1. 关联规则
大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布;据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起;结果这两个品类的销量都有明显的增长;分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品。不论这个案例是否是真实的,案例中分析顾客购买记录的方式就是关联规则分析法Association Rules。关联规则分析也被称为购物篮分析,用于分析数据集各项之间的关联关系。1.1 基本概念
- 项集:item的集合,如集合{牛奶、麦片、糖}是一个3项集,可以认为是购买记录里物品的集合。
- 频繁项集:顾名思义就是频繁出现的item项的集合。如何定义频繁呢?用比例来判定,关联规则中采用支持度和置信度两个概念来计算比例值
- 支持度:共同出现的项在整体项中的比例。以购买记录为例子,购买记录100条,如果商品A和B同时出现50条购买记录(即同时购买A和B的记录有50),那边A和B这个2项集的支持度为50%
- 置信度:购买A后再购买B的条件概率,根据贝叶斯公式,可如下表示:
- 提升度:为了判断产生规则的实际价值,即使用规则后商品出现的次数是否高于商品单独出现的评率,提升度和衡量购买X对购买Y的概率的提升作用。如下公式可见,如果X和Y相互独立那么提升度为1,提升度越大,说明X->Y的关联性越强
1.2 关联规则Apriori算法
Apriori算法是经典的关联规则算法。Apriori算法的目标是找到最大的K项频繁集。Apriori算法从寻找1项集开始,通过最小支持度阈值进行剪枝,依次寻找2项集,3项集直到没有更过项集为止。- 首先先找出1项集对应的支持度(C1),可以看出4的支持度低于最小支持阈值,先剪掉(L1)。
- 从1项集生成2项集,并计算支持度(C2),可以看出(1,5)(1,2)支持度低于最小支持阈值,先剪掉(L2)
- 从2项集生成3项集,(1,2,3)(1,2,5)(2,3,5)只有(2,3,5)满足要求
2. mlxtend实战关联规则
关联规则目前在scikit-learn中并没有实现。这里介绍另一个python库mlxtend。2.1 安装
pip install mlxtend
2.2 简单的例子
import pandas as pd
item_list = [['牛奶','面包'],
['面包','尿布','啤酒','土豆'],
['牛奶','尿布','啤酒','可乐'],
['面包','牛奶','尿布','啤酒'],
['面包','牛奶','尿布','可乐']]
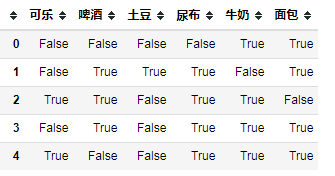
item_df = pd.DataFrame(item_list)
- 数据格式处理,传入模型的数据需要满足bool值的格式
from mlxtend.preprocessing import TransactionEncode
te = TransactionEncoder()
df_tf = te.fit_transform(item_list)
df = pd.DataFrame(df_tf,columns=te.columns_)
from mlxtend.frequent_patterns import apriori
# use_colnames=True表示使用元素名字,默认的False使用列名代表元素, 设置最小支持度min_support
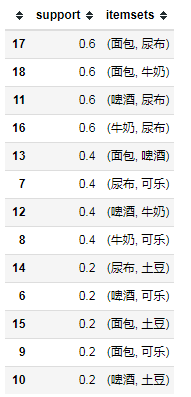
frequent_itemsets = apriori(df, min_support=0.05, use_colnames=True)
frequent_itemsets.sort_values(by='support', ascending=False, inplace=True)
# 选择2频繁项集
print(frequent_itemsets[frequent_itemsets.itemsets.apply(lambda x: len(x)) == 2])
from mlxtend.frequent_patterns import association_rules
# metric可以有很多的度量选项,返回的表列名都可以作为参数
association_rule = association_rules(frequent_itemsets,metric='confidence',min_threshold=0.9)
#关联规则可以提升度排序
association_rule.sort_values(by='lift',ascending=False,inplace=True)
association_rule
# 规则是:antecedents->consequents
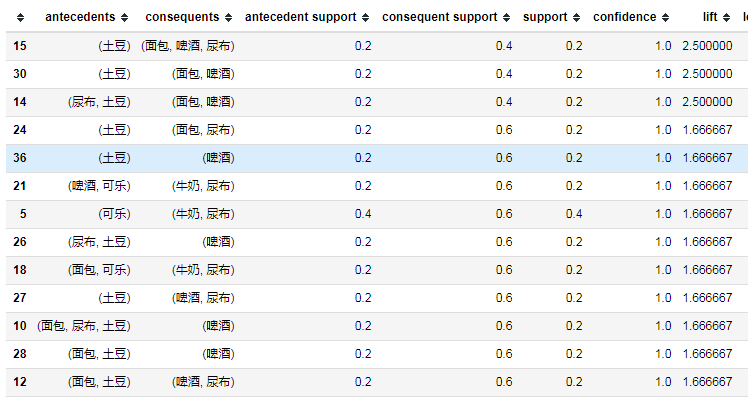
选择出来关联规则之后,根据提升度排序后,可能最高提升度的规则是在我们常识范围内,那这个规则的价值就不高。所以我们要在产生的规则中根据业务特点进行筛选,像开篇提到(啤酒->尿布)完全不同的品类之间的关联。笔者最近用关联规则分析用户的体检报告记录,也得出了关于各个病症的有意义的关联,如并发症,不同病症相互影响等。3. 总结
本分介绍关联规则的基本概念和经典算法Apriori,以及python的实现库mlxtend使用。- 关联规则用于分析数据集各项之间的关联关系,想一想啤酒和尿布的故事
- Apriori通过迭代先找1项集,用支持度过滤项集,逐步找出所有k项集
作者简介:wedo实验君, 数据分析师;热爱生活,热爱写作
赞 赏 作 者



点击下方阅读原文加入社区会员










