本篇文章是个人翻译的,如有商业用途,请通知本人谢谢.
Avoiding Overftting Through Regularization
有四个参数,我可以fit一个大象,五个我可以让他摆动他的象鼻。
—John von Neumann,cited by Enrico Fermi in Nature 427
深度神经网络通常具有数以万计的参数,有时甚至是数百万。 有了这么多的参数,网络拥有难以置信的自由度,可以适应各种复杂的数据集。 但是这个很大的灵活性也意味着它很容易过度训练集。有了数以百万计的参数,你可以适应整个动物园。 在本节中,我们将介绍一些最流行的神经网络正则化技术,以及如何用TensorFlow实现它们:早期停止,l1和l2正则化,drop out,最大范数正则化和数据增强。
Early Stopping
为避免过度拟合训练集,一个很好的解决方案就是尽早停止训练(在第4章中介绍):只要在训练集的性能开始下降时中断训练。
与TensorFlow实现方法之一是评估其对设置定期(例如,每50步)验证模型,并保存一个“winner”的快照,如果它优于以前“winner”的快照。 计算自上次“winner”快照保存以来的步数,并在达到某个限制时(例如2000步)中断训练。 然后恢复最后的“winner”快照。
虽然早期停止在实践中运行良好,但是通过将其与其他正则化技术相结合,您通常可以在网络中获得更高的性能。后恢复最后的“winner”快照。
ℓ1and ℓ2Regularization
就像你在第4章中对简单线性模型所做的那样,你可以使用l1和l2正则化约束一个神经网络的连接权重(但通常不是它的偏置)。
使用TensorFlow做到这一点的一种方法是简单地将适当的正则化术语添加到您的成本函数中。 例如,假设您只有一个权重为weight1的隐藏层和一个权重为weight2的输出层,那么您可以像这样应用l1正则化:
我们可以将正则化函数传递给tf.layers.dense()函数,该函数将使用它来创建计算正则化损失的操作,并将这些操作添加到正则化损失集合中。 开始和上面一样:
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
接下来,我们将使用Python partial()函数来避免一遍又一遍地重复相同的参数。 请注意,我们设置了内核正则化参数(正则化函数有l1_regularizer(),l2_regularizer(), andl1_l2_regularizer()
:
scale = 0.001
my_dense_layer = partial(
tf.layers.dense, activation=tf.nn.relu,
kernel_regularizer=tf.contrib.layers.l1_regularizer(scale))
with tf.name_scope("dnn"):
hidden1 = my_dense_layer(X, n_hidden1, name="hidden1")
hidden2 = my_dense_layer(hidden1, n_hidden2, name="hidden2")
logits = my_dense_layer(hidden2, n_outputs, activation=None,
name="outputs")
该代码创建了一个具有两个隐藏层和一个输出层的神经网络,并且还在图中创建节点以计算与每个层的权重相对应的l1正则化损失。 TensorFlow会自动将这些节点添加到包含所有正则化损失的特殊集合中。 您只需要将这些正则化损失添加到您的整体损失中,如下所示:
接下来,我们必须将正则化损失加到基本损失上:
with tf.name_scope("loss"): # not shown in the book
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits( # not shown
labels=y, logits=logits) # not shown
base_loss = tf.reduce_mean(xentropy, name="avg_xentropy") # not shown
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
loss = tf.add_n([base_loss] + reg_losses, name="loss")
其余的和往常一样:
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 20
batch_size = 200
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_model_final.ckpt")
不要忘记把正常化的损失加在你的整体损失上,否则就会被忽略。
Dropout
深度神经网络最流行的正则化技术可以说是drop out。 它由GE Hinton于2012年提出,并在Nitish Srivastava等人的论文中进一步详细描述,并且已被证明是非常成功的:即使是现有技术的神经网络,通过添加drop out。 这听起来可能不是很多,但是当一个模型已经具有95%的准确率时,获得2%的准确度提升意味着将误差率降低近40%(从5%误差降至大约3%)。
