作者有话说:
1、本文虽然是一篇技术性文章,但是分析的数据可以给喜欢看小说的人提供参考
2、本文涉及的是Python爬虫精进的知识
3、作者想通过分享,让许多正在学习Python爬虫的提供帮助。
4、如果你对代码很反感,那就直接看数据分析吧!
5、文章若有不足之处,请指教。可以在评论区自由发表观点以及提出问题,作者会及时回应。
一、小说数据的获取
获取的数据为起点中文网的小说推荐周榜的所有小说信息。
网址为:
https://www.qidian.com/rank/recom
源代码对所有想要获取的数据都有注释。
"""
Created on Mon Jan 4 22:59:11 2021
"""
import requests
from bs4 import BeautifulSoup
import os.path
import csv
import time
import pymysql
import random
class DrawBookMessage():
def __init__(self):
"""
定义构造函数,初始化最初网址,方便后面调用,不必重复写
"""
self.baseUrl='https://www.qidian.com/rank/recom';
def User_Agent(self):
"""
定义5个代理IP隐藏身份,用5个IP随机选取,以防止被检测到链接对象而终止访问
"""
user_agent1 = 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0'
user_agent2 = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
user_agent3 ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
user_agent5 ='Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3'
lst = [user_agent1,user_agent2,user_agent3,user_agent5]
return random.choice(lst)
def getHtml(self,url):
"""
通过随机IP访问网页获取网页的内容
"""
user_agent = self.User_Agent()
headers = {"User-Agent":user_agent}
request = requests.get(url,headers=headers).text
return request
def commonsdk(self,url):
"""
把文本类型转换为<class 'bs4.BeautifulSoup'>类型,
之后还会用BeautifulSoup库来提取数据,如果这不是一个BeautifulSoup对象,
我们是没法调用相关的属性和方法的,所以,这是非常重要。
"""
html = self.getHtml(url)
doc=BeautifulSoup(html,'lxml')
return doc
def get_page_size(self,url):
'''获取页面总数'''
doc = self.commonsdk(url)
self.pageNum = doc.find("div",class_="pagination fr")['data-pagemax']
return int(self.pageNum)
def draw_base_list(self,url):
'''初级网页内容'''
doc = self.commonsdk(url)
listt=doc.find('div',class_ = "book-img-text").find_all('div',class_ = 'book-mid-info')
for x in listt:
self.bookName = x.find('h4').text.strip()
self.bookUrl ='https:'+x.find('h4').find('a')['href']
self.bookAuthor = x.find('p').find(class_='name').text.strip()
self.bookType = x.find('p').find('a',class_='').text.strip()
self.bookStatus = x.find('p').find('span').text.strip()
self.draw_Second_list()
self.dict_data()
def draw_Second_list(self):
'''获取二级网页内容'''
doc = self.commonsdk(self.bookUrl)
listt1 = doc.find('div',class_="book-info")
self.bookIntrodaction = listt1.find(class_="intro").text.strip()
listt2 = doc.find(class_="fans-interact cf")
if listt2.find(class_ ='ticket rec-ticket')==None:
self. monthTickets = listt2.find(class_ ='ticket month-ticket').find(class_ = 'num').text
self. weekTickets = listt2.find(class_ ='ticket rec-ticket hidden').find(class_ = 'num').text
if listt2.find(class_ ='ticket rec-ticket hidden')==None:
self. monthTickets=0
self. weekTickets = listt2.find(class_ ='ticket rec-ticket').find(class_ = 'num').text
self.weekWardNum = listt2.find(class_= 'rewardNum').text
def dict_data(self):
"""
定义一个人方法生成需要存入数据的字典
"""
ctime = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime());
data={
'书名':self.bookName
,
'作者':self.bookAuthor,
'类型':self.bookType,
'状态':self.bookStatus,
'月票':int(self. monthTickets),
'周票':int(self.weekTickets),
'本周打赏人数':int(self.weekWardNum),
'本书简介':self.bookIntrodaction,
'爬取时间':ctime
}
print(data)
print("="*50)
self.write_to_MySQL(data,"spiders","bookMessage")
self.write_to_scv(data,'bookMessage.csv')
pass
def write_to_scv(self,dic,filename):
"""写入csv文件"""
file_exists = os.path.isfile(filename)
with open(filename, 'a',encoding='gb18030',newline='') as f:
headers=dic.keys()
w =csv.DictWriter(f,delimiter=',',lineterminator='\n',fieldnames=headers)
if not file_exists :
w.writeheader()
w.writerow(dic)
print('当前行写入csv成功!')
