
近年来,随着企业数字化转型升级,零售、金融等行业积累了大量的业务数据。如何从数据中发现价值,辅助业务决策,各行各业都在积极地探索。而高性能计算、智能化算法等技术的快速发展,也为企业从海量数据中低成本地发现数据价值提供了技术可行性。但是在机器学习应用实际落地过程中,仍然暴露了一系列问题,亟待系统化解决:
应用碎片化:目前,很多企业都开始构建或已经构建了企业级数仓。但是,实际在数据建模过程中,部门间数据、硬件、建模过程仍然互相独立,类似烟囱式的应用,造成了企业资源的严重浪费。此外,各团队都需要端到端完成AI生产链路,团队间无法沉淀、分享、复用建模能力,整体建模效率低下。
工程化复杂:企业智能化应用落地过程中,除了算法建模,还需要展开大量工程领域强相关的工作,例如环境的搭建、任务调度、模型部署、多租户等。算法分析师更加擅长数据分析、算法、模型等,相关工程化工作,需要耗费他们非常多的精力或者需要配置单独的工程化团队来实现,这些都对算法场景快速落地提出了挑战。
建模门槛高:企业很多业务部门,现阶段都不是以算法为核心,更多依赖于算法预测能力来辅助和优化业务决策。类似的业务团队并没有非常资深的算法分析师,也缺乏对于建模过程及相关技术栈的深入理解,使得想要挖掘数据深度价值的门槛比较高。
基于上述需求,网易有数团队整合内外部资源,依托于数据生产力平台,沉淀集团标签预测、推荐、风控等场景建模经验,推出了一站式机器学习平台(Easy-AI),帮助客户更快、更便捷、更智能的挖掘数据价值,赋能企业AI转型升级。
2.1产品框架:
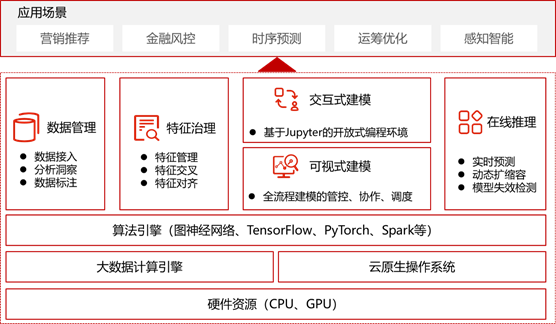
平台整体围绕一站式建模设计。底层基于容器化架构,集成大数据计算引擎、深度学习计算引擎、图计算引擎等,为建模业务提供高性能算力;功能层覆盖数据接入、清洗、特征治理、模型训练、模型推理等环节,提供数据管理、特征管理、交互式建模、可视化建模、在线推理等功能模块;顶层围绕建模场景,提供通用化能力,覆盖推荐、风控、运筹优化等业务。
2.2产品功能:
(1)交互式建模
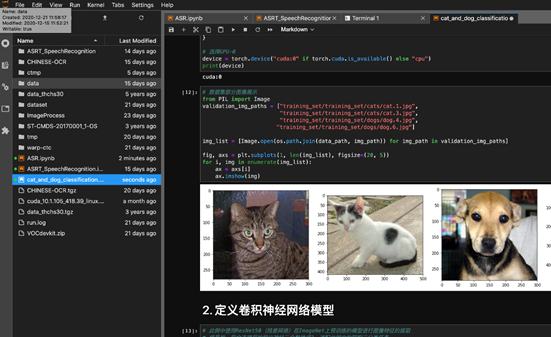
算法开发调试是机器学习建模过程中非常重要的环节。简单易用的开发环境对于提高算法工程师的开发效率,加速业务落地具有重要意义。平台基于云原生架构,支持用户动态创建Jupyter Notebook环境,供算法工程师开发和调试算法模型。
此外,为了给用户提供沉浸式的编程体验,平台辅助提供了便捷的数据读写、统一的镜像管理、开放的Web IDE环境等服务。
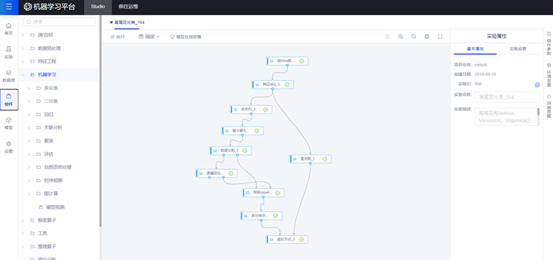
(2)可视化建模
可视化建模平台支持对结构化、非结构化等多模态数据进行数据价值的深度挖掘,并对挖掘过程进行全流程、多版本、可视化地管控、溯源、调度。该模块提供如下能力:
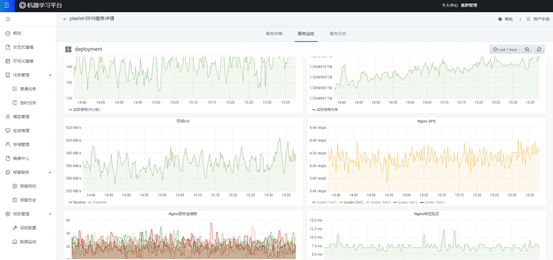
(3)在线推理引擎
离线模型训练后,平台支持模型多版本的统一管控,支持模型对比、模型分析报告等服务,并可将最优模型部署成在线推理服务。
在推理环节,平台基于分片策略的分布式推理架构支持高并发场景下ms级实时响应。模型更新时,支持模型平滑更新(滚动升级、蓝绿升级、热更新)、在线资源扩缩容等功能,在资源冗余、服务升级稳定性、模型效果等维度满足用户个性化需求。
此外,平台提供完善的资源监控和报警机制,保障推理服务的稳定性。
机器学习平台旨在打造一站式建模能力,帮助算法分析师更快、更便捷、更智能的挖掘数据价值。
统一的数据管理:依托于数据平台,机器学习平台提供数据表、图片、文本等多模态数据的统一管控,并支持数据采集、数据管理、数据地图、数据标注等能力,并串联可视化建模、交互式建模、推理服务等模块支持数据的快速读写。