这是一个相当简单的算法:在每个训练步骤中,每个神经元(包括输入神经元,但不包括输出神经元)都有一个暂时“退出”的概率p,这意味着在这个训练步骤中它将被完全忽略, 在下一步可能会激活(见图11-9)。 超参数p称为丢失率,通常设为50%。 训练后,神经元不会再下降。 这就是全部(除了我们将要讨论的技术细节)。
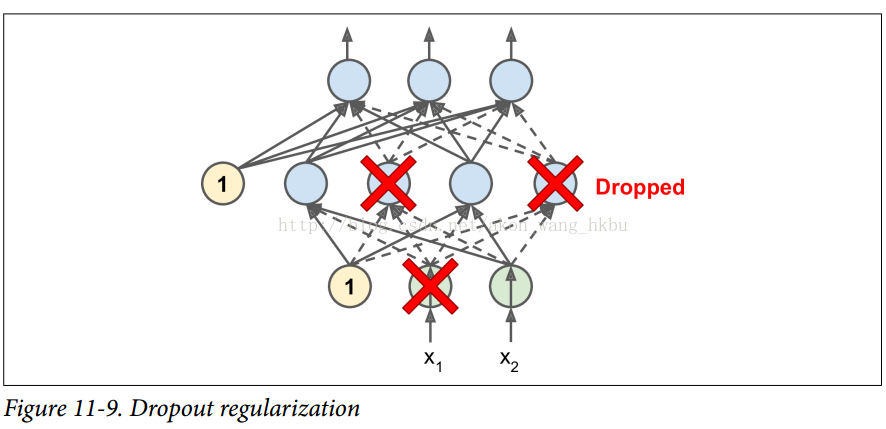
一开始这个技术是相当粗鲁,这是相当令人惊讶的。如果一个公司的员工每天早上被告知要掷硬币来决定是否上班,公司的表现会不会更好呢?那么,谁知道;也许会!公司显然将被迫适应这样的组织构架;它不能依靠任何一个人填写咖啡机或执行任何其他关键任务,所以这个专业知识将不得不分散在几个人身上。员工必须学会与其他的许多同事合作,而不仅仅是其中的一小部分。该公司将变得更有弹性。如果一个人放弃了,那就没有什么区别了。目前还不清楚这个想法是否真的可以在公司实行,但它确实对于神经网络是可以的。神经元退化训练不能与其相邻的神经元共同适应;他们必须尽可能让自己变得有用。他们也不能过分依赖一些输入神经元;他们必须注意他们的每个输入神经元。他们最终对输入的微小变化会不太敏感。最后,你会得到一个更强大的网络,更好地推广。
了解dropout的另一种方法是认识到每个训练步骤都会产生一个独特的神经网络。 由于每个神经元可以存在或不存在,总共有2 ^ N个可能的网络(其中N是可丢弃神经元的总数)。 这是一个巨大的数字,实际上不可能对同一个神经网络进行两次采样。 一旦你运行了10,000个训练步骤,你基本上已经训练了10,000个不同的神经网络(每个神经网络只有一个训练实例)。 这些神经网络显然不是独立的,因为它们共享许多权重,但是它们都是不同的。 由此产生的神经网络可以看作是所有这些较小的神经网络的平均集合。
有一个小而重要的技术细节。 假设p = 50,在这种情况下,在测试期间,在训练期间神经元将被连接到两倍于(平均)的输入神经元。 为了弥补这个事实,我们需要在训练之后将每个神经元的输入连接权重乘以0.5。 如果我们不这样做,每个神经元的总输入信号大概是网络训练的两倍,而且不太可能表现良好。 更一般地说,我们需要将每个输入连接权重乘以训练后的保持概率(1-p)。 或者,我们可以在训练过程中将每个神经元的输出除以保持概率(这些替代方案并不完全等价,但它们工作得同样好)。
要使用TensorFlow实现压缩,可以简单地将dropout()函数应用于输入层和每个隐藏层的输出。 在训练过程中,这个功能随机丢弃一些项目(将它们设置为0),并用保留概率来划分剩余项目。 训练结束后,这个功能什么都不做。 下面的代码将丢失正则化应用于我们的三层神经网络:
注意:本书使用tf.contrib.layers.dropout()而不是tf.layers.dropout()(本章写作时不存在)。 现在最好使用tf.layers.dropout(),因为contrib模块中的任何内容都可能会改变或被删除,恕不另行通知。 tf.layers.dropout()函数几乎与tf.contrib.layers.dropout()函数相同,只是有一些细微差别。 最重要的是:
- 您必须指定丢失率(率)而不是保持概率(keep_prob),其中rate简单地等于1 - keep_prob
- is_training参数被重命名为training。
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
training = tf.placeholder_with_default(False, shape=(), name='training')
dropout_rate = 0.5 # == 1 - keep_prob
X_drop = tf.layers.dropout(X, dropout_rate, training=training)
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X_drop, n_hidden1, activation=tf.nn.relu,
name="hidden1")
hidden1_drop = tf.layers.dropout(hidden1, dropout_rate, training=training)
hidden2 = tf.layers.dense(hidden1_drop, n_hidden2, activation=tf.nn.relu,
name="hidden2")
hidden2_drop = tf.layers.dropout(hidden2, dropout_rate, training=training)
logits = tf.layers.dense(hidden2_drop, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 20
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels})
print(epoch, "Test accuracy:", acc_test)
save_path = saver.save(sess, "./my_model_final.ckpt")
