
Gary Marcus 并不缺乏野心,他决意要重新启动人工智能。 本文最初发表于 ZDNet,经原作者 George Anadiotis 授权,InfoQ 中文站翻译并分享。
Gary Marcus,这位人工智能领域的著名人物,正肩负着使命,给这门他认为有停滞风险的学科注入新鲜空气。知识图谱,这个炒过 20 年的老古董,或许在那儿能有一番作为。
“这就是我们需要做的事情。虽然现在不流行,但这就是为什么流行的东西不起作用” ,这是对科学家、畅销书作家、企业家 Gary Marcus 多年来一直在说的话的一种粗略的过度简化,不过至少他本人是这么说的。
所谓“流行的东西不起作用”部分指的是深度学习,而“我们需要做什么”部分指的是对人工智能采取更全面的方法。Marcus 并不缺乏野心。他决意要重新启动人工智能。而且他也不缺资历。从孩提时代起,他就或多或少地致力于探索智能的本质,无论是人工智能还是其他智能。
由于深度学习被视为目前人工智能领域最成功的子领域,对深度学习的质疑可能听起来颇具争议。Marcus 的批评始终如一。他已经发表了一些文章,强调了深度学习是如何失败的,GPT-2、Meena 和 GPT-3 等语言模型就是例证。
Marcus 最近发表了一篇长达 60 页的论文,题为《人工智能的下一个十年:迈向强人工智能的四个步骤》(The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence)。在这篇论文中,Marcus 超越了批评,提出了推动人工智能向前发展的具体建议。
ZDNet 对 Marcus 进行了广泛的主题采访,这是 Marcus 即将在 Knowledge Connexions 上进行的关于人工智能未来的主题演讲的前奏。从我们在采访的第一部分结束的地方开始,今天我们将详细介绍具体的方法和技术。
最近,深度学习的开拓者之一,Geoff Hinton 声称,深度学习能够完成任何事情。但 Marcus 认为,取得进展的唯一途径是将已经存在的“积木”组合在一起,但目前还没有一个将现有的人工智能系统组合在一起的系统。
构建块 1:与经典人工智能世界的联结。Marcus 并不是建议放弃深度学习,而是将其与经典人工智能的一些工具结合起来。经典人工智能擅长表示抽象知识,表示句子或抽象。目标是拥有一个能够使用感知信息的混合系统。
构建块 2:我们需要有丰富的知识具体化方式,我们需要大规模的知识。我们的世界充满了大量的知识碎片。大多数深度学习系统不是这样的。大多数情况下,它们只是充满了特定事物之间的相关性。因此,我们需要大量的知识。
构建块 3:我们需要能够对这些事情进行推理。假设我们对物理对象及其在世界中的位置有所了解,例如,杯子。这个杯子里有铅笔。然后,人工智能系统还需要能够意识到,如果我们在杯底挖一个洞,铅笔就会掉出来。人类一直进行这样的推理,但是目前的人工智能系统却无法做到这点。
构建块 4:我们需要认知模型:我们大脑内部或计算机内部的事物,这些事物可以告诉我们世界上所见的实体之间的关系。Marcus 指出,某些系统有时可以做到这一点,以及为什么它们能作出比深度学习单独作出的推论更复杂的推论。
在我们看来,这是一个全面的建议。但是,也有一些人提出了反对意见,其中不乏像 Yoshua Bengio 这样的人。Yoshua Bengio、Geoff Hinton 和 Yan LeCun 被认为是深度学习的鼻祖,最近他们三人获得了图灵奖。
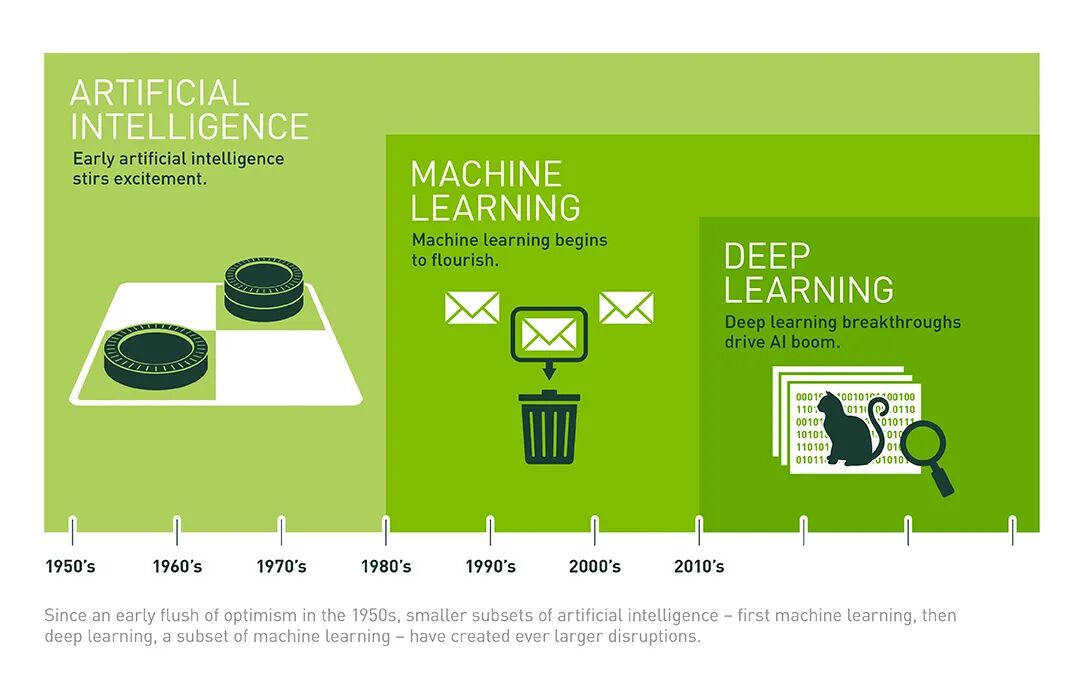
