
很多人用 git 从头到尾就三板斧,add,commit,push,就完事儿了。入门 git 的第一天,我们的领路人肯定会说,先学会这三招,别的不会再查。
的确是在刚刚开始的时候,需要快速的进入和他人协同使用 git 的状态,没那么多时间慢慢研究细节,本文也不会去追求让你学到某一两个 git 的奇技淫巧。本文想要做到的是,让你彻彻底底的明白 git 是一个什么样子的东西,本质上是在做什么,打通对 git 的任督二脉,其它的命令你自然就会知其所以然了。
要阅读本文,你需要对 git 有基本的操作理解,至少得挥过上面提到的三板斧吧~
Git 的三区两步
首先很基础的一个东西就是 git 的三个区,工作区,暂存区,以及存储库(存储区)。我们的很多命令其实本质上就在这三个区域做交互的工作,所以需要彻底理解这三个区域的作用于内容。
工作区就是当前我们可以看到的,写代码的地方,当前正在进行改动的地方。
暂存区就是当你 git add 了以后的地方,将当前某些文件放进暂存区,就是通过 git add 来执行的。
而存储区(repository)其实就是真正 Git 保存了信息的地方,所有的改动都会记录下来,通过 git commit 命令就相当于将你的暂存区的所有改动放到了 git 的仓库中,至此你就完整的保存了所有的信息。
换一个更加形象的说法,来帮助大家理解这三个区的概念:就是你有一批货物,每个货物是一个文件,现在你要将这些货物存放到仓库中。货物在你手上时,相当于是在工作区,你可以对货物(文件)进行调整操作,然后你将整理好的货物搬到仓库门前的广场(这就是暂存区)。假如有了一小批货物是同样的用途,就可以一起放进仓库,并贴上一张关于这批货物的描述的便条(这里的便条就是 git commit 时的描述信息)。
有了这样的一个基础概念,我们就明白了为什么 git 要选择这样的三步走,因为你可以选择合适的 commit 时间,让一批改动有同一个描述信息。
Git 对象
为了加深对 git 的理解,我们可能需要知道什么是 Git 对象。在 Git 中主要有 4 种重要的对象:「Blob 对象,Tree 对象,Commit 对象」以及 「Tag 对象」。下面我们介绍这四种对象的概念,然后会进一步用例子(进入到 .git 文件中)来帮助大家更好的理解。
