最近就有一部“怀旧”题材的电影,未播先火,那就是刘若英的处女作——《后来的我们》。青春,爱情,梦想,一直是“怀旧”题材的核心要素,虽然电影现在还未上映,但先行发布的主题曲《我们》,已经虐哭了不少人。在MV里,歌声清清浅浅,诉说着那些年关于爱情里的遗憾。
“我最大的遗憾,就是你的遗憾,与我有关”,下面就一起来感受一下吧。
这首歌是《后来的我们》中的主题曲,网易云音乐上线当天便席卷千万+播放量,现如今光是网易云上面的评论就马上突破了10万条。
网易云音乐一直是我向往的“神坛“,听音乐看到走心的评论的那一刻,高山流水。于是来抓取一下歌曲的热门评论。并做成图表、词云来展示,看看相对于这首歌最让人有感受的评论内容是什么。
一、抓数据
要想做成词云图表,首先得有数据才行。于是需要一点点的爬虫技巧。
基本思路为:抓包分析、加密信息处理、抓取热门评论信息
1.抓包分析
我们首先用浏览器打开网易云音乐的网页版,进入陈奕迅《我们》歌曲页面,可以看到下面有评论。接着F12进入开发者控制台(审查元素)。
接下来就要做的是,找到歌曲评论对应的url,并分析验证其数据跟网页现实的数据是否吻合,步骤如下图:

通过歌曲id轻松找到评论所在的链接
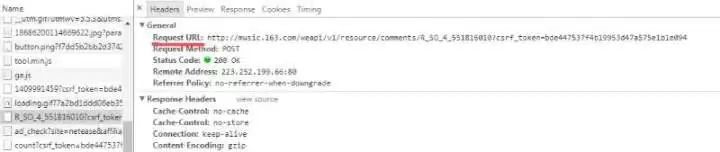
查看hreaders的信息,发现浏览器使用的是POST的方式进行的请求
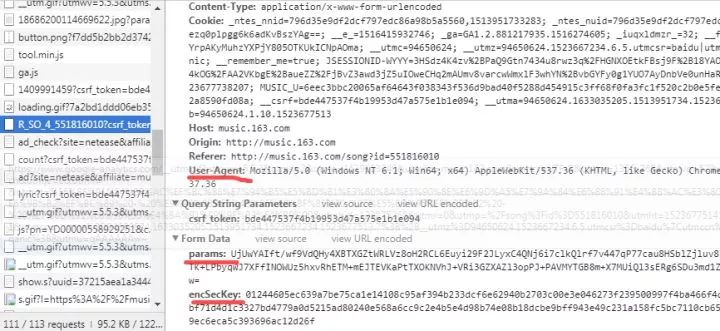
具体字段如上图,会发现表单中需要填两个数据,名称为params和encSecKey。后面紧跟的是一大串字符,换几首歌会发现,每首歌的params和encSecKey都是不一样的,因此,这两个数据可能经过一个特定的算法进行加密过的
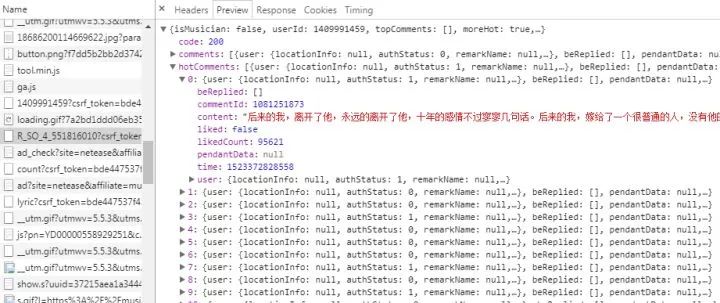
服务器返回的和评论相关的数据为json格式的,里面含有非常丰富的信息(比如有关评论者的信息,评论日期,点赞数,评论内容等等),其中hotComments就是我们要找的热门评论,总共15条
那我们的思路就很清晰了,只需要分析这个api并模拟发送请求,获取json进行解析就好了。
2.加密信息处理
然后经过我的测试,直接把浏览器上这俩数据拿过来就可以。但是要想真正的解决这个加密处理,还需要有点加解密的只是存储。
我们在这里就只需要用我们这种偷懒的办法就可以完成需求了。这里我就使用这么个临时的方法好了,而且对于不同的歌曲是可以重用的,待会我们可以验证一下。
3.抓取热门评论信息
代码块如下:
import requests
import json
url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_551816010?csrf_token=568cec564ccadb5f1b29311ece2288f1'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'Referer':'http://music.163.com/song?id=551816010',
'Origin':
'http://music.163.com',
'Host':'music.163.com'
}
#加密数据,直接拿过来用
user_data = {
'params': 'vRlMDmFsdQgApSPW3Fuh93jGTi/ZN2hZ2MhdqMB503TZaIWYWujKWM4hAJnKoPdV7vMXi5GZX6iOa1aljfQwxnKsNT+5/uJKuxosmdhdBQxvX/uwXSOVdT+0RFcnSPtv',
'encSecKey': '46fddcef9ca665289ff5a8888aa2d3b0490e94ccffe48332eca2d2a775ee932624afea7e95f321d8565fd9101a8fbc5a9cadbe07daa61a27d18e4eb214ff83ad301255722b154f3c1dd1364570c60e3f003e15515de7c6ede0ca6ca255e8e39788c2f72877f64bc68d29fac51d33103c181cad6b0a297fe13cd55aa67333e3e5'
}
response = requests.post(
url,headers=headers,data=user_data)
data = json.loads(response.text)
hotcomments = []
for hotcommment in data['hotComments']:
item = {
'nickname':hotcommment['user'][
'nickname'],
'content':hotcommment['content'],
'likedCount':hotcommment['likedCount']
}
hotcomments.append(item)
#获取评论用户名,内容,以及对应的获赞数
content_list = [content['content'] for content in
hotcomments]
nickname = [content['nickname'] for content in hotcomments]
liked_count = [content['likedCount'] for content in hotcomments]
二、数据可视化
在获得相关评论数据后,我们将其做成图表与词云图,将让人看起来更直观。
接下来需要在自己电脑上安装需要相关的安装包: pyecharts(图表包)、matplotlib(绘图功能包)、 WordCloud(词云包)
其中,pyecharts 是一个用于生成 Echarts 图表的类库。 Echarts 是百度开源的一个数据可视化 JS 库,主要用于数据可视化,同时pyecharts 兼容 Python2 和 Python3。安装非常简单,只需:
pip install pyecharts
接下来就是代码的实现:
利用之前获得评论用户名和对应的点赞数,将其制作成图表图:
from pyecharts
import Bar
bar = Bar("热评中点赞数示例图")
bar.add( "点赞数",nickname, liked_count, is_stack=True,mark_line=["min", "max"],mark_point=["average"])
bar.render()
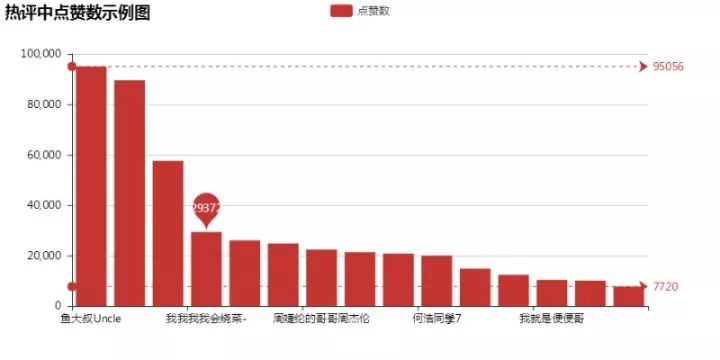
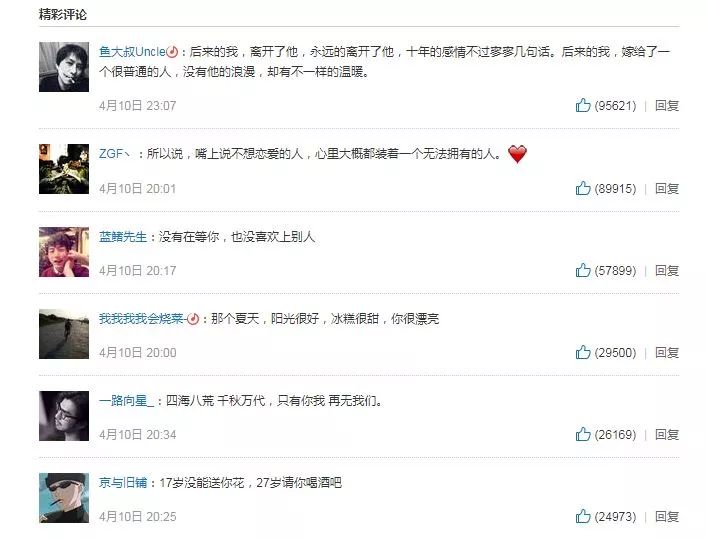
由此可以看出,获得最高赞数(95056)评论是:
@鱼大叔Uncle:后来的我,离开了他,永远的离开了他,十年的感情不过寥寥几句话。后来的我,嫁给了一个很普通的人,没有他的浪漫,却有不一样的温暖。
大多数赞数为20000-30000之间,最低都达到7000+,(基本与网页里评论中数据吻合)。
最后,我们将所有的热门评论内容,制作成词云图展示出来,代码块如下:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
content_text = " ".join(content_list)
wordcloud = WordCloud(font_path=r"C:\simhei.ttf",max_words=200).generate(content_text)
plt.figure
()
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis('off')
plt.show()
结果图:

