
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
requests库可以说是Python中使用最广泛的HTTP库了。然而,我相信大多数用户并不知道的是,requests当前稳定版本接受长度小于Content-Length头所给出的长度的响应。如果你自己不仔细检查的话,你可能都没注意就使用了损坏的数据。我亲身经历了这一点,同时这也是我为什么写这篇文章的理由。让我们看看为什么当前requests版本没有做这个检查(这是一个特点,不是bug),和如何在你的脚本中进行手动检查。
什么是Content-Length头?
复习一下,在HTTP协议中,Content-Length头说明了请求或响应体的长度。它以8位字节给出,其中1个8位字节是8位。为了简单起见,通篇文章我将使用术语字节而不是8位字节。通常,Content-Length头用于通知接收方当前请求(或响应)何时完成。没有它的话,你不知道你是否接收到了所有的数据或者你不知道是否有更多的数据需要读取。当然,服务器可以在每个请求或响应结束后断开连接(HTTP1.0就是这样的),但是到了HTTP1.1,除非另有声明所有的连接都被视为持续性的。这显著地加快了通信速度,因为你无需为每个请求单独打开一个连接。
在阅读完上述段落之后,下面的问题可能会出现在你的脑海中:
如果我收到Content-Length的值比收到的字节数少会发生什么?
在某些情况下(网络或服务器端错误),服务器可能会在发送完整消息之前突然断开连接。HTTP1.1 RFC指出:
当允许消息体的消息中给出Content-Length时,其字段值必须与消息体中的字节数完全匹配。当接收并检测到无效长度时,HTTP1.1用户代理必须通知用户。
因此,一旦接收到比Content-Length头部中规定的更少的字节,人们希望能收到通知。为了检查这一点,我启动一个简单的HTTP服务器,它总是返回下面的响应,然后断开连接:

然后,我编写了一个Python脚本,它向服务器发送GET请求,检查它是否成功,并打印接收到的数据:
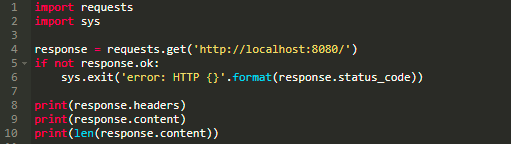
当你运行它时,它成功了,而且不会引发异常:

那么,这难道就是所有客户端的行为方式吗?为了确定,我使用curl进行尝试:

为了找到答案,我使用了reqwest,它是Rust的HTTP库。我的测试客户端的完整实现可以在这里找到。当我运行它时,它也提示我这种差异:
requests在这里发生一些可疑的事情...
为什么requests库不警告我?
当你搜索requests库时,您会发现大量令人惊讶的issues。
基本上,没有将这种检查纳入requests库的原因有三:
1.首先,我认为requests在技术上不是user-agent,而是库。这使我们摆脱了user-agent行为的一些限制(事实上,我们在库的其他地方采取了这种自由,就像我们对重定向的行为一样)。
那么,如果它不是user-agent,为什么默认情况下会发送以下User-Agent头?
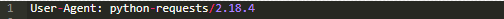
2.其次,如果我们抛出异常,我们不可改变地破坏我们读取的数据。它变得不可能访问。这意味着,用户如果想要在不知情的情况下,尽可能多地读取和保存数据,将变得困难。
这很好理解。但是,这应该是默认行为吗?我认为这应该作为一个可选项,requests会默认提醒你,但你应该可以禁止这个警告并使用你能够读取的数据。
3.最后,即使我们确实需要这个功能,我们也需要在urllib3中实现它。Content-Length是指消息体传输的字节数,而不是解码的长度,所以如果我们得到一个gzip(或DEFLATEd)响应,我们需要知道在解码之前有多少字节。这通常不是我们在requests库级别获得的信息。所以如果你仍然对这种行为感兴趣,我建议你在shazow / urllib3上打开一个issues。
urllib3是requests底层的http库。最初的发帖人在这里提交了一个issue。虽然有意愿提交PR,但是后来被关闭了。幸运的是,一年半后,提交了这样一个PR并且被接受了。
在阅读了上面的第三点之后,您可能会开始高兴。不好的一面是,即使urllib3 PR在2016年8月29日合并,当前稳定版本的requests(撰写时为2.18.4,即2018-04-22)仍然使用旧版本的urllib3,它不提供这个功能。好的一面是,requests库已经合并了新版本的urllib3,只不过是合并到了requests:proposed/3.0.0分支上。
那么,我能做些什么来检测脚本中的不完整读取?
requests 3.x
如果你看到这篇文章时,已经发布了requests 3.x,只需使用requests 3.x。它应该提供enforce_content_length参数,其默认值应该为True。也就是说,如果requests库收到一个不完整的内容,它应该引发一个异常:

requests 2.x
如果你使用的是requests2.x,你必须自己检查。你可以使用下面的一段代码:
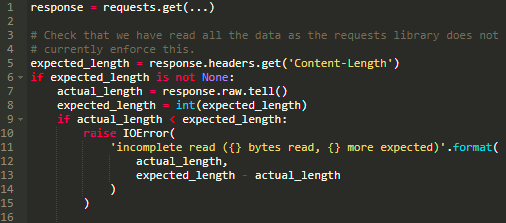
检查工作如下。首先,我们确保响应具有Content-Length头。如果没有,检查是毫无意义的。然后,我们得到实际读取的字节数,并将其与预期值进行比较。如果我们读取了更少的字节,我们会发出错误信号。当然,不要抛出异常,你可以做任何你想做的事情(重试,打印错误信息并退出,向朋友抱怨等)。
需要验证的话,你可以运行content-length.py HTTP服务器并通过client-with-check.py发送请求。服务器的写入方式使其返回的字节数少于响应的Content-Length头中所述的字节数。
被压缩的响应会怎么样?
响应可以被压缩。例如,服务器可能会返回Content-Encoding头设置为gzip的响应。这意味着响应体通过Lempel-Ziv编码(LZ77)进行压缩。当requests库收到这样的响应时,它会自动解压缩它。当你再检查response.content的长度(未压缩响应的字节数)时,它很可能与Content-Length头中指定的长度不同。这是我们没有使用len(response.content)来获取上述检查中响应的实际长度的原因。相反,我们必须使用response.raw.tell(),它返回读取的字节的实际数量(在解压缩之前)。
要验证的话,你可以运行content-encoding-gzip.py HTTP服务器并通过client-with-check.py发送请求。服务器的写入方式使其返回的字节数少于响应的Content-Length头中所述的字节数。
如果存在Transfer-Encoding:chunked?
另外,Content-Length头可以省略,可以使用chunked的Transfer-Encoding头。这种流式数据传输自HTTP 1.1起可用,通过将响应拆分为块。响应体具有以下形式:

这与Content-Length相比有几个优点,包括为动态生成的内容维护一个持久的HTTP连接的能力,这些动态生成的内容的完整大小事先是未知的。
当我们处理没有Content-Length头的分块传输时,我们应该如何检查是否收到了所有数据?幸运的是,在这种情况下,requests库按预期工作。也就是说,如果服务器发送不完整的数据,该库会引发异常

要验证的话,你可以运行transfer-encoding-chunked.py HTTP服务器并通过client.py发送请求。服务器的写入方式使其返回的字节数少于块大小中所述的字节数。
最终建议
始终验证你收到的数据是否正确。验证你已读取的字节数是第一步。例如,下载散列(例如SHA-256)已知的文件时,应检查下载文件的散列是否匹配。否则,您可能会冒险处理损坏的数据,这可能会导致恶意错误。
全部源代码
GitHub上提供了所有服务器和客户端的完整源代码。
讨论
你还可以在/r/Python和Hacker News上讨论这篇文章。
英文原文:https://blog.petrzemek.net/2018/04/22/on-incomplete-http-reads-and-the-requests-library-in-python/
译者:xiaocai