首先我们得了解每次 commit 以后得到的那个字符串是什么意思,是如何得来的。这是一种哈希算法,名字为 sha-1,对目标的 Git 对象进行计算,得到一个哈希值,目的是为了避免不同的文件得到相同的结果,从而在 Git 的记录中出现冲突。
「blob 对象」:接下来,了解一下什么是 blob 对象:binary large object,字面意思很容易理解,就是一个目标对象,其实在 Git 中,就是一个文件经过压缩后的内容。也就是说,在 Git 中,每个文件都是一个 blob 对象,也就是说,利用这个 blob 对象可以还原出原始的文件。
记住这一点,每次你 add 以后,git 就会对你修改了的文件生成一个 blob 对象,也就是说,不仅仅每个文件都是一个 blob 对象,文件的不同版本也会是一个 blob 对象。
「tree对象」:然后是 tree 对象。顾名思义,就是一个树形结构图。在 Git 中,不会保存每个文件夹(也可以理解为目录,虽然在 Git 中它们并没有上下级的关系),但是为了记录文件之间的关系,会用 tree 对象来表示这种关系。
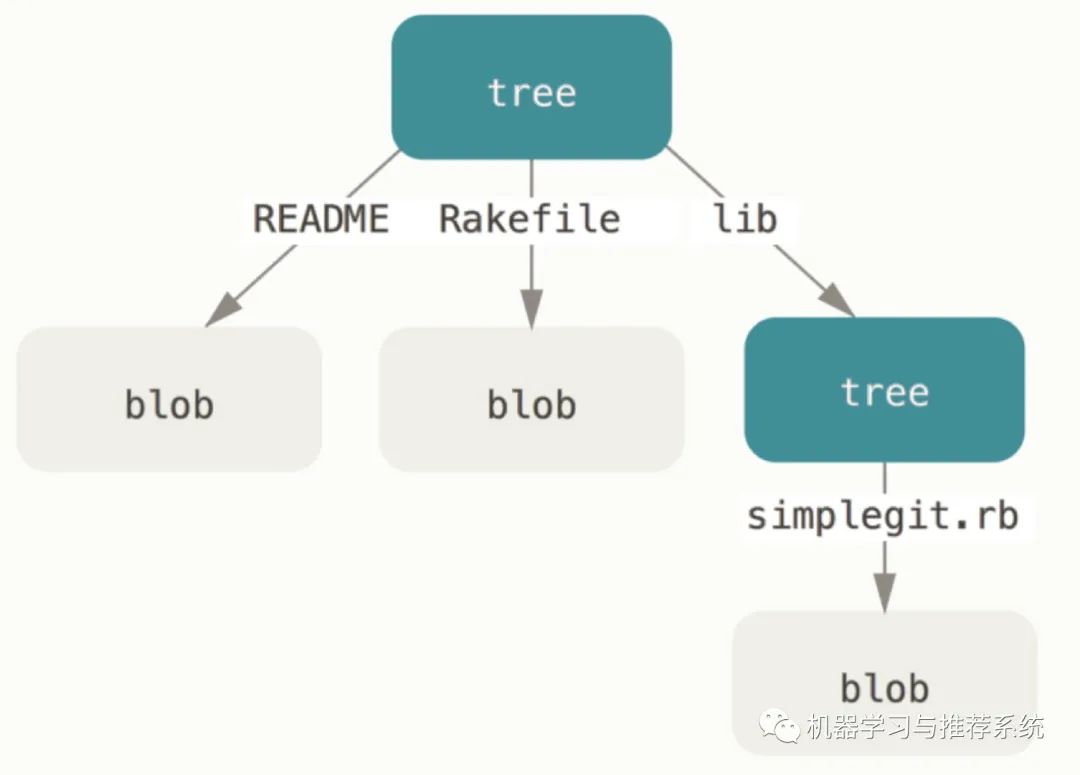
这里的 tree 可以按照文件夹来理解(再强调下,tree 对象和 blob 对象并不是文件夹和文件的关系),但是它们的指向某种程度上表示了文件夹和文件的关系。
从上面的图可以看出来,tree 对象可以指向 blob 对象,也可以指向 tree 对象。
「commit 对象」:commit 这个命令我们一定很熟悉,但是它是什么呢?如何产生作用?奥秘来自于 commit 对象本身。每个 commit 对象本身包含了这些信息:
本质上讲,每次 commit 意味着需要记录当前文件系统的一个状态,所以 commit 是需要包含一个 tree 对象(其实是指向一个 tree 对象)。像我们前面所讲,tree 对象其实类似于一个文件夹的作用,如果指向根文件,那么当前所有文件的状态就相当于都知道了。
这里我们可以提起一个概念(或许在很多 Git 教程中都提到了,但是你没有完全理解),「Git的工作原理是创建文件快照,而不是像其他VCS那样增加差异。」
其中的奥秘就在这个 commit 对象的内容,它指向的 tree 对象一般来说,就是一个根文件的状态,通过 tree 对象本身再指向其它 tree 对象或者 blob 对象,就保存了当前所有文件的状态。也就是通过一个 commit 对象,我们就保存了一份当前文件系统的快照。
