
容灾系统的重要目标在于保证系统数据和服务的“连续性”。当系统发生故障时,容灾系统能够快速恢复服务和保证数据的有效性。为了防止天灾人祸、不可抗力,在同城或异地建立对应的IT系统,其中最核心的工作是数据同步。本文选取应用层容灾的场景中,对于哪些数据表需要跨云同步,哪些数据表不需要跨云同步的问题进行探讨。通过一个具体的案例,帮助读者更好地梳理同步表和过滤表的方法,以满足应用层的业务容灾需求。本文探讨的场景是基于阿里云构建的应用层容灾,涉及到以下关键术语:Sequence:全局唯一序列号ID,在分布式系统里面应用广泛,可用于交易流水号,用户ID等。在搜索, 存储数据, 加快检索速度等等很多方面都有着重要的意义。这个ID常常是数据库的主键,要求全局唯一、支持高并发、容错单点故障。为了提高性能,应用层通常每次从数据库中获取一批序列号(比如1万个),存放到应用内存中使用,避免频繁访问数据库。内存中的序列号使用完成后,再次从数据库中进行获取新的一批序列号。
在项目中会发现,应用软件开发商更关注业务逻辑的实现,对于云产品使用的最佳实践以及容灾能力的了解程度,可能和我们的预期存在一定的差异。而梳理过滤表,主要由应用开发商来执行,在梳理过程中有几个常见的问题:设计和开发时期,开发人员应该如何做来减少容灾时候不同步的过滤表?
部署和运维时期,运维人员应该从哪些角度来确保过滤表的完整性和正确性?
在项目中,往往受限于工期和生产系统稳定性运行的约束,应用开发商和云平台厂商即便清楚设计和开发的最佳实践,也比较难限时完成改造。因此部署和运维期的时候,梳理过滤表和准备应急预案,是容灾演练的重点工作项。我们来分析一下,如果梳理过滤表错误,可能对应用层容灾有什么影响?前面我们已经介绍了应用容灾中哪些表不同步的必要性,本节我们来探讨如何梳理和设置过滤表。以下分析是比较理想的情况,实际项目中会有一些差别。如下是阿里云数据数据传输服务DTS产品公开的资料文档。
接下来我们从应用开发商比较关注的几个阶段,分析如何有效性地基于云容灾来交付应用软件。下图为异地容灾主备架构下,同步表和过滤表的配置逻辑说明。
下面分析一个异地容灾的项目中,由于过滤表清单梳理错误,导致业务异常问题及处理经验,便于读者对数据表是否需要跨云同步更有体感。在阿里云容灾平台ASR-DR对某个应用执行容灾切换(RDS MySQL读写权限从Cloud A切换至Cloud B)后,业务请求在备中心(Cloud B)时,业务报错,数据库提示“主键冲突”。我们根据问题处理的先后顺序,对问题定位过程进行分析。问题结论:备中心应用使用了过期的交易流水号ID,导致的写数据库出现“主键冲突”。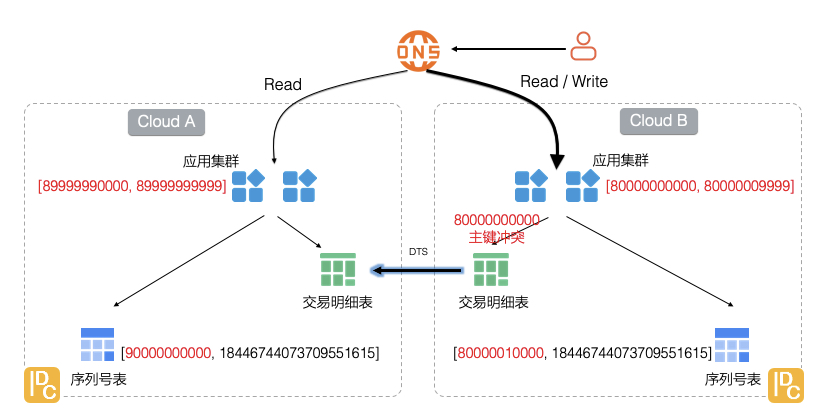
问题结论:管理全局唯一性序列号的数据表xx_table被错误地加入到了不做跨云同步的过滤表清单主中心和备中心同步数据完成后,断开同步链路,手动设置备中心数据库为只读。
重新部署改造后的应用,在只读模式下,验证应用启动成功,并且业务请求失败(符合预期)。
手动设置备中心数据库为读写,业务请求成功,检查应用是否成功重新获取到有效序列号。
重新配置主中心和备中心数据同步链路。


阿里云的两地三中心、异地多活等高可用架构通过了多年双十一大促的考验。目前阿里云向全球用户开放这些高可用架构的技术红利,帮助用户的IT系统更健壮。欢迎有志人士加入我们,有兴趣的同学可以投递简历到xiangdi.lyc@antfin.com
从实战角度出发,以企业应用环境为主线,深入介绍MYSQL的使用技巧和调优策略,最大限度发挥MySQL的性能优势,适合MySQL DBA或者运维相关开发者。
点击“阅读原文”开始学习吧~









