本文介绍一个用于分析时间序列数据的 Python 库,可支持数据降维、聚类、马尔可夫状态模型、隐马尔可夫模型等算法。
很多开发者都使用 Python 作为他们的主要开发语言,其中一个原因是 Python 拥有一个强大的标准库。通过各种库函数,开发者可以快速地进行代码编写。本文将为读者介绍一个用于分析时间序列数据的 Python 库:Deeptime。特别地,该库实现了降维、聚类和马尔可夫模型估计等算法。
此外,该库的 API 与 scikit-learn 的类似,并通过鸭子类型(duck typing)为工具提供基本的兼容性。
项目地址:https://github.com/deeptime-ml/deeptime
安装方法
Deeptime 库安装非常简单,可通过 conda,安装方式如下所示:
git clone https://github.com/deeptime-ml/deeptime.git
cd deeptime
git submodule update --init
conda install numpy scipy cython scikit-learn
python setup.py install
也可通过 pip,安装方式如下所示:
pip install git+https://github.com/deeptime-ml/deeptime.git@master
简要介绍
Deeptime 库支持的算法包括动态数据降维、使用神经网络进行深度降维、SINDy、马尔可夫状态模型、隐马尔可夫模型等。此外该库还提供有使用的 API 文档、日志更新等其他内容。

以上图红框中标出的动态数据降维算法为例,鼠标点击该算法,在一级标题下会出现其包含的子标题。点击你想了解的词条,即可链接到相应的说明文档。例如当你点击 Dimension reduction,会出现下级目录,如 TICA、VAMP/time-lagged CCA 等。点击相应算法即可链接到对应的说明文档。

除此以外,该库也为用户提供了相应的示例研究,以供学习。
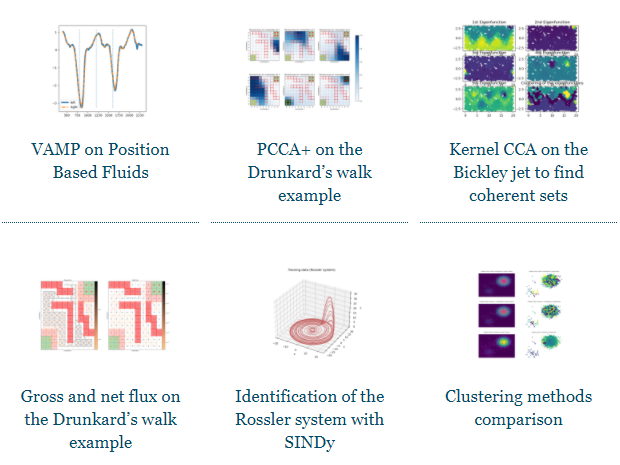
Deeptime 详细文档地址:https://deeptime-ml.github.io/
AAAI 2021线上分享 | BERT模型蒸馏技术,阿里云有新方法在阿里巴巴等机构合作、被AAAI 2021接收的论文《Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation 》中,研究者们提出了一种跨域自动数据增强方法来为数据稀缺领域进行扩充,并在多个不同的任务上显著优于最新的基准。
1月27日20:00,论文共同一作、阿里云高级算法专家邱明辉为大家详细解读此研究。添加机器之心小助手(syncedai5),备注「AAAI」,进群一起看直播。© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com