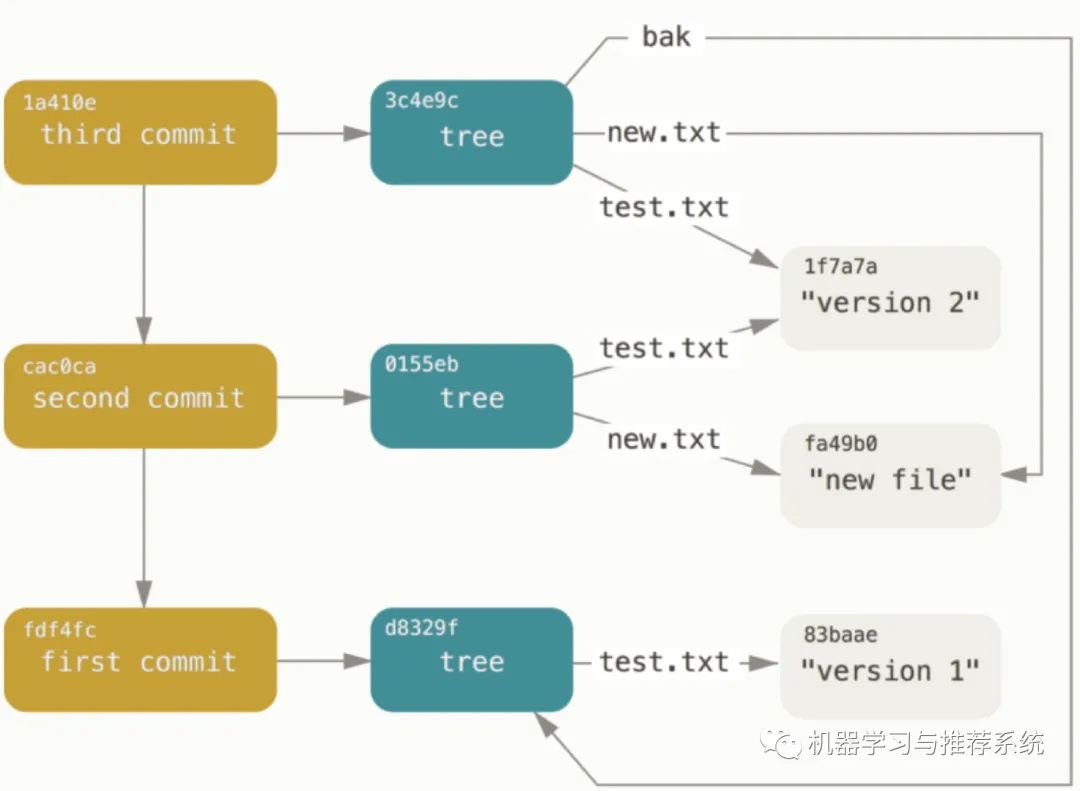
此外,还需要了解到一个细节,除了第一个 commit 对象外,每个 commit 对象中本身还会指向前一个 commit 对象。
这里选择一个 git-scm 文档中的一个图片进行展示,三次 commit 分别如何指向这些文件,一目了然:
「tag 对象」:tag 对象就比较简单了,具体 git tag 的命令我们就不去介绍了,本质上就是对当前 commit 添加一些描述信息,所以我们也可以很容易的去理解它的原理,就是指向一个 commit 对象,此外再附加一些执行 git tag 命令时我们添加的那些备注信息,备注人,时间等等。
从 .git 文件说起
在介绍了前面的概念后,我们可能需要进行一些实际操作,才能更容易来理解具体的原理。这里我们一起来深入到 .git 文件中进行探索,下去大家可以自己试试,加深理解。
我们都知道以一个点开头的文件往往都是隐藏文件,.git 文件夹中其实就是我们使用 git 的全部奥秘,那么先简单的看一下这个文件中有些什么内容。
我们先从 objects 看起,这里保存了所有 Git 中的对象,我们前面介绍的几个对象就在这里放着。首先点开你的 objects 文件夹,里面一定是大量的其它文件夹,像我这样:
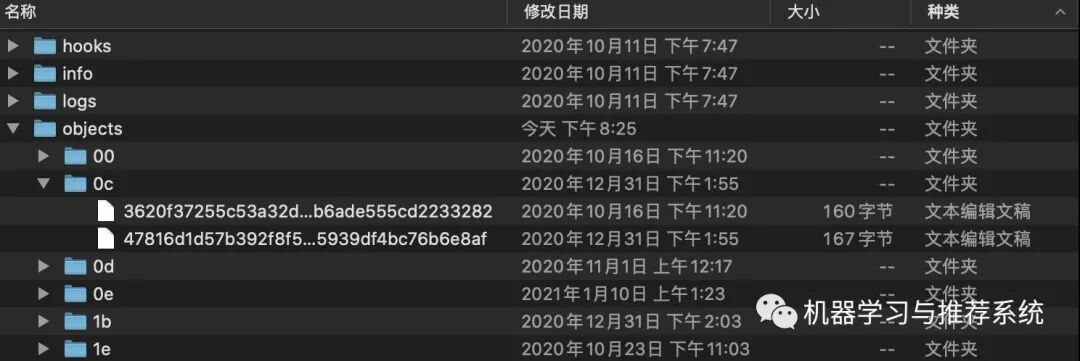
这里我们来介绍一下,每个文件夹的名字,其实是一个 sha-1 后的哈希值的前两位,以上面这幅图为例,0c 加上 3620f。。。就是一个 git 对象。之所以选择这种存储方式,是为了节省空间,要不然所有的对象都直接放在一起,太多啦~
接下来用 git cat-file 命令来查看这个对象的内容:(参数 -t 表示查看这个对象的类型,-p 表示查看里面的内容)

首先我们可以看到这个 0c3620f 的对象是一个 commit 对象,接着我们用 -p 参数来查看其中的内容,发现它指向一个 tree 对象,指向一个 parent 对象(这个 parent 就是当前 commit 对象的前一次 commit),此外还保存了 commit 的作者等信息。