pass
def write_to_MySQL(self,dic,database,table_name):
""" 写入数据库"""
keys = ', '.join(dic.keys())
values = ', '.join(['% s'] * len(dic))
db = pymysql.connect(host='localhost', user='root', password=(自己的数据库密码), port=3306, db=database)
cursor = db.cursor()
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table_name, keys=keys, values=values)
try:
if cursor.execute(sql, tuple(dic.values())):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
cursor.close()
db.close()
if __name__ == '__main__':
"""主函数"""
drawBook = DrawBookMessage()
page = drawBook.get_page_size(drawBook.baseUrl)
for x in range(1,page+1):
drawBook.draw_base_list(drawBook.baseUrl+'?page='+str(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
-
27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
看到这里不知道是否对你有所帮助?看不懂的可以评论区留言,顺便点个赞。嘻嘻嘻嘻嘻嘻!

二、数据的分析与可视化
相信大家对pandas都有了解吧,我就直入主题——数据分析。
2.1、Python读取数据表时,有时候会发生一个很顽固的错误

在这里一般性如果表中有中文的话,读表的时候就会报这个错误,这里把默认编码改为gbk一般就能解决这个问题。即encoding=‘gbk’。
2.2、查看表的统计信息
(1)describe()查看表的相关信息信息
data.describe()
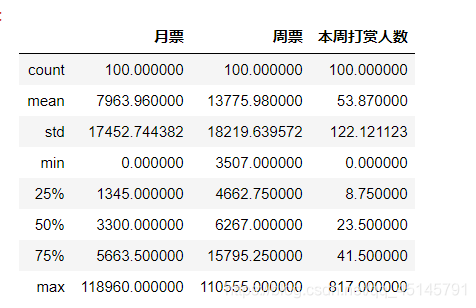
通过这个结果可以得出各票数的情况和打赏的人数。
(2)根据周票数对小说排序
我们通过排序可以筛选出周票数前5的小说
data.sort_values(by = '周票',ascending = False).head(5)
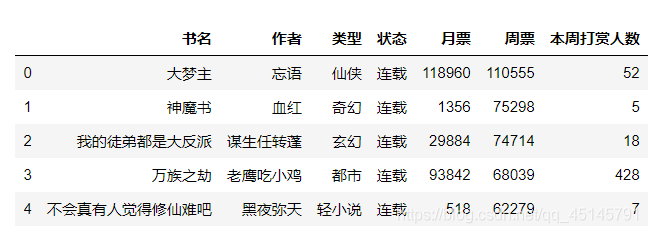