人工智能不仅仅是机器学习,机器学习也不仅仅是深度学习。Gary Marcus 主张对人工智能采取一种混合方法,并将其与根源重新连接起来。图片来源:NVIDIA。
Bengio 和 Marcus 展开了一场辩论,在辩论中,Bengio 承认了 Marcus 的某些观点,但他也清楚地表明自己的立场,并与 Marcus 划清界限。Marcus 提到,他发现 Bengio 早期关于深度学习的研究工作“更偏向于炒作”:
我认为 Bengio 的观点是,如果有足够的数据,我们就能解决所有的问题。但他现在发现事实并非如此。事实上,他的言辞已经软化了不少。他承认有太多的炒作,他也承认我长期以来一直指出的泛化的局限性—— 尽管他没有将这归咎于我。所以他认识到了一些局限性。
不过,在这一点上,我觉得我和他仍然有很大的不同。我们说的是,在一个系统中,你需要先天建立哪些东西。这样就会有很多的知识。但并非所有的知识都会是天生的。很多知识是后天习得的,但也可能有一些核心知识是天生的。而他愿意承认一件特别的事情,因为他说,好吧,那只是四行计算机代码而已。他没有完全划清界限,说什么也不超过五行。但是他说,很难对所有这些东西进行编码。我认为这是愚蠢的。我们现在有几千兆字节的内存,而且不花钱。所以你可以很容易地容纳物理存储。这其实是一个构建和调试,以及获得适当数量的代码的问题。
Marcus 接着提出了一个比喻。他说,基因组是一种编码,经过 10 亿年的进化,大脑在没有蓝图的情况下自主构建而成,他还补充说,这是一个非常复杂的系统,他在一本名为《心智的诞生》(The Birth of the Mind)的书中写道。在这个基因组中,有足够的空间可以掌握世界的一些基本知识。
这是显而易见的,Marcus 认为,通过观察我们所说的社会性动物,比如一匹马,刚站起来就会开始走路;或者一只山羊,当它几小时大的时候,就会从山坡上爬下来。必须有一些先天知识在那里,关于视觉世界的样子,以及如何解释它,力如何作用于你自己的肢体,以及如何与平衡有关,等等。
这就是为什么人类基因组中的代码远远不止四行。Marcus 认为,随着大脑的发育,我们的基因组大部分都是在大脑中表达的。所以,我们的很多 DNA 其实是为了在我们的大脑中建立强大的起点,从而使我们能够积累更多的知识:
这不是先天和后天的关系。就像你拥有的先天性越多,那么你拥有的后天性就越少。而且这也不是说只有一个“赢家”。实际上,这是先天和后天共同作用的结果。你积累的知识越多,就越容易了解这个世界。

探讨智能,无论是人工智能还是其他智能,几乎不可避免地会涉及到哲学问题。先天性假说是指某些原语,如语言,是否建立在智能因素之中。
Marcus 关于有足够的存储空间的观点引起了我们的共鸣,关于在其中加入知识的部分也是如此。毕竟,越来越多的人工智能专家都承认这一点。我们认为,难点并不在于如何存储这些知识,而在于如何对其进行编码、连接,并使其可用。
这就把我们带到了一个非常有趣的,也是被大肆宣传的点子 / 技术:知识图谱。术语“知识图谱”本质上是一种旧方法的重新命名:语义网。知识图谱现在可能会被炒作,但是如果有,那也是 20 年前的炒作了。
语义网是由 Tim Berners Lee 爵士创建的,旨在将符号化的人工智能方法引入 Web:分布式、去中心化和规模化。它的一部分运作良好,另一些则不是那么好。它经历了自己的幻灭低谷,现在它看到了自己的平反,其形式是 schema.org 占领了 Web,知识图谱被大肆宣传。但最重要的是,知识图谱正在看到被现实世界所接受。Marcus 确实在他的《人工智能的下一个十年》论文中提到了知识图谱,这对我们来说是一个引爆点。