从图中可以看出,很多人感慨,后来只有你我,再无我们。
注明:所有数据,是属于当时所爬取的数据。
三、后记
曾记得,郭敬明在书里写,“我们太年轻,以致于都不知道以后的时光,竟然那么长,
长得足够让我忘记你,足够让我重新喜欢一个人,就像当初喜欢你那样。”
我们这一生,总是遇到太多的后来。从不懂爱到懂爱,从拥有到珍惜。
所幸是到了最后,无论过了多少年。后来的我们,都在对方身上,学会了如何去爱。

就像陈奕迅在歌里唱的,“有过执着,放下执着”。有些人啊,光是遇见就已经值得了。
我们确实没有了后来。
就让后来的我们,慢慢走,别回头。
不谈亏欠,感谢遇见。
只是在下一次遇见爱的时候,我们都要学会更懂得珍惜。
这才是爱的意义,也是我们为什么去爱。
赞赏作者

作者:菜鸟分析,一个痴恋于Python语言的程序猿
知乎专栏|恋习Python:https://zhuanlan.zhihu.com/p/35667053
最近热门文章
用Python分析苹果公司股价数据
Nginx+uwsgi部署Django应用
用文本挖掘剖析近5万首《全唐诗》
Python自然语言处理分析倚天屠龙记
Python 3.6实现单博主微博文本、图片及热评爬取

▼ 点击下方阅读原文,免费成为社区会员