可以知道当前这5本小说人气很高。很多人还喜欢看完结的小说,毕竟一次性看完的感觉特别爽。我们也把几本完结的小说获取出来
data.
loc[data['状态']=='完本'].sort_values(by = '周票',ascending = False)

可以得出最近100流行小说中只有2本是完结的。
2.3可视化图分析
(1)折线图
对于读者,都有不同的喜好都市、有的喜好玄幻、有的喜欢轻小说……让我们看一下最近这些小说各票数综合情况。通过下面打代码可以得出折线图情况。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
y1 = data.groupby('类型').sum()['本周打赏人数']
y2 = data.groupby('类型').mean()['周票']
y3 = data.groupby('类型').mean()['月票']
x=list(dict(y1).keys())
fig = plt.figure(figsize=(8,6), dpi=100)
plt.plot(x,y1,c='red',label='打赏票和')指定折线的颜色和标签
plt.plot(x,y2,c='green',label='周票均值')
plt.plot(x,y3,c='blue',label='月票均值')
plt.legend(loc='upper left')
plt.ylabel('周票平局值、月票平局值、打赏票和',fontsize=15)改变定横坐标名称以及字体大小。
plt.title("小说票数折线图")
plt.xlabel('小说类型',fontsize=15)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
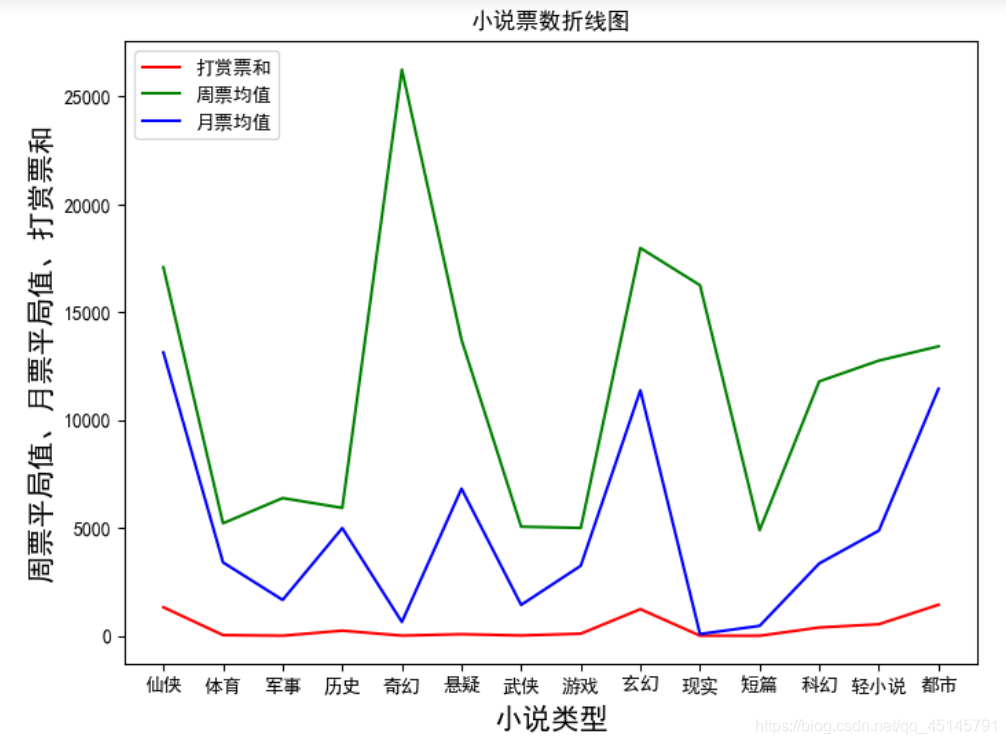
通过折线图可以直观的看书流行的趋势,可以分析到奇幻小说最受欢迎,读者最多。
(2)柱状图
在这里插入代码片plt.
rcParams['figure.figsize']=(8,3)
data.groupby(['类型']).mean().plot(kind = 'bar')
plt.xticks(rotation=0)
plt.ylabel('number of people',fontsize = 15)
plt.xlabel('Date',fontsize = 15)
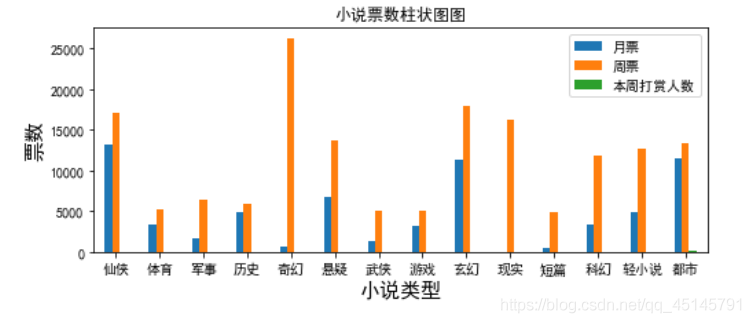
柱状图可以出月票、周票、以及打赏人数没有很直接的关系。比如奇幻周票高,但是其他两项的票数却非常低。
(3)饼状图
sizes = []
