上一节讲述了真实数据(csv表格数据)训练集的查看与预处理以及Pineline的基本架构。今天接着往下进行实战操作,会用到之前的数据和代码,如果有问题请查看上一节。
三、开始实战
7、选择及训练模型
首先尝试训练一个线性回归模型(LinearRegression)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(train_housing_prepared, train_housing_labels)
训练完成,然后评估模型,计算训练集中的均方误差(RMSE)
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(train_housing_prepared)
lin_mse = mean_squared_error(train_housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse
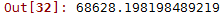
可以看到线性回归模型的训练集均方误差为68626
再试试看更强大的模型,决策树模型(DecisionTreeRegressor)
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor()
tree_reg.fit(train_housing_prepared, train_housing_labels)
housing_predictions = tree_reg.predict(train_housing_prepared)
tree_mse = mean_squared_error(train_housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse

可以看到决策树回归模型的的训练集均方误差竟然为0。比线性回归模型的的训练集均方误差小太多太多。
但这是否说明了决策树回归模型比线性回归模型在此问题上好很多,当然不是,训练误差小的模型并不代表为好模型,这是因为模型可能过度地学习了训练集的数据,只是在训练集上的表现好(即过拟合),一旦测试新的数据表现就会很差。
因此在训练的时候需要将部分的训练数据提取出来作为验证集,验证该模型是否对此问题适用。其中比较常用的就是交叉验证法。
交叉验证法
交叉验证的基本思想是将训练数据集分为k份,每次用k-1份训练模型,用剩余的1份作为验证集。按顺序训练k次后,计算k次的平均误差来评价模型(改变参数后即为另一个模型)的好坏。(具体做法可以看百度百科)

在Scikit-Learn中交叉验证对应的类为cross_val_score,下面是线性回归模型与决策树回归模型的交叉验证实例:
from sklearn.model_selection import cross_val_score
tree_scores = cross_val_score(tree_reg, train_housing_prepared, train_housing_labels,
scoring="neg_mean_squared_error", cv=10)
lin_scores = cross_val_score(lin_reg, train_housing_prepared, train_housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-tree_scores)
lin_rmse_scores = np.sqrt(-lin_scores)
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores)
display_scores(lin_rmse_scores)
其中参数scoring为选择一个指标,代码中选的为均方误差;参数cv是交叉验证划分的个数,这里划为为10份。
需要注意:这里经过交叉验证求均方误差的结果为负值,所以后面求平方根前需要加负号。

可以看到决策树回归模型的交叉验证平均误差为71163,而线性回归模型的交叉验证平均误差为69051,这说明决策树回归模型明显是过拟合,实际上比线性回归模型要差一些。
除了这两个简单的模型以外,还应该试验不同的模型(如随机森林,不同核的SVM,神经网络等),最终选择2-5个候选的模型。(也可以写到同一个文件下,方便以后直接调用)
保存模型
最后介绍一下如何保存模型到本地(硬盘)与重新加载本地模型,可以使用Pickle库,也可以使用scikit-learn中的joblib库,具体代码如下:
from sklearn.externals import joblib
joblib.dump(my_model, "my_model.pkl") #保存模型
# and later...
my_model_loaded = joblib.load("my_model.pkl") #加载模型
8、模型调参
现在已经有一些候选的模型,你需要对模型的参数进行微调,使模型表现的更好。下面介绍几种调参方法
网格搜索(Grid Search)
scikit-learn中提供函数GridSearchCV用于网格搜索调参,网格搜索就是通过自己对模型需要调整的几个参数设定一些可行值,然后Grid Search会排列组合这些参数值,每一种情况都去训练一个模型,经过交叉验证今后输出结果。下面为随机森林回归模型(RandomForestRegression)的一个Grid Search的例子。
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error')
grid_search.fit(train_housing_prepared, train_housing_labels)
例子中首先调第一行的参数为n_estimators和max_features,即有3*4=12种组合,然后再调第二行的参数,即2*3=6种组合,具体参数的代表的意思以后再讲述。总共组合数为12+6=18种组合。每种交叉验证5次,即18*5=90次模型计算,虽然运算量比较大,但运行完后能得到较好的参数。
输出最好的参数
grid_search.best_params_
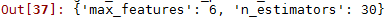
可以看到最好参数中30是选定参数的边缘,所以可以再选更大的数试验,可能会得到更好的模型,还可以在6附近选定参数,也可能会得到更好的模型。
输出最好参数的模型
grid_search.best_params_

也可以看看每一个组合分别的交叉验证的结果
cvres = grid_search.cv_results_
... for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
... print(np.sqrt(-mean_score), params)

随机搜索(Randomized Search)
由于上面的网格搜索搜索空间太大,而机器计算能力不足,则可以通过给参数设定一定的范围,在范围内使用随机搜索选择参数,随机搜索的好处是能在更大的范围内进行搜索,并且可以通过设定迭代次数n_iter,根据机器的计算能力来确定参数组合的个数,是下面给出一个随机搜索的例子。
from sklearn.model_selection import RandomizedSearchCV
param_ran={'n_estimators':range(30,50),'max_features': range(3,8)}
forest_reg = RandomForestRegressor()
random_search = RandomizedSearchCV(forest_reg,param_ran,cv=5,scoring='neg_mean_squared_error',n_iter=10)
random_search.fit(train_housing_prepared, train_housing_labels)
分析最好的模型每个特征的重要性
假设现在调参以后得到最好的参数模型,然后可以查看每个特征对预测结果的贡献程度,根据贡献程度,可以删减减少一些不必要的特征。
feature_importances = grid_search.best_estimator_.feature_importances_
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
cat_one_hot_attribs = list(encoder.classes_)
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)

可以看到ocean_proximity中的4个特征中只有一个特征是有用的,其他3个几乎没有用,所以可以考虑去除其他3个特征。
在测试集中评估
经过努力终于得到了最终的模型,现在就差在测试集上验证这个模型的泛化能力以及准确性。测试集中的操作和训练集中的操作基本相同,唯一不同的是不需要fit(),只需要transform()就可以了,这是因为测试集不是用来训练模型,所以不用fit(),所以将fit_transform()改为transform()。
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
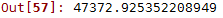
可以发现,结果和交叉验证以后的结果比较相似,说明经过交叉验证后,在新的数据集上也能达到类似的效果。
需要注意:在测试集中补缺失值,标准化等用到的值都是训练集上的中值,平均值等,而不是测试集上的。因为必须把数据放缩到同一尺度。
最后还可以分析这个模型学习到了什么,没做到什么,作出了什么假设,有什么局限性,得到了什么结论(比如median income是最影响结果的)
上一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(二)
下一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(四)










