点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:AI科技评论
Emil Wallner是一名自学成才的独立机器学习研究员。在这篇文章中,他将向我们展示,自己是如何围绕专业级显卡NVIDIA RTX A6000,一步一步搭建起一个仅需价值19万人民币的机器学习工作站。RTX A6000具备了RTX消费级显卡上同样的光线追踪特性,并与数据中心使用的A40进行了区分。RTXA6000采用了完整的GA102芯片,这意味着它拥有10752个CUDA核心,可提供高达38.7 TFLOPs的单精度计算性能(比消费级显卡 top-1 GeForce RTX 3090高出3.1 TLFOPs)。图注:RTX A6000和RTX 3090的性能对比(来源:expreview)它拥有4个NVIDIA RTX A6000和一个32核的AMD EPYC 2、192 GB的GPU显存和256GB的RAM。我花费了2.5万欧元(约19万人民币)来搭建它,其中关键部件大概2万欧元。GPU
在AMD的GPU机器库变得更加稳定之前,NVIDIA是唯一的选择。由于NVIDIA最新的Ampere微架构明显优于上一代产品,因此我仅采用了Ampere GPU。- 专业级(prosumer,或称生产性消费级):A6000
- 消费级:两个RTX 3080s / RTX 3090s
- 企业级:8个A100或A6000(PCIe),或16个A100(SXM4),或20个A100(基于PCIe的模块化刀片节点)
当然,你也可以尝试突破这些限制,但会增加风险,并牺牲可靠性和便利性。- PCIe转接卡的主板限制:14个GPU(每个GPU x8 Gen 4.0)
- 堆叠的显卡彼此相邻:4个A6000 / 3070或2个3080/3090
- 消费者供应量:1个GPU(大多数商店只允许购买一个消费级GPU,并且通常仅在发布后3到12个月内可购买)
我尝试过购买5台RTX 3090,由于供应问题等待了四个月之后,我选择了采用四台RTX A6000。根据Lamda Labs和Puget Systems的说法,双槽式鼓风机3080和3090太热,无法在标准尺寸的主板上可靠地将四个相邻的鼓风机安装在一起。因此,你需要采用PCIe转接卡、水冷设备或限制电源使用。在露天设备中使用PCIe转接卡会使硬件暴露在灰尘下。水冷式则需要维护,并且在运输过程中有泄漏的危险。限制功率是非标准的做法,可能会导致可靠性下降和性能损失。对于3台以上的GPU工作站,很多人选择300W或更低功率的显卡,即RTX 3070及以下,或A6000及以上。由于大多数主流的云GPU都是16 GB的GPU内存,因此当今的大多数模型都是为16 GB的显卡设计的,并且我们正朝着40 GB的方向发展。因此,具有最低内存的卡在重写软件中会有增加的开销,以适应较低的内存限制。人们在网上看到的超过5个GPU消费级设备,通常是具有多种电源的加密设备。由于加密装置不需要高带宽,因此它们使用特定的USB适配器来连接GPU。这是一个无需电力即可传输数据的适配器。因此,GPU和主板的电源是分开的,从而减少了混合电路的问题。但是,适配器的质量通常很差,小的焊接错误可能会损坏硬件并着火。而且,特别不建议将它们用于需要PCIe转接卡以实现75W功率的机器学习工作站。加密工作站还使用了一些标准质量较差的采矿电源或翻新企业电源。由于人们倾向于将它们放置在车库或集装箱中,因此他们会承受额外的安全风险。专业级显卡和企业级显卡的功能
对于Ampere系列,NVIDIA很难将高端消费卡用于具有2个以上GPU的工作站。很多迹象都表明了这一点,比如:3槽宽度、高功率,并且有多家制造商中断了3090的2宽度鼓风机版本。因此,专业级和企业级Ampere卡的主要卖点是支持3个以上GPU工作站,进行24/7/365的工作负载。- 快1.1-2倍(取决于GPU、二进制浮点格式和模型)
