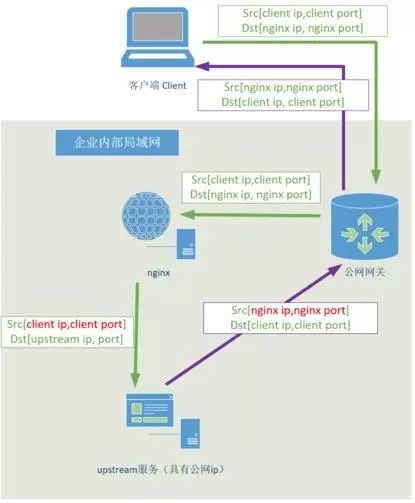
图 6 nginx 做 udp 反向代理时的 DSR 方案(upstream 有公网)
这套 DSR 方案与上一套 DSR 方案的区别在于:由 upstream 服务所在主机上修改发送报文的源地址与源端口为 nginx 的 ip 和监听端口,以使得 client 可以接收到报文。例如:
# tc qdisc add dev eth0 root handle 10: htb
# tc filter add dev eth0 parent 10: protocol ip prio 10 u32 match ip src 172.16.0.11 match ip sport 53 action nat egress 172.16.0.11 192.168.99.10
以上三套方案都需要 nginx 的 worker 跑在 root 权限下,这并不友好。从协议层面,可以期待后续版本支持 proxy protocol 传递 client 的 ip。
活动推荐
随着 AI、Big Data、Cloud 的逐渐成熟,FAAS、CAAS 等技术的兴起,以及被运维业务的多样化和复杂化,很多传统的运维技术和解决方案已经不能满足当前运维所需,AIOps 智能运维、大数据运维、ChatOps、SRE、Chaos Engineering、微服务与容器运维等新技术和方向应运而生,它们一方面把最前沿的技术结合到运维中来,一方面在人员角色、领域范围、文化等方面又有了很多扩展,让传统运维有了翻天覆地的变化。
来 QCon 北京 2018 与国内外一线技术专家探讨运维前沿技术趋势,及其最佳实践和落地方略。目前大会 9 折报名中,立减 680 元。有任何问题欢迎咨询票务经理 Hanna,电话:010-84782011,微信:qcon-0410。









