上一节三节讲述了真实数据(csv表格数据)的一个实战操作的总流程,然而这个处理是一个回归模型,即目标是一些连续的值(median_house_value)。当目标是一些有限的离散值得时候(比如数字0-9),就变成了分类问题,下面开始讲述分类问题。
四、分类问题
下面将使用新的具有代表性的数据集MNIST(手写体数字数据集),数据集总共有70000个小图片,每个小图片为一个手写的数字,(数据中0代表白,1代表黑),数据中把28*28个像素拉成一个向量作为特征,写的数字作为label。
1、关于MNIST数据集
Scikit-learn提供了MNIST数据的下载,如果下载不了也可以自行网站上下载。
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
下载完成后可以输入mnist自行查看一下数据的结构,还可以使用matplotlib输出一张图片看看。
下面需要划分训练集和测试集,MNIST数据集已经帮我们划分好(前60000个为训练集,后10000个位测试集)
X, y = mnist["data"], mnist["target"]
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
虽然MNIST数据集中已经把训练测试集分好,但是还未打乱(shuffle),所以需要对训练集进行打乱。
import numpy as np
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
2、二分类
假设现在分类是否为数字5,则分类两类(是5或不是5),训练一个SGD分类器(该分类器对大规模的数据处理较快)。
#划分数据
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
#训练模型
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
#交叉验证
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
查准率和查全率(Precision and Recall)以及F1指标
与回归问题计算损失函数不同,二分类特有的一种评价指标为查准率和查全率(Precision and Recall)以及F1指标。
Precision就是预测为正类的样本有多少比例的样本是真的正类,TP/(TP+FP);Recall就是所有真正的正类样本有多少比例被预测为正类,TP/(TP+FN)。其中TP为真正类被预测为正类,FP为负类被预测为正类,FN为真正类被预测为负类。Scikit-learn也有对应的函数
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_5, y_train_pred)
recall_score(y_train_5, y_train_pred)
由于Precision和Recall有两个数,如果一大一下的话不好比较两个模型的好坏,F1指标就是结合两者,求调和平均
F1=2∗Precision∗RecallPrecision+Recall
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)
对于F1值,暗含了Precision和Recall是同等重要的,然而对于现实问题并不一定同等重要,比如推荐电影,给观众推荐一部很好的电影比很多电影更重要,因此Precision更加重要;而对于检查安全问题,宁可多次去核查也不能出现一点错误,因此Recall更重要。所以对于实际问题,应该适当权衡Precision和Recall。
Precision/Recall 的权衡
虽然我们没有办法改变Scikit-learn里面的predict()函数来改变分类输出,但我们能够通过decision_function()方法来得到输出的得分情况,得分越高意味着越有把握分为这一类。因此可以通过对得分设一个界(threshold),得分大于threshod的分为正类,否则为负类,以此来调整Precision和Recall。
然而这个threhold应该怎么确定,scikit-learn中提供相关的函数precision_recall_curve()来帮助我们确定。
需要注意:cross_val_predict计算交叉验证后验证集部分的得分(而不是类别)。
#计算得分
from sklearn.model_selection import cross_val_predict
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")
#调用precision_recall_curve
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
需要注意:得出的结果precisions和recalls的元素个数比threholds多一个,因此画图时需要回退一个。
将结果通过图展示出来
import matplotlib.pyplot as plt
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision")
plt.plot(thresholds, recalls[:-1], "g-", label="Recall")
plt.xlabel("Threshold")
plt.legend(loc="upper left")
plt.ylim([0, 1])
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.show()
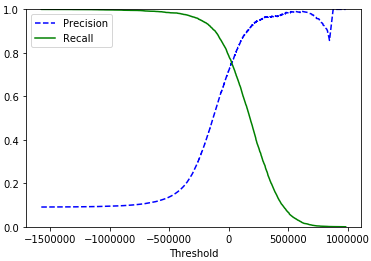
观察图,按需要选择合适的Threshold。
3、多分类
对于随机森林分类器(Random Forest classifiers)和朴素贝叶斯分类器(naive Bayes classifiers),本来就能够处理多分类的问题。但是有一些算法如支撑向量机(Support Vector Machine classifier)和线性分类器(Linear classifiers)就是二分类器。将二分类器扩展到多分类器一般有两种做法。
1、OVA(one-versus-all):比如分类数字(0-9),则训练10个分类器(是否为0的分类器,是否为1的分类器.,…,是否为9的分类器),每一个分类器最后会算出一个得分,判定为最高分的那一类
2、OVO(one-versus-one):每个类之间训练一个分类器(比如0和1训练一个分类器,1-3训练一个分类器),这样总共有N*(N-1)/2个分类器,哪个类得分最高判定为那一类。