开放的环境搭建:平台提供镜像管理服务,支持内置镜像及用户自定义镜像,支持快速集成R、Spark、TensorFlow等计算框架,针对数据分析类场景,内置pandas等依赖包,方便用户快速搭建模型开发环境。
低门槛的模型开发:兼顾用户差异化的需求,一方面,平台提供jupyter notebook和WebIDE支持用户沉浸式编码;另一方面,平台提供拖拽式的可视化建模,内置数据分析和建模算子,并支持算子自定义,快速构建pipeline,降低用户建模门槛。
高性能的模型训练:针对广告、推荐等海量数据场景,平台支持分布式模型训练,支持用户自定义GPU、CPU混编,支持超大规模稀疏化特征计算等。在任务调度中,平台支持将模型训练任务和数据计算任务进行串联,并自定义任务依赖和调度周期,满足业务实际场景需求。
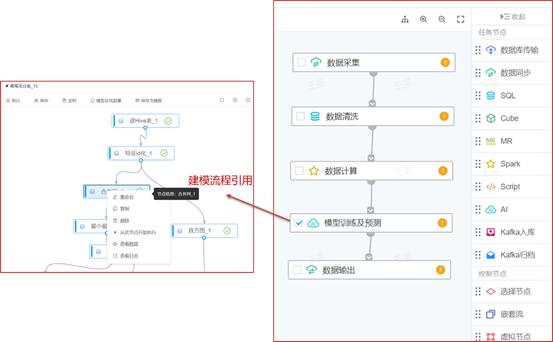
全周期的模型管控:离线训练模型后,支持将基于场景的多版本模型进行统一管控,并支持模型对比、模型效果评估,并产出模型分析报告。平台支持标准化格式的模型导入导出,包括PMML、SavedModel等。
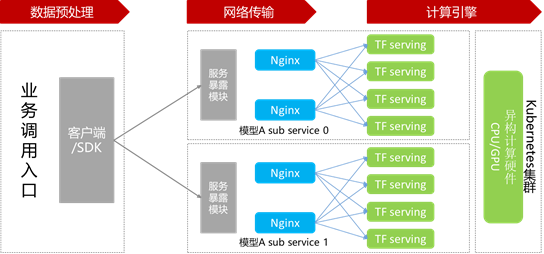
低延时的推理服务:平台支持将模型一键式部署成推理服务,减少工程化成本。推理引擎中,基于分片策略的分布式推理架构,提供ms级的响应延迟,有效支撑广告、推荐等实时预测场景。此外,平台提供模型的平滑升级,流量峰谷的在线扩缩容等功能。
为了进一步降低建模门槛、提升建模效率,平台逐步打造AI模型仓库,内置营销推荐、时序预测、运筹优化等模型,业务方基于模型,修改数据源,即可快速构建模型,实现模型真正的开箱即用。
此外,平台提供健全的监控报警体系,完善的数据、功能权限,灵活的系统部署方案,满足不同企业的差异化需求。
4.1工具场景化
目前平台整体定位于建模工具,距离业务价值较远。在商业化过程中,部分客户有数据、有场景,但是缺乏数据价值变现的能力。当前产品建设中,平台基于场景沉淀能力,覆盖推荐、时序预测、运筹优化等场景,提供场景化的工具产品。一方面,在上述场景中,平台开放模型仓库,提供建模模板,帮助客户开箱即用。另一方面,围绕场景化建模,平台提供差异化建模能力,例如在推荐场景中,基于业务离线、在线特征管理、特征交叉、特征对齐等场景需求,平台提供特征平台子产品,并结合在线机器学习提供分钟级模型更新服务(内部版本已开放)。
4.2建模智能化
平台整体目标是帮助用户更快、更便捷、更智能的发现数据价值。因此,在平台建设过程中,平台不断沉淀通用化能力,帮助用户更高效率的完成建模。在建模过程中,自动化地基于数据表提供数据分析报告,基于特征表完成特征交叉、特征降维、特征选择,基于算法完成参数搜索、模型评估及筛选;更近一步,基于用户提供的数据表,自动化的完成整个建模过程。(内部版本已部分开放)
经过网易内、外部业务的反复检验,有数机器学习平台已经成为一个成熟的一站式建模工具产品,能够快速支撑客户便捷研发、快速上线、稳定生产。同时全方位支撑TensorFlow、PyTorch、Spark等多种机器学习、深度学习框架,满足用户CV、NLP、营销推荐等场景需求。
目前平台在网易内部已支撑广告、推荐、文本分类、标签预测等100+建模场景;外部商业化,已服务金融、零售、物流、工业等行业客户,取得了良好的客户反馈。
后续文章中,机器学习团队会逐步分享系统技术实现,并围绕广告、推荐等实际场景,解析场景差异化问题和解决方案。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
欢迎加入 DataFunTalk 机器学习 交流群,跟同行零距离交流。识别二维码,添加小助手微信,入群。关于我们:
DataFunTalk
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,10万+精准粉丝。
🧐分享、点赞、在看,给个3连击呗!👇