你想在tensorflow.contrib.layers中使用dropout()函数,而不是tensorflow.nn中的那个。 第一个在不训练的时候关掉(没有操作),这是你想要的,而第二个不是
如果观察到模型过度拟合,则可以增加dropout率(即,减少keep_prob超参数)。 相反,如果模型不适合训练集,则应尝试降低dropout率(即增加keep_prob)。 它也可以帮助增加大层的dropout率,并减少小层的dropout率。
dropout倾向于显着减缓收敛,但通常会导致一个好得多的模型,在适当调整之后。 所以,这通常是值得去付出额外的时间和精力的。
Max-Norm Regularization
另一种在神经网络中非常流行的正则化技术被称为最大范数正则化:对于每个神经元,它约束输入连接的权重w,使得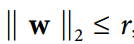 ,其中r是最大范数超参数,
,其中r是最大范数超参数,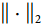 是l2范数。
是l2范数。
我们通常通过在每个训练步骤之后计算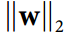 来实现这个约束,并且如果需要的话可以剪切W
来实现这个约束,并且如果需要的话可以剪切W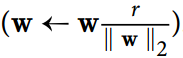 .
.
减少r增加了正则化的数量,并有助于减少过度配合。 Maxnorm正则化还可以帮助减轻消失/爆炸梯度问题(如果您不使用批量标准化)。
让我们回到MNIST的简单而简单的神经网络,只有两个隐藏层:
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
learning_rate = 0.01
momentum = 0.9
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
接下来,让我们来处理第一个隐藏层的权重,并创建一个操作,使用clip_by_norm()函数计算剪切后的权重。 然后我们创建一个赋值操作来将权值赋给权值变量:
threshold = 1.0
weights = tf.get_default_graph().get_tensor_by_name("hidden1/kernel:0")
clipped_weights = tf.clip_by_norm(weights, clip_norm=threshold, axes=1)
clip_weights = tf.assign(weights, clipped_weights)
我们也可以为第二个隐藏层做到这一点:
weights2 = tf.get_default_graph().get_tensor_by_name("hidden2/kernel:0")
clipped_weights2 = tf.clip_by_norm(weights2, clip_norm=threshold, axes=1)
clip_weights2 = tf.assign(weights2, clipped_weights2)
让我们添加一个初始化器和一个保存器:
init = tf.global_variables_initializer()
saver = tf.train.Saver()
现在我们可以训练模型。 与往常一样,除了在运行training_op之后,我们运行clip_weights和clip_weights2操作:
n_epochs = 20
batch_size = 50
with tf.Session() as sess: # not shown in the book
init.run() # not shown
for epoch in range(n_epochs): # not shown
for iteration in range(mnist.train.num_examples // batch_size): # not shown
X_batch, y_batch = mnist.train.next_batch(batch_size) # not shown
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
clip_weights.eval()
clip_weights2.eval() # not shown
acc_test = accuracy.eval(feed_dict={X: mnist.test.images, # not shown
y: mnist.test.labels}) # not shown
print(epoch, "Test accuracy:", acc_test) # not shown
save_path = saver.save(sess, "./my_model_final.ckpt") # not shown
上面的实现很简单,工作正常,但有点麻烦。 更好的方法是定义一个max_norm_regularizer()函数:
def max_norm_regularizer(threshold, axes=1, name="max_norm",
collection="max_norm"):
def max_norm(weights):