一般情况下,OVO训练速度比较快(因为训练多个小分类器比训练一个大分类器时间要快),而OVA的表现会更好,因此Scikit-learn中二分类器进行多分类默认为OVA,除了支撑向量机使用OVO以外(由于支撑向量机对大规模的数据表现不好)
下面是一个二分类器SGD分类器扩展为多分类器用作数字分类的例子
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train)
可以随便取一个数据看看得分情况
some_digit = X[36000]
sgd_clf.predict([some_digit])
some_digit_scores = sgd_clf.decision_function([some_digit])

可以看到第6个分数(代表数字5)最高,即分类为数字5。
这是OVA的情况,也可以强制变为OVO(OVA)的情况OneVsOneClassifier(OneVsRestClassifier)
4、评价分类器的好坏
对于回归任务,上一节评价模型的好坏用的是交叉验证法,对于分类任务,同样也可以采取交叉验证法,不同的是,误差不是均方误差,而是准确率(或者交叉熵)。和之前交叉验证的函数相同为cross_val_score,不过scoring为accuracy。
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
结果为:
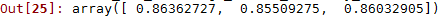
可以看到准确率大概在86%,当然也可以采用预处理(标准化)来增加准确率。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
结果为:
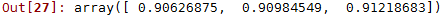
可以看到经过标准化后准确率上升到了90%
5、错误分析
当然,如果这是一个真正的项目,还需要尝试多个模型,选择最佳模型并微调超参数,现在假设已经找到了这个模型,并想进一步提升,其中一种方法是分析错误的类型是哪些。
混淆矩阵法
首先要使用cross_val_predict计算交叉验证后验证集部分的预测分类结果(而不是正确率),然后根据真正的标签和预测结果对比,画出混淆矩阵(如下图),第 i 行第 j 列的数字代表数字 i 被预测为数字 j 的个数总和,比如第5行第一个数表示数字4被误判为0的次数为75;对角线上即为正确分类的次数。
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx

然而矩阵中数据太多很复杂,所以可以通过图更加直观地表示出来
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()
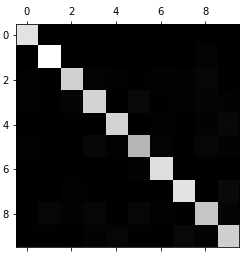
从图中可以看到分类结果表现的还好,数字5比较暗,说明数字5被错分的比较多。
还可以去除正确的对角线的分布情况,只看错误的分布
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums.astype(np.float64)
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()
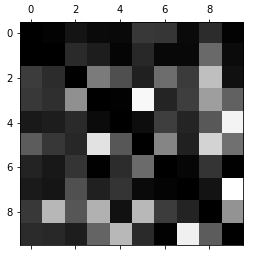
可以看到第6行第4列与第4行第6列种比较白,说明5错分为3,3错分为5的次数比较多。因此还可以把错误分为3和5的样本提取出来观察分析,从而改进算法。
6、多标签分类(Multilabel Classification)
直到现在的例子都是将数据分为某一类,但有些时候想分为多个类(比如人脸识别分类器,如果一张图片上有多个人脸,那就不能只识别一个人,而是要识别出多个人),输出比如为[1,0,1],则分为1和3类。对于这种输出多个二值分类标签的就是多标签分类。下面是一个简单的例子:
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
knn_clf.predict([some_digit])
例子中的任务是:分类数据 是否大于等于7 以及 是否为奇数 这2个标签,使用k-近邻分类器(KNN)进行多标签分类(不是所有的分类器都能进行多标签分类)。
评价多标签分类模型的方法可以对每种标签求F1值,再求平均值。
7、多输出分类(Multioutput Classification)
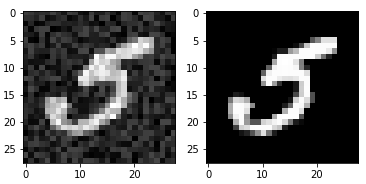
多输出分类是多标签分类更一般的一种形式,比如现在图像有噪声,需要将每个像素分类为0或1已达到去噪的目的(也可以多个标签)。下面就是一个例子,如下图,左图为的像素为特征,右图为标签。
#生成左边的噪声图
import numpy.random as rnd
noise1 = rnd.randint(0, 100, (len(X_train), 784))
noise2 = rnd.randint(0, 100, (len(X_test), 784))
X_train_mod = X_train + noise1
X_test_mod = X_test + noise2
y_train_mod = X_train
y_test_mod = X_test
import matplotlib.pyplot as plt
plt.subplot(1,2,1)
plt.imshow(X_train_mod[36000].reshape(28,28),cmap=plt.cm.gray)
plt.subplot(1,2,2)
plt.imshow(X_train[36000].reshape(28,28),cmap=plt.cm.gray)
接下来训练一个KNN模型实现多输出分类(去噪)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_train_mod[36000]])
plt.imshow(clean_digit.reshape(28,28),cmap=plt.cm.gray)
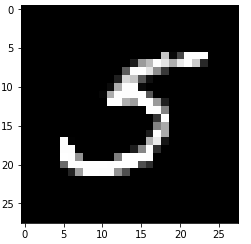
可以看到训练的模型能够对每个像素进行分类,从而实现去噪。
上一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(三)
下一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(五)