- NVSwitch(A100 SXM4),更快的GPU到GPU的通信
80GB GPU可以提供针对特定型号的优势,但是很难说它们是否具有足够的计算能力来从大型模型中有效受益。最安全的选项是40GB版本。通常,我不会针对NLP、CV或RL设置特定的工作负载。它们的性能会有所不同,但是由于机器学习的格局变化如此之快,因此不值得针对特定的工作负载进行过度优化。有关更深入的比较,请阅读Tim Dettmers的GPU指南。请特别注意Tensor Core、稀疏训练、限制GPU功率和低精度计算等部分的内容。Tim Dettmers的GPU指南:https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/服务器限制
消费级设备主要受电源限制,而服务器设备主要受重量、机壳大小和网络开销的限制。- PCIe服务器的限制:10个双插槽GPU(标准服务器的宽度)
- 重量:10个PCIe GPU或4个SMX4 GPU(30千克)
- PCIe服务器机箱的联网限制:8个双插槽GPU(2个双插槽用于联网)
- SXM4服务器的机箱数量限制:16个GPU(168千克)
这里的关键限制是网络开销。一旦连接一台或多台服务器,就需要软件和硬件来管理系统。我强烈推荐观看Stephen Balaban关于构建用于机器学习的GPU集群的概述视频。Building a GPU cluster for AI:https://www.youtube.com/watch?v=rfu5FwncZ6s带有8台SXM4的服务器重约75kg。因此,理想情况下你得拥有一台服务器升降机。与PCIe服务器随附的更多标准零件相比,SXM4更难以维修。A100和A6000也有不带内置风扇的版本。这些需要带有十几个10K + RPM风扇的服务器机箱。由于可以热插拔风扇,因此它们将具有更多的容错能力。速度基准
Lambda Labs拥有最佳的GPU基准测试和整体基准测试。基准采用了PyTorch的几个模型的半精度平均值。- https://lambdalabs.com/blog/tag/benchmarks/
- https://lambdalabs.com/gpu-benchmarks
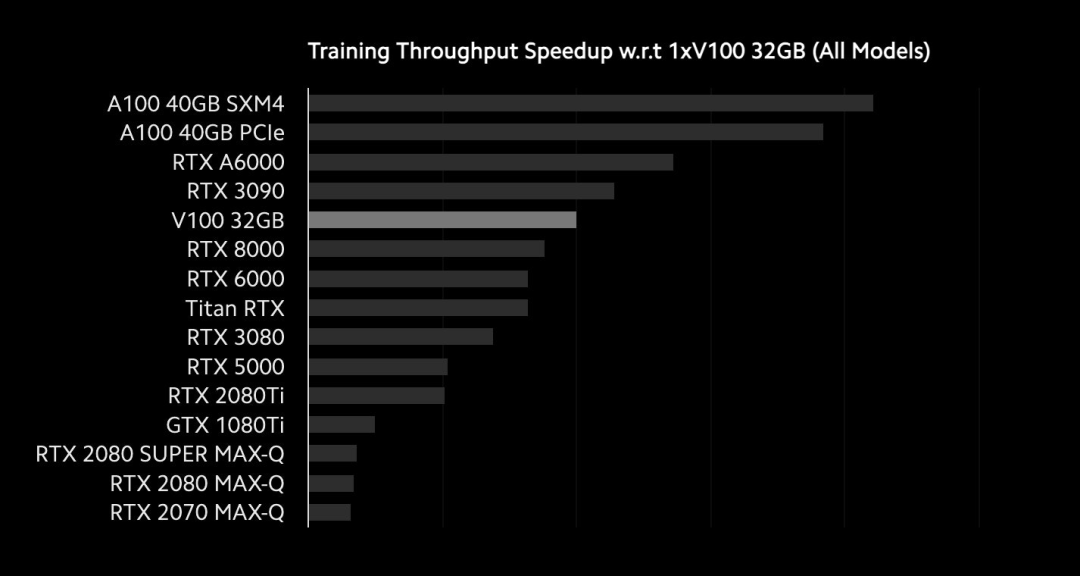
在速度方面,A100是A6000的1.4倍。但是A6000的速度是3090的1.2倍,是3080的两倍。另一个值得注意的基准是PCIe和SXM4之间的比较。NVIDIA的A100 PCIe只能连接到另一个GPU,而NVIDIA的A100 SXM4可以同时连接到8至16个GPU。
F16 PyTorch Lambda Labs 基准
从理论上说,NVIDIA的NVswitch和SXM4的带宽提高了10倍,但是在8-GPU设置下,与PCIe解决方案相比,它仅快了10%。由于每个GPU上SXM4的速度提高了8%,因此NVswitch的影响很小。对于8-GPU系统,这应该是很小的差异。Lamda Labs的首席执行官表示,对于大型集群中的某些用例,他们可以实现2倍的改进。因此,它主要针对多个8-GPU系统。具有数百个GPU规模的DGX A100 SuperPOD系统也值得研究。另外,在网络基准测试中,请注意GB / s和Gb / s的区别。GB / s比Gb / s快八倍。
GPU定价
定价近似于实际零售价,为简化起见四舍五入,没有增值税和折扣。- RTX A6000 / A40(48GB):€4500
- RTX 3090(24 GB):€1500-2000
- RTX 3080(10 GB):€800-1300
- RTX 3070(12 GB):€700-1000
