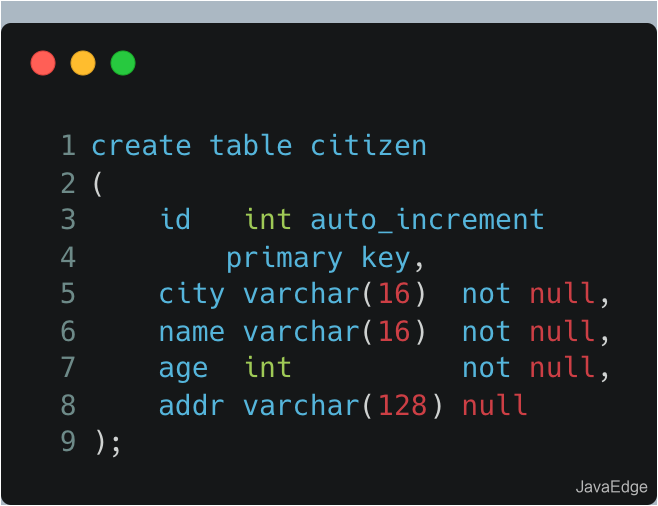
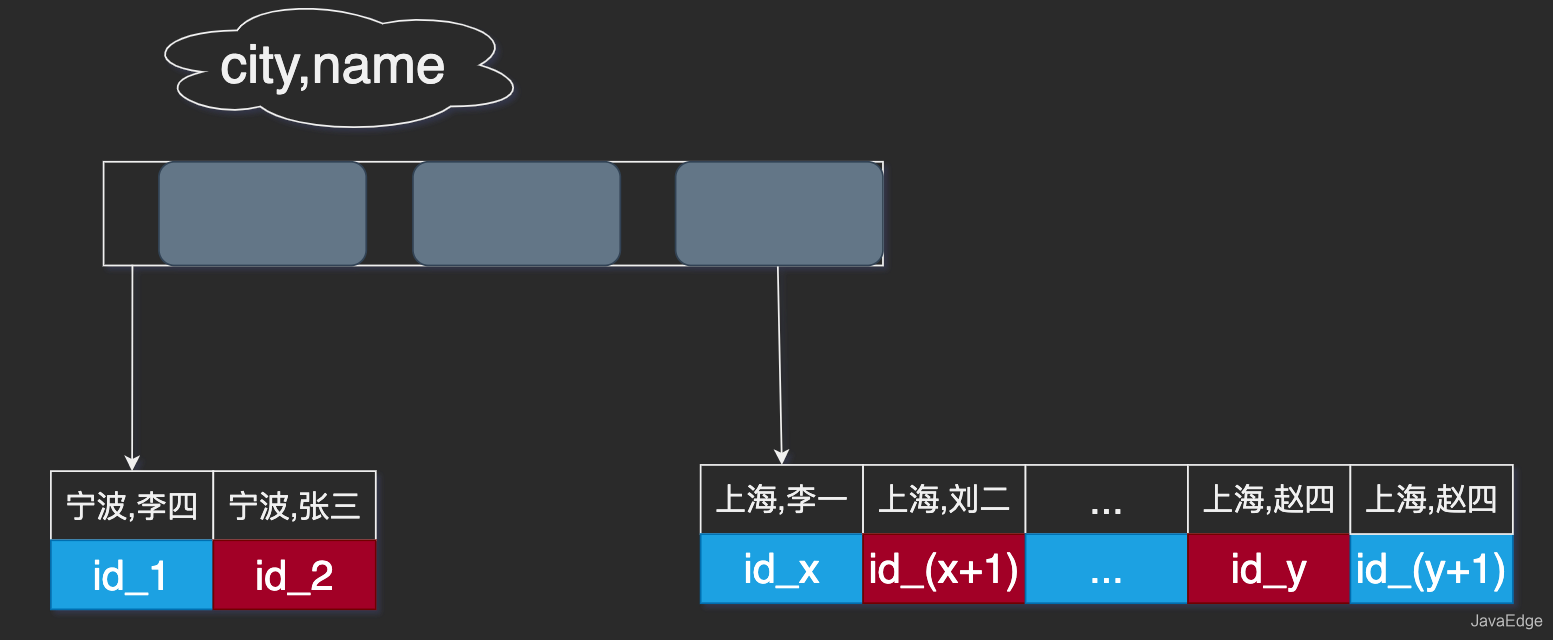
感觉很容易,随手SQL这么一写:
诶,这语句看着简单而朴实,一个需求好像就完美解决了。但为了显示自己强大的性能优化水平,考虑到要避免全表扫描,于是又给
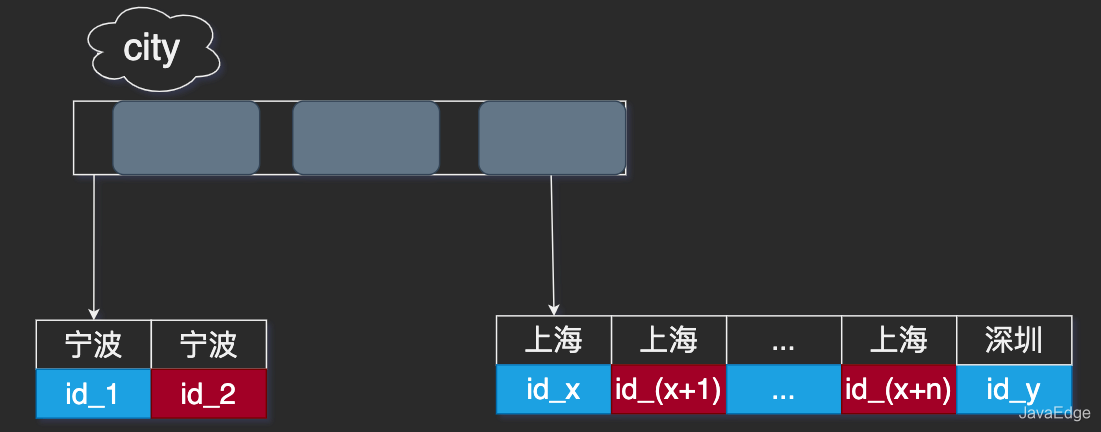
city
字段加索引。
建完索引,自然还需要使用explain验证一下:
explain select city, name, age from citizen where city ='上海' order by name limit 1000;+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+|1| SIMPLE | citizen | NULL | ALL | city | NULL | NULL | NULL |32|100.00| Using where; Using filesort |+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+1 row in set,1 warning (0.00 sec)
1
2
3
4
5
6
7
1
2
3
4
5
6
7
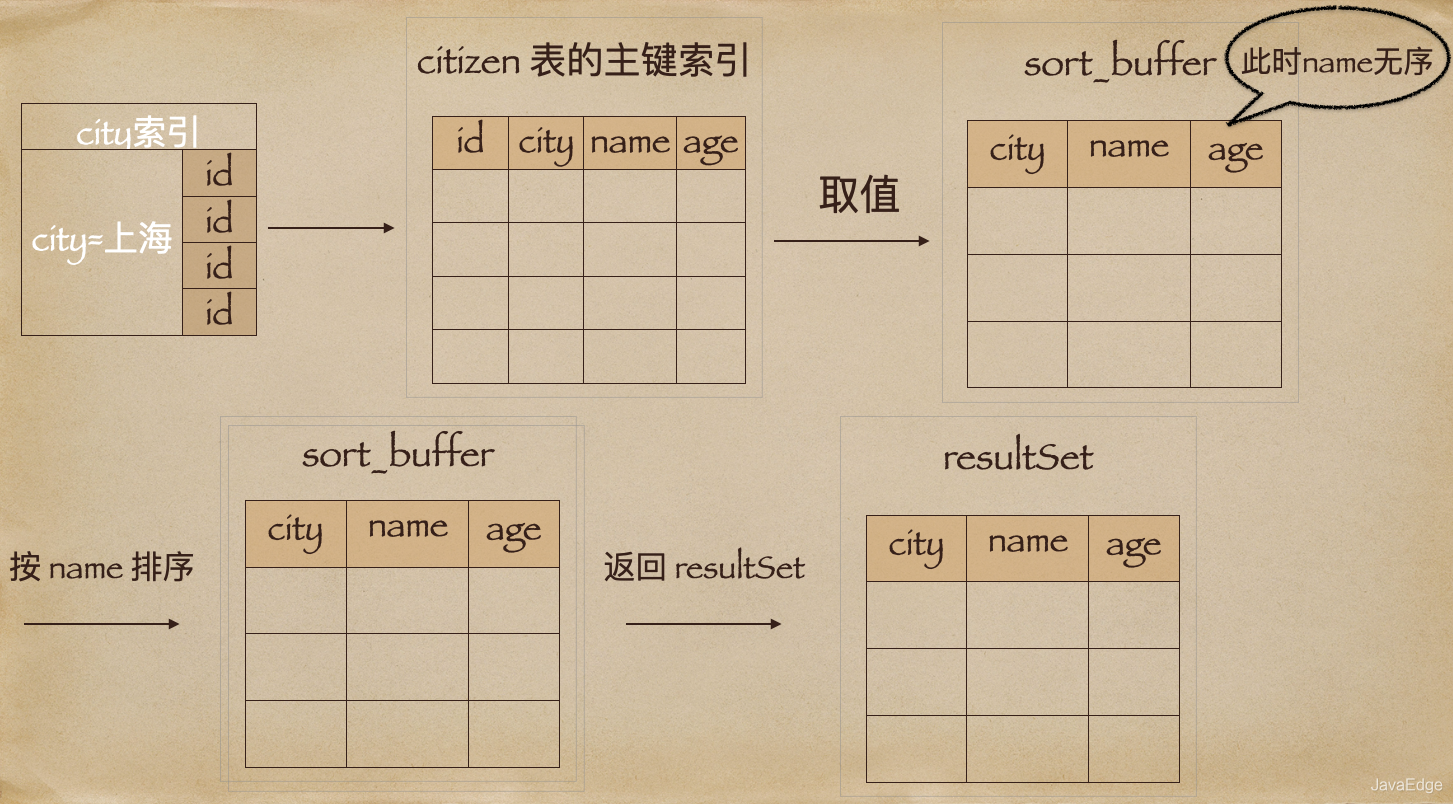
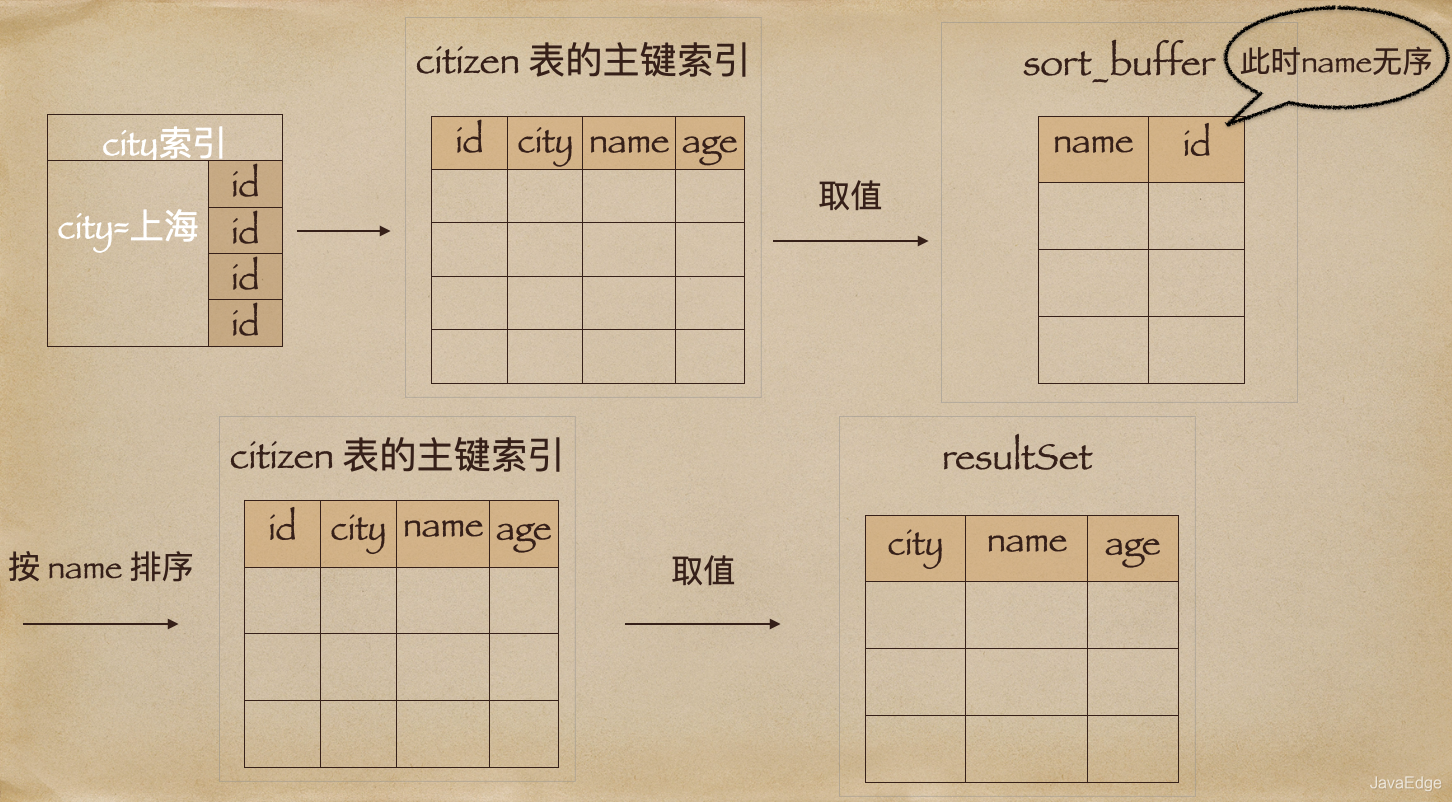
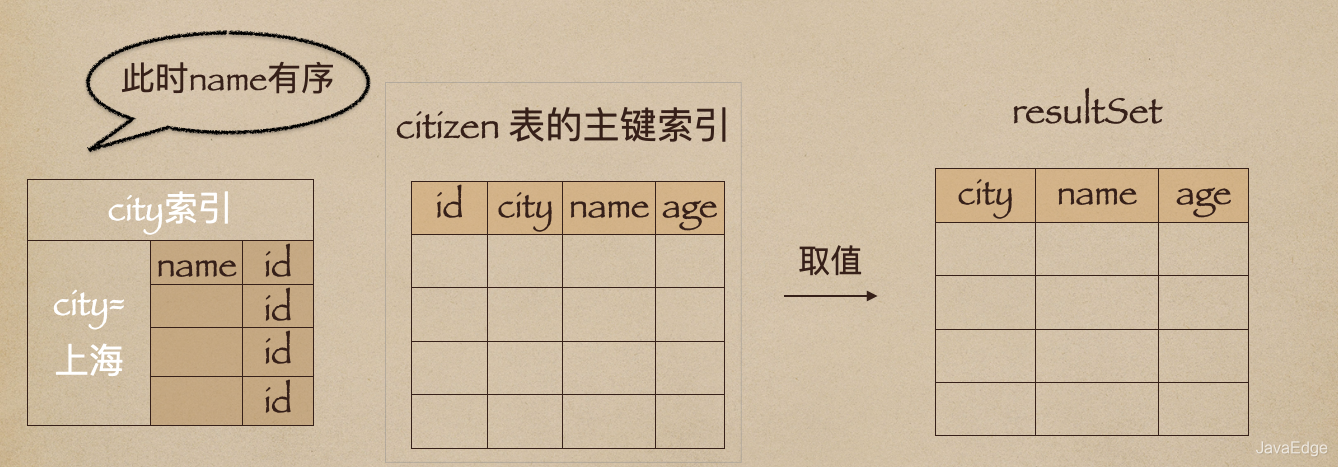
Extra字段的
Using filesort
表示需要排序,MySQL会给每个线程分配一块内存用于排序,称为
sort_buffer
。
explainselect city, name, age from citizen where city ='上海'orderby name limit1000;+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+| id | select_type |table| partitions |type| possible_keys |key| key_len | ref |rows| filtered | Extra |+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+|1|SIMPLE| citizen |NULL| ref | city,name | name |51| const |4000|100.00|Usingindex condition |+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+1rowinset,1 warning (0.00 sec)
explainselect city, name, age from citizen where city ='上海'orderby name limit1000;+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+| id | select_type |table| partitions |type| possible_keys |key| key_len | ref |rows| filtered | Extra |+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+|1|SIMPLE| citizen |NULL| ref | city,name,age | age |51| const |4000|100.00|Usingwhere;Usingindex|+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+1rowinset,1 warning (0.00 sec)