我们继续进行挖掘,看一看所指向的这个 tree 对象,在查看之前,我们来验证一下它是否保存在这个 objects 文件夹中。按照前面的介绍,以这个对象的哈希值的前两位会作为一个文件夹保存在 objects 文件夹中,找一下是不是存在:
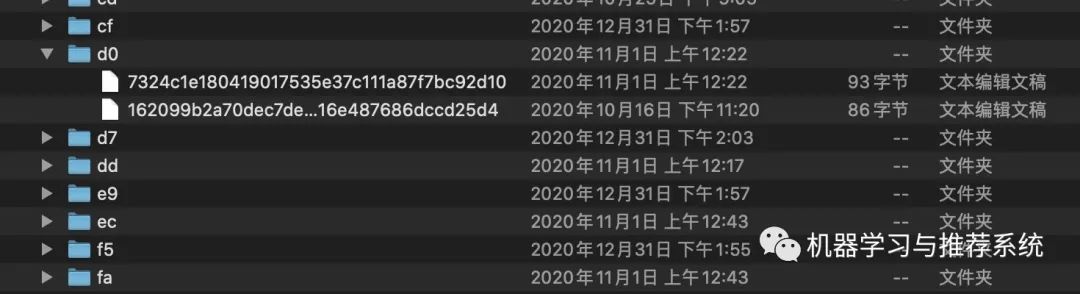
果然有一个叫 d0 的文件夹,其中有一个对象是 162099。。。那么我们继续用前面的命令来探索一下这个 tree 对象:

首先用 -t 参数看到的确是一个 tree 对象,然后看一下它有哪些内容,加上 -p 参数,可以看到,这个 tree 对象指向一个 blob 对象,和一个 tree 对象。
其中这个 blob 对象就是我们的 readme 文件,tree 对象指向了一个名为 Search 的文件夹。对一个 blob 对象,也可以用 git cat-file 对象加上 -p 参数来还原其中的内容。
是不是现在明白了前面说的为什么 Git 保存的是文件系统的快照,通过指向一个根目录文件,记录当前的文件系统状态。然后通过一连串的指向关系,可以知道所有当前 commit 的所有文件对象的内容。
「refs」:还有一个值得关注的点文件夹是 .git/refs,可以看到当前我的 refs 文件中还有三个文件夹,分别保存了 head 对象指向的位置,remotes 的信息,以及 tags 的信息。
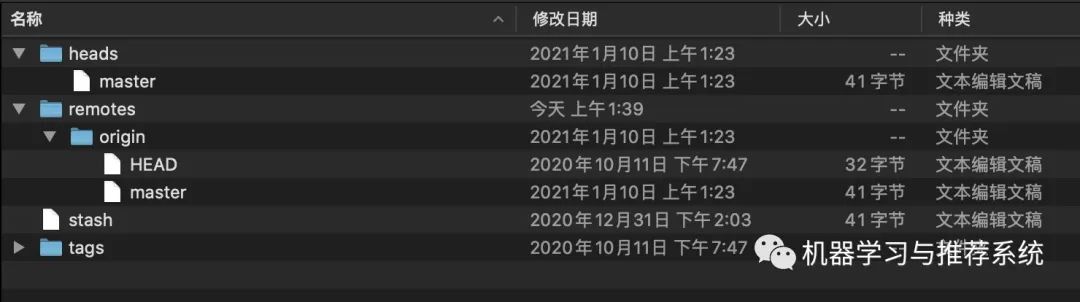
简单介绍一下,head 中存放了分支信息,当前我们看到是只有一个 master 分支,如果我们再添加一些个新分支,可以看到多了一个 test1 分支,这个时候可以看到当前的 heads 文件夹中产生了变化:

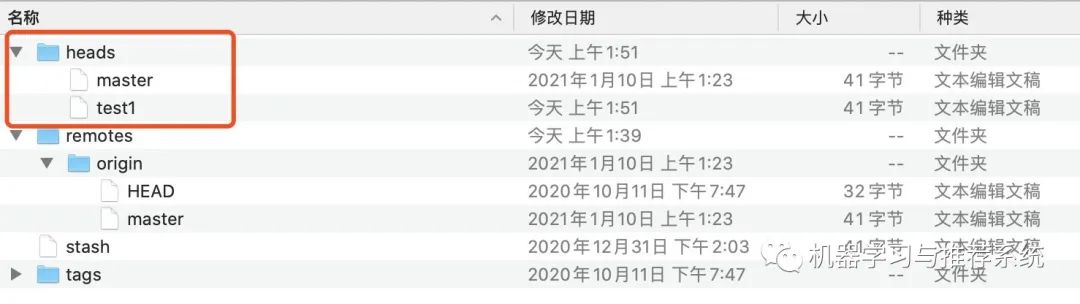
remotes 当中还会有多个文件夹,如果没有连接多个远程的话,一般来说就是一个 origin 文件夹,里面的远程分支基本上与本地类似,同样也会指向某个 commit 对象。
这些内容大家都可以通过前面的命令来进行验证,这里就不一一进行例子展示了。
关于分支
之前工作遇到同学,不太喜欢切分支。假如稍微了解了一点关于的基础,知道 Git 是储存文件快照的,一想一个 commit 都要储存所有当前文件的状态,那一个分支又要保存这么多信息吗?