clipped = tf.clip_by_norm(weights, clip_norm=threshold, axes=axes)
clip_weights = tf.assign(weights, clipped, name=name)
tf.add_to_collection(collection, clip_weights)
return None # there is no regularization loss term
return max_norm
然后你可以调用这个函数来得到一个最大规范调节器(与你想要的阈值)。 当你创建一个隐藏层时,你可以将这个正规化器传递给kernel_regularizer参数:
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
learning_rate = 0.01
momentum = 0.9
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
max_norm_reg = max_norm_regularizer(threshold=1.0)
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg, name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
训练与往常一样,除了每次训练后必须运行重量裁剪操作:
请注意,最大范数正则化不需要在整体损失函数中添加正则化损失项,所以max_norm()函数返回None。 但是,在每个训练步骤之后,仍需要运行clip_weights操作,因此您需要能够掌握它。 这就是为什么max_norm()函数将clip_weights节点添加到max-norm剪裁操作的集合中的原因。您需要获取这些裁剪操作并在每个训练步骤后运行它们:
n_epochs = 20
batch_size = 50
clip_all_weights = tf.get_collection("max_norm")
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
sess.run(clip_all_weights)
acc_test = accuracy.eval(feed_dict={X: mnist.test.images, # not shown in the book
y: mnist.test.labels}) # not shown
print(epoch, "Test accuracy:", acc_test) # not shown
save_path = saver.save(sess, "./my_model_final.ckpt") # not shown
Data Augmentation (数据扩张)
最后一个正规化技术,数据增强,包括从现有的训练实例中产生新的训练实例,人为地增加了训练集的大小。 这将减少过度拟合,使之成为正规化技术。 诀窍是生成逼真的训练实例; 理想情况下,一个人不应该能够分辨出哪些是生成的,哪些不是生成的。 而且,简单地加白噪声也无济于事。 你应用的修改应该是可以学习的(白噪声不是)。
例如,如果您的模型是为了分类蘑菇图片,您可以稍微移动,旋转和调整训练集中的每个图片的大小,并将结果图片添加到训练集(见图11-10)。 这迫使模型更能容忍图片中蘑菇的位置,方向和大小。 如果您希望模型对光照条件更加宽容,则可以类似地生成具有各种对比度的许多图像。 假设蘑菇是对称的,你也可以水平翻转图片。 通过结合这些转换,可以大大增加训练集的大小。

在培训期间通常优先生成训练实例,而不是浪费存储空间和网络带宽。 TensorFlow提供了多种图像处理操作,例如移调(shift),旋转,调整大小,翻转和裁剪,以及调整亮度,对比度,饱和度和色调(请参阅API文档以获取更多详细信息)。 这可以很容易地为图像数据集实现数据增强。
训练非常深的神经网络的另一个强大的技术是添加跳过连接(跳过连接是将层的输入添加到更高层的输出时)。 当我们谈论深度残差网络时,我们将在第13章中探讨这个想法。
Practical Guidelines (实际指导)
在本章中,我们已经涵盖了很多技术,你可能想知道应该使用哪些技术。 表11-2中的配置在大多数情况下都能正常工作。

当然,如果你能找到解决类似问题的方法,你应该尝试重用预训练的神经网络的一部分。
这个默认配置可能需要调整:
- 如果你找不到一个好的学习速度(收敛速度太慢,所以你增加了训练速度,现在收敛速度很快,但是网络的准确性不是最理想的),那么你可以尝试添加一个学习计划,如指数衰减。
- 如果你的训练集太小,你可以实现数据增强。
- 如果你需要一个稀疏的模型,你可以添加一个正则化到混合(并可以选择在训练后将微小的权重归零)。 如果您需要更稀疏的模型,您可以尝试使用FTRL而不是Adam优化以及l1正则化。
- 如果在运行时需要快速模型,则可能需要删除批处理标准化,并可能用leakyReLU替换ELU激活函数。 有一个稀疏的模型也将有所帮助。
有了这些指导方针,你现在已经准备好训练非常深的网络 - 好吧,如果你非常有耐心的话,那就是! 如果使用单台机器,则可能需要等待几天甚至几个月才能完成培训。 在下一章中,我们将讨论如何使用分布式TensorFlow在许多服务器和GPU上训练和运行模型。