NVIDIA还提供了创业和教育折扣,因此每个GPU可以节省15-30%。我在4 x RTX A6000上节省了约4000欧元。SMX4卡作为8 GPU服务器的一部分出售,由于定制的GPU到GPU的通信使其价格更高,因此上述每个GPU的价格是近似的。- €240-340k:8 x A100 SXM4(80 GB)
- €120-170k:8 x A100 SXM4(40 GB)
- €90k:8 x A100 PCIe(40 GB)
- €50k:4 x A100 PCIe或8 x RTX A40(无风扇RTX A6000)
- €15k:4 x RTX 3090(加密风格或上限性能)
- €5k:1 x RTX 3090或2 x RTX 3080
开始时,我们通常将机器放在同一个房间里,以应对不便之处。随着机器扩展,我们将需要更多基础架构。我们可以将其移动到单独的办公室中,然后将其放置在数据中心中,从并置开始,然后从1个数据中心攀升至4个数据中心,以提高容错能力。我发现4个GPU的声音太大,无法在办公室或家里散热而产生过多的热量。想想看,一台带有热风的小型吹叶机,相当于一个1600W的散热器。数据中心配置的起始价格为每个GPU每月80-250欧元左右,其中包括每个GPU 25欧元的电费。你可以在此处查询所有本地数据中心配置的报价(https://www.datacentermap.com/quote.html)。如果你计划在4个以上的GPU上运行24/7/365的工作负载,我强烈建议你这样做。你可以像购买PC一样轻松地为4 GPU服务器购买零件。准系统5+ GPU ML服务器的价格约为7,000欧元。CPU
AMD的内部带宽是Intel的5倍。而且既便宜又更好。大多数Ampere 机器学习服务器都使用AMD。- 专业级:Ryzen Threadripper第三代,带有sTRX4,以及用于第一代Pro版本的sWRX8插槽
对于1-GPU系统,Ryzen非常出色;对于2-4 GPU PC的系统,请搭配Threadripper。对于5个以上的GPU系统和服务器版本,请使用EPYC。Threadripper的速度比EPYC快,但EPYC的存储通道是RDIMM的两倍,并且能耗更低。如果你打算将计算机用作服务器,那么我建议选择EPYC。我最终买到了32核的AMD EPYC 2 Rome 7502P。对于处理器,我将每个GPU对应八个内核作为一个粗略的指导。另外,请注意它们是否支持单处理器、双处理器或两种处理器设置都支持。对于散热,Noctua风扇是最安静、性能最高且最可靠的风扇。它们也很大,因此请确保它们适合你的RAM和机箱。对于RGB风扇,我喜欢Corsair的多合一(AIO)液体CPU散热器。它的颜色是可编程的,并且系统释放了CPU周围的空间。它使用了防冻液,泄漏风险很小。所有Threadripper和EPYC CPU具有相同的尺寸,从而使散热器兼容,但是你可能需要安装支架。另外,请检查散热器是否支持你选择的CPU的功率。- 锐龙5000:Noctua NH-D15或Corsair H100i RGB PLATINUM
- Threadripper:Noctua NH-U14S TR4-SP3或Corsair Hydro系列H100x
- EPYC:Dynatron A26 2U(用于服务器)
由于成本、维护、冻结风险、运输风险和缺乏灵活性,我避免采用定制的液冷。主板
- 锐龙5000:MSI PRO B550-A PRO AM4(ATX)
- Threadripper 3rd Gen:华擎TRX40 CREATOR(ATX)
- Threadripper Pro:ASUS Pro WS WRX80E-SAGE SE(ETAX)
- EPYC 2:AsRock ROMED8-2T(ATX)(我的主板)