其实所谓的分支,就是一个只有 40 个字节的文件而已,我们看看前面的 refs/haeds 文件夹,master 和 test1 分支,都是一个 41 字节的文件。我们来看看这两个分支:
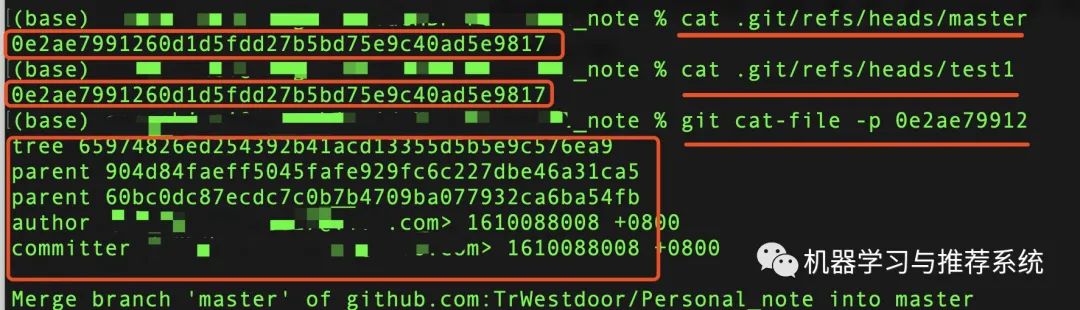
通过直接查看两个文件的内容,发现一模一样,是一个 sha-1 值,然后用 git 看了一下,发现是上一次 merge 的一个 commit。
现在明白了吧?每次创建一个分支其实就是保存了一个 commit 的值,40 个字节的开销,也太小了叭。所以大家在开发的时候,尽量每个功能都开一个分支,这样子在后续进行提交,回退,做某些修改的时候,都会很方便,不用担心影响到其它工作分支。
讲到这里,我们也来补充一下 .git 文件另外一个有意思的内容。Git 如何记录我们当前在哪个分支呢?在你的 .git 文件夹中还会有一个文件(HEAD),这个文件中是什么内容呢?来看看吧:

可以看到这个 HEAD 文件其实就保存了一个路径,这个路径指向我们前面提到的,放分支的 refs/heads 文件夹当中的某个分支(这个例子中是 master)。
此外还有一个 ORIG_HEAD 文件,当我们做了某个“危险”的操作时(比如 merge,rebase,reset 等),Git 就会把 HEAD 的状态存放在该文件中,让你随时可以调回危险动作之前的状态。
总结
不知不觉也啰嗦了几千字了,之前看了很多关于 Git 的进阶教程,最后发现大多数教程都是为大家介绍一些奇技淫巧,所以有了这么一篇文章,想要为大家深入了解 git 的基本原理提供一些帮助。
文章贯彻了我以前源码解析和 pytorch 教程的一贯风格,想要授人以渔,而不是教一两个炫酷的命令,所以希望大家可以带着通过本文的浅浅收获,进一步去 .git 文件中进行探索,来获得一个恍然大悟的快感。
如果大家喜欢这样的文章,可以给我留言,告诉我来进一步整理此类的文章。如果这篇文章对你带来了帮助,就分享下吧,谢谢~~
reference
#1 https://git-scm.com/
#2 Git从入门到精通【高见龙】