Marcus 承认,要实现他的方法,还需要解决一些实际问题,需要做很多工作,才能很好地约束符号搜索,使其能够对复杂问题进行实时处理。但他认为,Google 的知识图谱至少是这种反对意见的部分反例。
当被问及是否认为知识图谱能够在他所倡导的混合方法中发挥作用时,Marcus 持肯定态度。他说,一种思考方式是,有大量的知识在互联网上表达出来,这些知识基本上是免费提供的,当前的人工智能系统并没有使用到它们。但其中许多知识都存在着问题:
世界上大部分的知识在某种程度上都是不完美的。但是,如果存在大量的知识,比如说,一个聪明的 10 岁孩子就可以免费习得,那么我们应该让 RDF(Resource Description Framework,资源描述框架)能够做到这一点。
一些例子是,首先是 Wikipedia,它说明了许多关于这个世界是如何运作的。而如果你有人类那样的大脑,你就能读懂它,并从中学到很多东西。如果你是一个深度学习系统,那么你就什么也得不到,或者几乎什么都得不到。Wikipedia 就是房子前面的东西。在房子的后面,是像语义网这样的东西,给网页贴上标签,供其他机器使用。那里也有各种各样的知识,但目前的做法都是将它束之高阁了。我们必须开发出能够使用人类集体知识的人工智能系统,这些知识以语言形式表达,而不仅仅是一个电子表格,这样才能真正进步,才能制造出最复杂的系统。
以知识图谱为例,混合和匹配深度学习和知识表征的人工智能方法,可能是最好的发展方向。
Marcus 接着补充说,对于语义网来说,要让人们参与其中,并对此保持一致,比预期的要困难得多。但这并不意味着这种方法没有价值,也不意味着使知识显性化。它只是意味着我们需要更好的工具来利用它。这是我们可以订阅的东西,也是许多人所关注的东西。
很明显,我们不能期望人们手动注释使用 RDF 词汇表发布的每一段内容。因此,现在很多都是由内容管理系统自动或半自动地进行的。广受欢迎的博客平台 WordPress 就是一个很好的例子。许多插件在发布内容时使用 RDF(开发人员友好的 JSON-LD 形式)进行注释,只需最少的或不需要任何的努力,从而确保在此过程中更好地进行 SEO(Search engine optimization,搜索引擎最佳化)。
Marcus 认为,随着机器变得越来越复杂,机器注释也会变得越来越好。并且随着人工智能越来越复杂,就会产生一种向上的棘轮效应。现在人工智能还很不成熟,对我们的帮助也不大,但是随着时间的推移,这种情况会有所改变。
更为普遍的是,Marcus 认为,人们正在认识到混合动力车的价值,特别是在最近一两年,以一种他们以前从未认识到的方式:
人们爱上了这样一种观念:“我只要把所有的数据都输入到这个神奇的算法中,它就会让我达到目的。”他们以为这样就能解决无人驾驶汽车和聊天机器人等问题。
但是,人们意识到,“嘿,这并不会真的有效,我们需要其他的技术”。因此,我认为在过去的几年里,与之前的五年相比,人们更渴望尝试不同的事物,并试图找到两全其美的方法。
对此,正如前面提到的,在现实世界中,人工智能的技术水平似乎与 Marcus 所描述的非常接近。下周,我们将重温并进行总结,介绍更多的知识注入技术和大规模语义学,展望未来。
作者介绍:
George Anadiotis,特约撰稿人。熟悉技术、数据和媒体。现为 Gigaome 分析师,为财富 500 强、初创公司和非政府组织提供咨询服务、建立和管理各种规模的项目、产品和团队。
原文链接:
https://www.zdnet.com/article/rebooting-ai-deep-learning-meet-knowledge-graphs/