如果你打算将机器学习工作站用作普通PC,并希望内置支持WIFI、耳机插孔、麦克风插孔和睡眠功能,那么最好使用消费级或专业级主板。就我而言,我使用了双重用途的专业级/服务器主板,该主板支持远程处理或智能平台管理接口(IPMI)。通过以太网连接和Web GUI,我可以安装操作系统,打开/关闭操作系统并连接到虚拟监视器。如果计划进行24/7/365工作负载,则IPMI是理想的选择。CPU插槽具有内置芯片组,专业级和消费级具有附加的芯片组以启用特定的CPU或功能,例如,Ryzen的B550和Threadripper的TRX40。对于Ryzen 5000版本,理想的是具有BIOS刷新按钮。否则,你需要更早的Gen Ryzen CPU来更新BIOS以与Ryzen 5000兼容。5+ GPU的server-only主板很难单独购买。消费级设置是模块化的,而较大的服务器则是集成的。主板的标准尺寸为ATX,尺寸为305×244毫米,非常适合服务器机箱和PC。我主要关注标准尺寸的ATX板,以避免出现任何机架间距问题。其他的外形尺寸因制造商而异,因此你在机箱方面会受到更大的限制。对于消费级机箱而言,这并不是什么大问题,但是对于服务器机箱而言,其高度不会超过ATX的305毫米。
PCI Express(PCIe)
下面是我用的主板:AsRock ROMED8-2T(ATX)需要着重注意的是要插入GPU的PCIe插槽,也就是上面的垂直灰色插槽。连接处位于GPU的最右侧。你能看到,RAM插槽和第一个GPU之间的间隙很紧。当你在7插槽板上有四个双宽度的GPU时,第4个GPU将超过板的底部。因此,您需要一个支持8个PCIe扩展插槽的PC或服务器机箱。对于两个RTX 3090三插槽卡,你的第一个GPU会覆盖前三个PCIe插槽和空插槽,而第二个GPU将覆盖最后三个插槽。如果你打算买一个NVlink来连接两个GPU,它们通常会有2插槽、3插槽和4插槽几个版本。在上图中,你需要两个 2-槽桥。而对于中间有间隙的三槽卡,你需要一个4-槽桥来满足卡的宽度、3插槽以及1插槽间隙。- PCIe物理长度:图中每个插槽的长度为x16,GPU的标准长度为89mm。
- PCIe带宽:有时,你有一个16插槽的长度,但只有一半的插槽有连接到主板的管脚,使其成为x8带宽的x16插槽。作为参考,加密钻机将使用x16适配器,但x1带宽。
- 生成速度:上面的板是4.0代。每一代的速度往往是上一代的两倍。NVIDIA的最新gpu是gen4.0,但在实际应用中在gen3.0板上的性能相当。
- 多GPU要求:对于4-10 GPU系统,通常建议每个GPU至少x8 Gen 3.0。
大多数人需要的另一个东西是PCIe通道的总量,即总的内部带宽。这里给一个网络、存储和多GPU容量的粗略指示。主板制造商会使用PCIe通道来优先考虑某些功能,例如存储、PCIe插槽、CPU—CPU直接的通信等。作为参考,一个GPU将使用16通道,一个10 GB/s以太网端口使用8通道,一个NVMe SSD将使用4通道。机箱
最常用的机器学习工作站机箱是Corsair Carbide Air 540,而对于消费级服务器,则是Chenbro Micom RM41300-FS81。从声音、灰尘和运输的角度来看,这两种情况是理想的。两者都能容纳RTX3090,但你需要为Chenbro配置一个后端电源连接器。我从Thermaltake Core P5钢化玻璃版开始。从苦行僧的角度来说,这是最好的。但它相当笨重,不能沾染灰尘。考虑到GPU的热量和噪音,我决定将其转换成带有Chenbro机箱的服务器,并将其放入数据中心。GPU之间的空间比主机箱气流的影响更大。如果你采用了3+3080/3090,你可能需要开放的加密工作站设置。然而,这是非常嘈杂和容易沾染灰尘的。理想情况下,你要把它放在一个隔音的房间里,安装冷却器和灰尘过滤器。Chenbro机箱盖上有两个120毫米2700转的风扇,为GPU创造了极好的气流。PSU、RAM和存储
