首先,我们像以前一样创建输入占位符。 然后,我们创建一个BasicRNNCell,您可以将其视为一个工厂,创建单元的副本以构建展开的RNN(每个时间步一个)。 然后我们调用static_rnn(),给它的单元工厂和输入张量,并告诉它输入的数据类型(这是用来创建初始状态矩阵,默认情况下是满零)。 static_rnn()函数为每个输入调用单元工厂的__call __()函数,创建单元格的两个拷贝(每个单元包含一个5个循环神经元层),并具有共享的权重和偏置项,并且像前面一样。
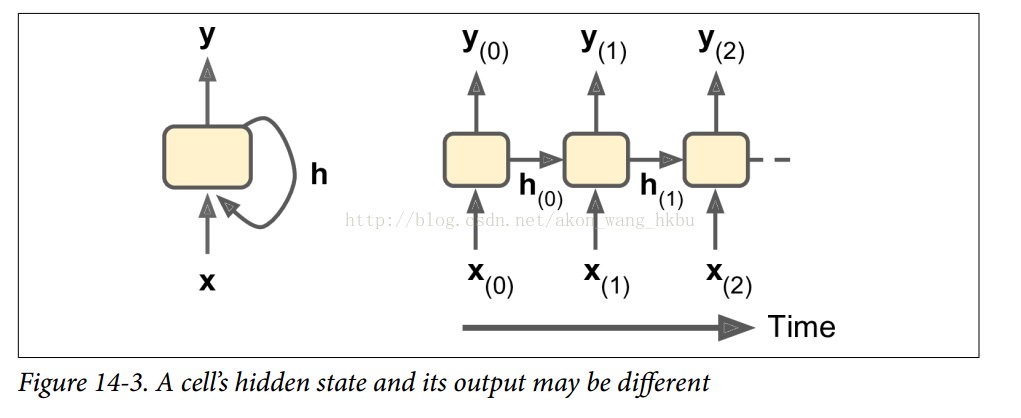
static_rnn()函数返回两个对象。 第一个是包含每个时间步的输出张量的Python列表。 第二个是包含网络最终状态的张量。 当你使用基本的单元格时,最后的状态就等于最后的输出。
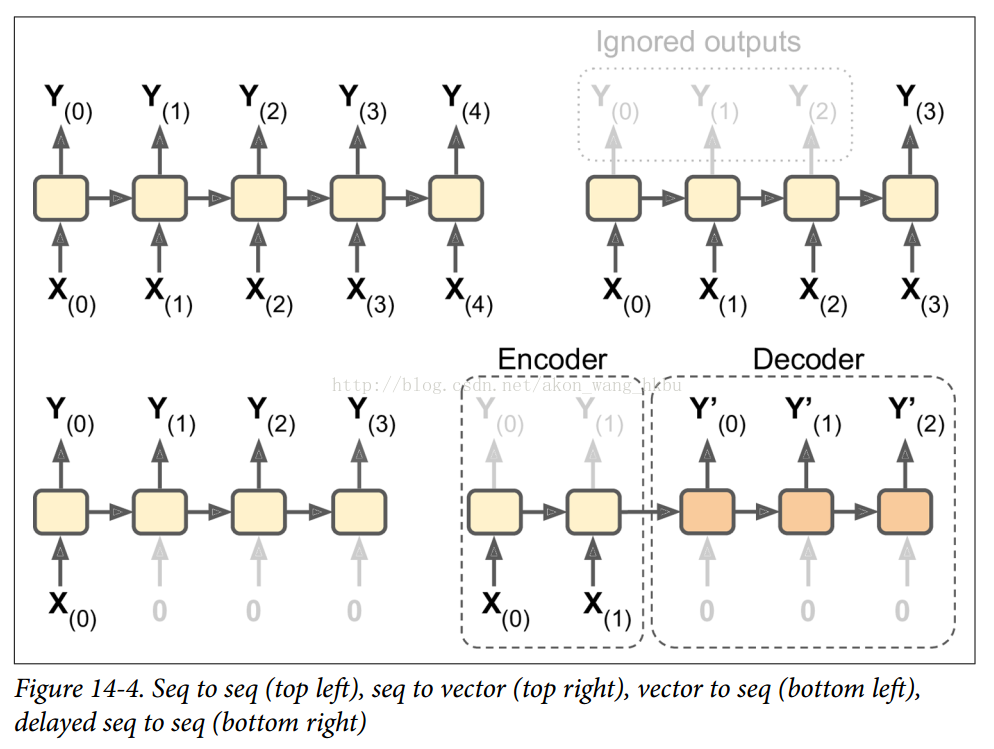
如果有50个时间步长,则不得不定义50个输入占位符和50个输出张量。而且,在执行时,您将不得不为50个占位符中的每个占位符输入数据并且还要操纵50个输出。我们来简化一下。下面的代码再次构建相同的RNN,但是这次它需要一个形状为[None,n_steps,n_inputs]的单个输入占位符,其中第一个维度是最小批量大小。然后提取每个时间步的输入序列列表。 X_seqs是形状n_steps张量的Python列表[None,n_inputs],其中第一个维度再次是最小批量大小。为此,我们首先使用转置()函数交换前两个维度,以便时间步骤现在是第一维度。然后,我们使
unstack()函数沿第一维(即每个时间步的一个张量)提取张量的Python列表。接下来的两行和以前一样。最后,我们使用stack()函数将所有输出张量合并成一个张量,然后我们交换前两个维度得到形状的最终输出张量[None, n_steps,n_neurons](第一个维度是mini-批量大小)。
但是,这种方法仍然会建立一个每个时间步包含一个单元的图。 如果有50个时间步,这个图看起来会非常难看。 这有点像写一个程序而没有使用循环(例如,Y0 = f(0,X0); Y1 = f(Y0,X1); Y2 = f(Y1,X2); ...; Y50 = f Y49,X50))。 如果使用大图,在反向传播期间(特别是在GPU卡内存有限的情况下),您甚至可能会发生内存不足(OOM)错误,因为它必须在正向传递期间存储所有张量值,因此可以使用它们来计算 梯度在反向通过。
dynamic_rnn()函数使用while_loop()操作在单元格上运行适当的次数,如果要在反向传播期间将GPU内存交换到CPU内存,可以设置swap_memory = True,以避免内存不足错误。 方便的是,它还可以在每个时间步(形状[None,n_steps,n_inputs])接受所有输入的单张量,并且在每个时间步(形状[None,n_steps,n_neurons])上输出所有输出的单张量。 没有必要堆叠,拆散或转置。 以下代码使用dynamic_rnn()函数创建与之前相同的RNN。
这太好了!






