本篇文章是个人翻译的,如有商业用途,请通知本人谢谢.
Reusing Pretrained Layers (重用预训练层)
从零开始训练一个非常大的DNN通常不是一个好主意,相反,您应该总是尝试找到一个现有的神经网络来完成与您正在尝试解决的任务类似的任务,然后重新使用这个较低层的 网络:这就是所谓的迁移学习。 这不仅会大大加快培训速度,还将需要更少的培训数据。
例如,假设您可以访问经过培训的DNN,将图片分为100个不同的类别,包括动物,植物,车辆和日常物品。 您现在想要训练一个DNN来对特定类型的车辆进行分类。 这些任务非常相似,因此您应该尝试重新使用第一个网络的一部分(请参见图11-4)。
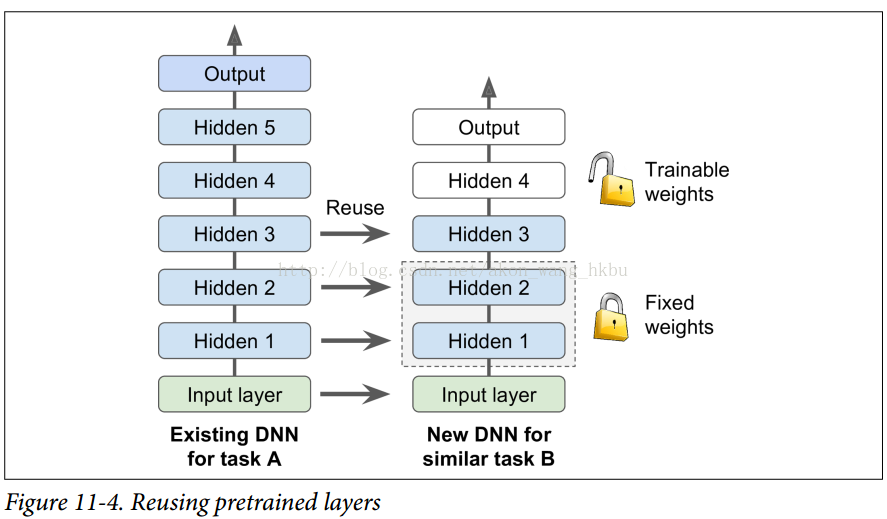
如果新任务的输入图像与原始任务中使用的输入图像的大小不一致,则必须添加预处理步骤以将其大小调整为原始模型的预期大小。 更一般地说,如果输入具有类似的低级层次的特征,则迁移学习将很好地工作。
Reusing a TensorFlow Model
如果原始模型使用TensorFlow进行训练,则可以简单地将其恢复并在新任务上进行训练:
[...] # construct the original model
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
# continue training the model...
完整代码:
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_hidden3 = 50
n_hidden4 = 50
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3")
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4")
hidden5 = tf.layers.dense(hidden4, n_hidden5, activation=tf.nn.relu, name="hidden5")
logits = tf.layers.dense(hidden5, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
learning_rate = 0.01
threshold = 1.0
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
training_op = optimizer.apply_gradients(capped_gvs)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_new_model_final.ckpt")
但是,一般情况下,您只需要重新使用原始模型的一部分(就像我们将要讨论的那样)。 一个简单的解决方案是将Saver配置为仅恢复原始模型中的一部分变量。 例如,下面的代码只恢复隐藏的层1,2和3:
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300 # reused
n_hidden2 = 50 # reused
n_hidden3 = 50 # reused
n_hidden4 = 20 # new!
n_outputs = 10 # new!
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") # reused
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2") # reused
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3") # reused
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4") # new!
logits = tf.layers.dense(hidden4, n_outputs, name="outputs") # new!