for booktype in x:
bookTypeNum=len(data[data['类型']==booktype])
sizes.append(bookTypeNum)
plt.figure(figsize=(10,15))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.pie(
sizes,
labels=x,
autopct='%1.1f%%'
)
plt.title('小说类型受欢迎的分布图比')
plt.legend(loc='upper left')
plt.show()
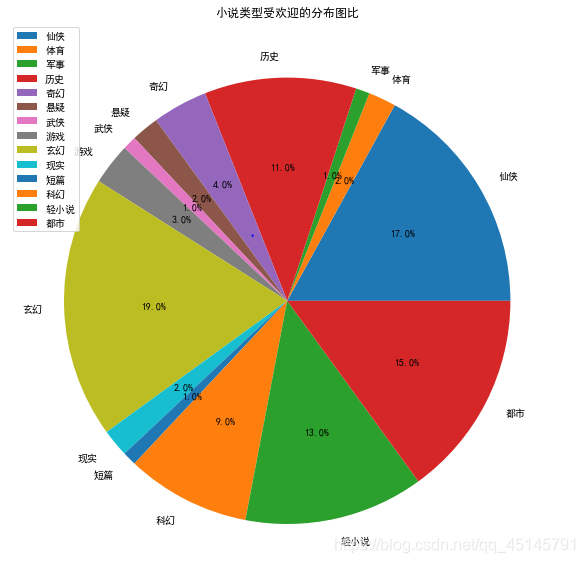
通过饼状图可以得出奇幻、都市、仙侠、轻小说几类小说很受大家追捧。
(4)词云图
import jieba
import wordcloud
string = ''
for i in range(len(x)):
string = str + (x[i])*int(sizes[i])
print(string)string=' '.join(string)
w = wordcloud.WordCloud(background_color='white',
font_path='simfang.ttf')
w.generate(string)
w.to_file(r"bookMessage.png")

根据词云的字的大小可以看出当下最受大家追捧的小说的类型。
(5)散点图
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['figure.figsize']=(12,8)
np.random.seed(0)
colors = np.random.rand(100)
size = np.random.rand(20)*1000
plt.scatter(a,b,c=colors,s=size,alpha=0.7,marker='*')
plt.xlabel('月票数',fontsize = 15)
plt.ylabel('周票数',fontsize = 15)
plt.title("月票和周票散点图")
plt.show()
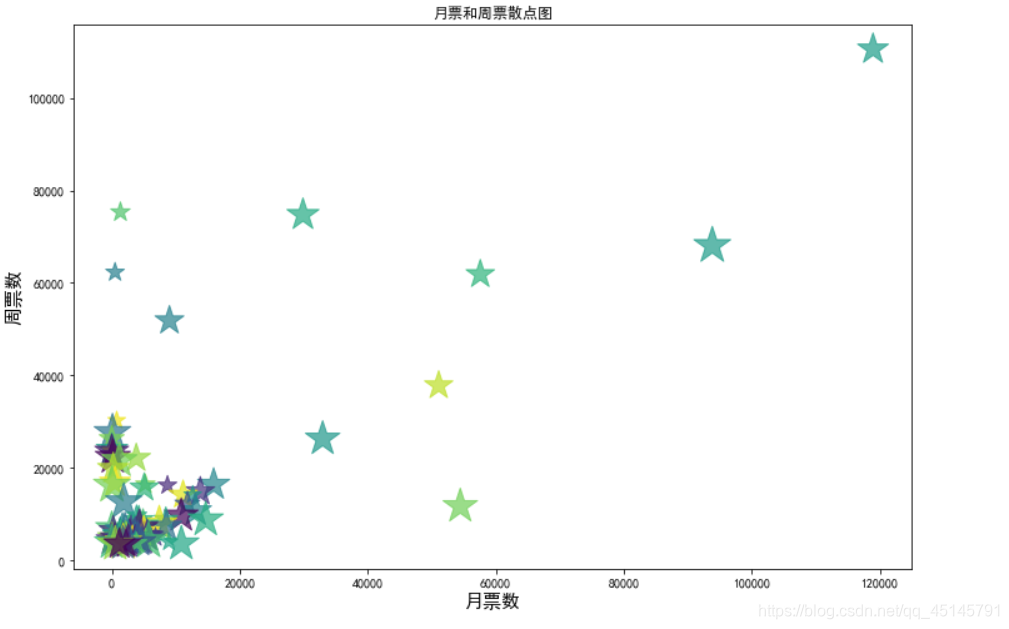
通过散点图可以得出大部分小说的月票和周票的数目很少,只有少数的小说月票和周票数目多。往往这些小说就是当下最火的小说。
结语:
本文到此结束,不知道屏幕前的你,有收获了吗?
你看过那些很火的小说呢?
你有哪些知识点看不懂或者需要帮助?
或者你只是路过,但相遇即是缘,不妨留下你的足迹哦!
欢迎留言点赞与我一起讨论,我在世界的另一端等你哦!让我们一起共同进步
。