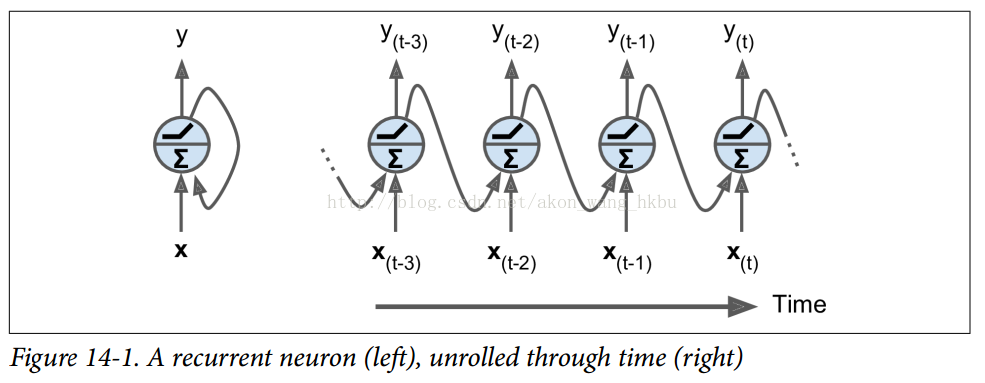
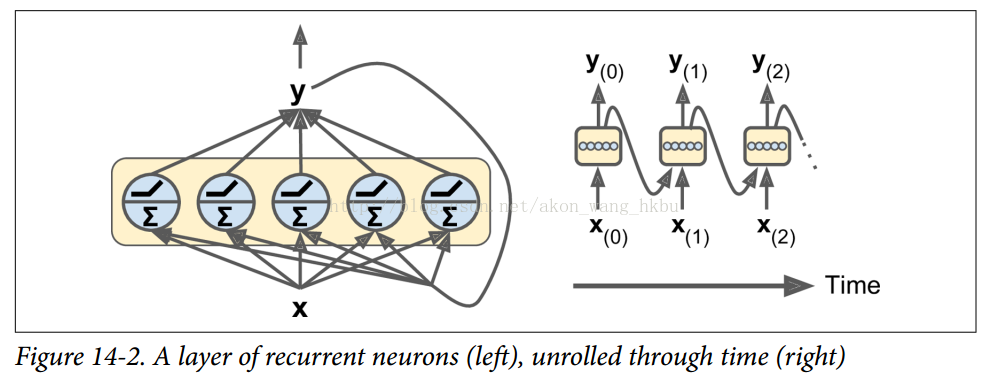
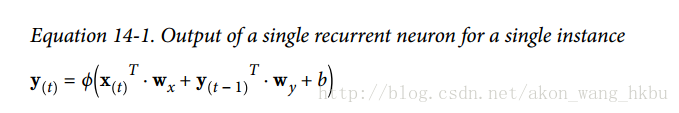

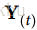 是一个m×n(神经元)矩阵,包含在最小批次中每个实例在时间步t处的层输出(m是最小批次中的实例数,n(神经元)是神经元)。
是一个m×n(神经元)矩阵,包含在最小批次中每个实例在时间步t处的层输出(m是最小批次中的实例数,n(神经元)是神经元)。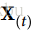 是包含所有实例的输入的m×n(输入)矩阵(n(输入)是输入特征的数量)。
是包含所有实例的输入的m×n(输入)矩阵(n(输入)是输入特征的数量)。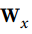 是包含当前时间步的输入的连接权重的n(输入)×n(神经元)矩阵。
是包含当前时间步的输入的连接权重的n(输入)×n(神经元)矩阵。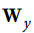 是包含当前时间步的输出的连接权重的n(输入)×n(神经元)矩阵。
是包含当前时间步的输出的连接权重的n(输入)×n(神经元)矩阵。