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
[...] # build new model with the same definition as before for hidden layers 1-3
reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope="hidden[123]") # regular expression
reuse_vars_dict = dict([(var.op.name, var) for var in reuse_vars])
restore_saver = tf.train.Saver(reuse_vars_dict) # to restore layers 1-3
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
init.run()
restore_saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs): # not shown in the book
for iteration in range(mnist.train.num_examples // batch_size): # not shown
X_batch, y_batch = mnist.train.next_batch(batch_size) # not shown
sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) # not shown
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images, # not shown
y: mnist.test.labels}) # not shown
print(epoch, "Test accuracy:", accuracy_val) # not shown
save_path = saver.save(sess, "./my_new_model_final.ckpt")
首先我们建立新的模型,确保复制原始模型的隐藏层1到3.我们还创建一个节点来初始化所有变量。 然后我们得到刚刚用“trainable = True”(这是默认值)创建的所有变量的列表,我们只保留那些范围与正则表达式“hidden [123]”相匹配的变量(即,我们得到所有可训练的 隐藏层1到3中的变量)。 接下来,我们创建一个字典,将原始模型中每个变量的名称映射到新模型中的名称(通常需要保持完全相同的名称)。 然后,我们创建一个Saver,它将只恢复这些变量,并且创建另一个Saver来保存整个新模型,而不仅仅是第1层到第3层。然后,我们开始一个会话并初始化模型中的所有变量,然后从
原始模型的层1到3.最后,我们在新任务上训练模型并保存。
任务越相似,您可以重复使用的层越多(从较低层开始)。 对于非常相似的任务,您可以尝试保留所有隐藏的图层,然后替换输出图层。
Reusing Models from Other Frameworks
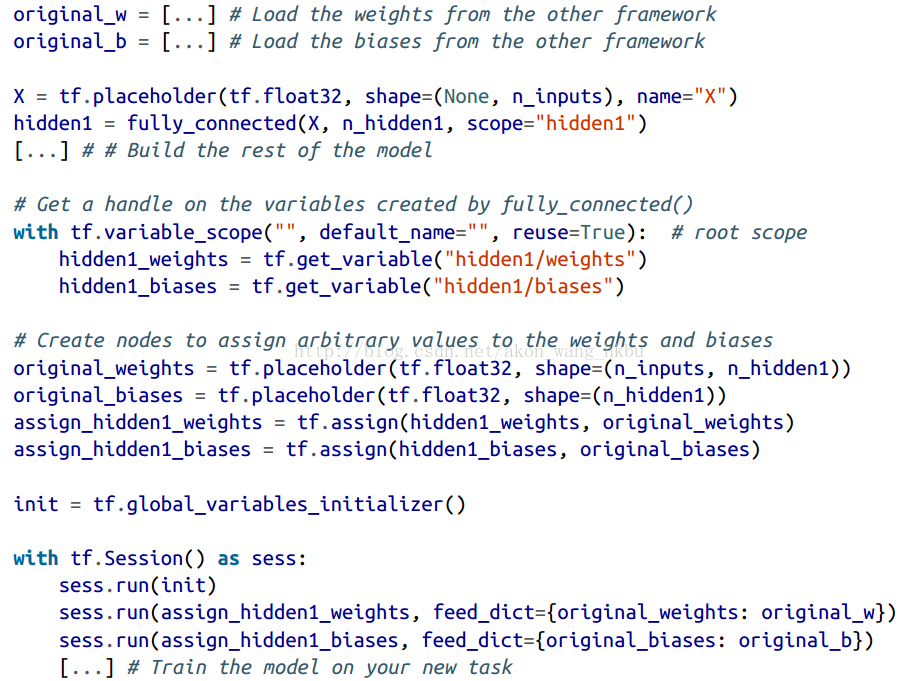
如果模型是使用其他框架进行训练的,则需要手动加载权重(例如,如果使用Theano训练,则使用Theano代码),然后将它们分配给相应的变量。 这可能是相当乏味的。 例如,下面的代码显示了如何复制使用另一个框架训练的模型的第一个隐藏层的权重和偏置:
Freezing the Lower Layers
第一个DNN的低层可能已经学会了检测图片中的低级特征,这将在两个图像分类任务中有用,因此您可以按照原样重新使用这些图层。 在训练新的DNN时,“冻结”权重通常是一个好主意:如果下层权重是固定的,那么上层权重将更容易训练(因为他们不需要学习一个移动的目标)。 要在训练期间冻结较低层,最简单的解决方案是给优化器列出要训练的变量,不包括来自较低层的变量:

第一行获得隐藏层3和4以及输出层中所有可训练变量的列表。 这留下了隐藏层1和2中的变量。接下来,我们将这个受限制的可列表变量列表提供给optimizer的minimize()函数。当当! 现在,图层1和图层2被冻结:在训练过程中不会发生变化(通常称为冻结图层)。
Caching the Frozen Layers (缓存冻层)
由于冻结层不会改变,因此可以为每个训练实例缓存最上面的冻结层的输出。 由于训练贯穿整个数据集很多次,这将给你一个巨大的速度提升,因为每个训练实例只需要经过一次冻结层(而不是每个时期一次)。 例如,你可以先运行整个训练集(假设你有足够的内存):
[python] view plain copy