如果你已经选好了GPU、CPU、主板和机箱,其余的组件会很容易挑选。电源:关于电源,我看了两个被认为是最好的供应商,EVGA和Corsair。我考虑了GPU的总功率,额外的250W,以及保险边界。这里有一个更精确的功率计算器(https://www.newegg.com/tools/power-supply-calculator/)。我最终得到了EVGA超新星1600W T2。RAM:我看了主板供应商的推荐,买了一些我可以在网上轻松买到的东西。建议用RAM填充可用的插槽,我希望RAM内存能匹配或超过相对应的GPU内存。据Tim Dettmers说,内存速度对整体性能影响不大。我用的是8 x Kingston 32GB 3200MHz DDR4 KSM32RD4/32ME,所以总共是256 GB。NVMe SSD:我检查了PCpartpicker和Newegg上评级最高的SSD。我的指导原则是在PCIe Gen 4.0的基础上每GPU配上 0.5 TB。我用了两个2 TB三星980 Pro 2到M.2 NVMe。硬盘驱动器:我选择了和SSD一样的策略,每个GPU对应有6TB的存储空间。最终我采用了2 x 12 TB Seagate IronWolf Pro、3.5英寸、SATA 6Gb/s、7200 RPM、256MB缓存。对于更严格的基准测试,可以研究磁盘故障率。NVlink:这是一个很好的方法,可以在特定的工作负载上提高百分之几的性能。不过,它没有结合两个GPU的内存,只是一个营销误导。搭建和安装
搭建工作站最困难的部分是买到各种零件。(我咋觉得最困难的是钱 )把这些部件组装起来只需要不到一个小时,但是为了安全起见,你可能需要多花几个小时。我用远程管理系统安装了软件。当我把以太网线插入路由器时,它给我的路由器分配了一个IP地址,然后我把这个IP地址放进浏览器,我可以访问一个web界面来更新BIOS并安装了Ubuntu20.04 LTS。然后我为所有GPU驱动程序和机器学习库等安装了Lambda堆栈,强烈推荐!如果你使用的是IMPI,请在BIOS中将VGA输出更改为internal。否则,如果不删除GPU,就无法使用IMPI中的虚拟监视器。
)把这些部件组装起来只需要不到一个小时,但是为了安全起见,你可能需要多花几个小时。我用远程管理系统安装了软件。当我把以太网线插入路由器时,它给我的路由器分配了一个IP地址,然后我把这个IP地址放进浏览器,我可以访问一个web界面来更新BIOS并安装了Ubuntu20.04 LTS。然后我为所有GPU驱动程序和机器学习库等安装了Lambda堆栈,强烈推荐!如果你使用的是IMPI,请在BIOS中将VGA输出更改为internal。否则,如果不删除GPU,就无法使用IMPI中的虚拟监视器。结论
亲自搭建一个工作站,你会学到很多东西,成为一个受过更多教育的消费者。另外,这是一个宝贵的技能。英伟达正在努力让3+GPU工作站能使用上高端消费卡。对于家里有服务器的专业级工作站,我会选择4 x 3090的开放工作站。空间更有限的的话,就选择2 x 3090的工作站。如果有了更大的预算,4 x RTX A6000是一个不错的选择,但考虑到噪音和热量,我会选择服务器解决方案,并将其放置在数据中心。相比A100,A6000 / A40的性价比更高。SMX4太笨拙,与PCIe版本相比性能微不足道。我希望大家能构建包含大型集群的透明基准,以了解实践中的好处。https://www.emilwallner.com/p/ml-rigCVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-
Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer
+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看






