
最近,iPad 和 iPhone 上的 LiDAR 有了新玩法,Apple Clips 应用程序中更新了基于三维重建的 AR 空间特效。通过 Clips 3.1 的 AR 空间功能,用户只需用带有 LiDAR 传感器的 iPad Pro 或 iPhone Pro 在房间中进行扫描和重建,就能为拍摄的视频中添加绚丽的 AR 效果。
比如跟着 AR 投射出来的灯光跳舞;

图 | Apple Clips 中基于 LiDAR 传感器的 AR 特效(来源:苹果)
再比如用 Star Walk 2 的 AR 功能,足不出户在房间屋顶上观看星座。

图 | Star Walk 2 的 AR 观星功能 (来源:苹果)
不过要实现上述视频中的效果,需要 iPad 和 iPhone 高端型号上配备的 LiDAR 深度传感器,而使用浙江大学-商汤三维视觉联合实验室所提出的方法,希望能让普通手机的单目摄像头也可实现上述效果。
实验室成员周晓巍接受了我们的采访。他是国内计算机视觉领域青年学者、也是浙江大学计算机辅助设计与图形学国家重点实验室的“百人计划” 研究员和博士生导师。几年前,在结束美国宾夕法尼亚大学 GRASP 机器人实验室的博士后研究后,回到母校任教。他告诉 DeepTech:“目前我们跟商汤、华为都有非常紧密的合作,通过这种产学研的结合,我们的研究成果既有对学术前沿的探索,又能根据实际需求去攻克一些技术瓶颈。与此同时,国内的 3D 视觉领域还处于新兴发展阶段,也需要我们回来一起把这个方向给发展壮大起来,不断缩短与国际领先水平之间的差距。”

图 | 相关论文(来源:受访者)
周晓巍所在的团队提出了一种基于单目视频的三维场景重建框架 NeuralRecon。在实时 (25 FPS) 的速度下,使用该方法可高质量地重建三维场景。对比结果显示,在 ScanNet、7-Scenes 等数据集上,NeuralRecon 的速度和精度均大幅领先以往方法。该工作将发表于今年的计算机视觉顶级会议 CVPR,并录用为口头报告。
据其表示,NeuralRecon 提出了用神经网络、直接回归基于 TSDF 表示的局部三维表面,并能使用基于 GRU 的 TSDF 融合模块,来融合历史局部表面的特征。这样设计的好处是,网络不仅能直接学习到三维表面的局部光滑性先验并借此实现准确且一致的重建,还可以减少以往方法中重复冗余的计算量,在保持质量的前提下实现实时的重建。据该团队所知,这是首个基于深度学习方法、并能实时重建稠密且一致三维表面的系统。
问题和挑战:基于图像的实时场景的三维重建依然任重道远

一直以来,稠密场景重建都是三维视觉的核心问题,在增强现实(AR)等应用中,扮演着重要角色。在 AR 应用中,要想实现真实、沉浸式的虚实融合体验,就需要正确处理真实场景和虚拟的AR物体之间的遮挡关系,并对阴影等效果做出正确的渲染,如此才能实现合理的虚拟内容放置、以及它和与真实场景的交互。概括来说,要想实现这些效果,都得对场景进行实时且精确的三维重建。
三维重建需要依赖精确的六自由度相机位姿估计。最近几年,视觉惯性 SLAM 逐渐成熟,且已得到大范围的落地应用。ARKit 和 ARCore 等 AR 框架的出现,让多数智能手机都能准确跟踪其自身六自由度的姿态。
然而,基于图像的实时场景的三维重建依然任重道远。目前常用的三维重建方案如 KinectFusion、BundleFusion 等,非常依赖深度传感器提供的深度测量。但是,由于深度传感器价格昂贵、功耗也比较高,因此其普及程度依然较低,通常只有少数高端型号的移动设备才舍得配备。因此,使用单目多视角图像去实现实时三维重建,具有非常大的应用前景。在不增加传感器的前提下,它可直接用在现有智能设备中。
而在基于多视角图像的三维重建方法中,基于深度图融合的方法非常流行。可是,这种方法存在两个问题:
第一,其中有大量重复计算,从相邻帧之间,可以看到相邻区域中有大面积的重合,同一区域的深度则会被计算多次,这会带来计算量上的冗余;第二,即便相邻两帧能看到的区域有较大重合,每一帧深度图的计算却都得重新开始,而非基于之前相邻帧的深度预测结果。
如下图所示,这会导致计算出来的相邻两帧的深度图不一致,重建的结果也因此常会非常分散,甚至会产生分层。
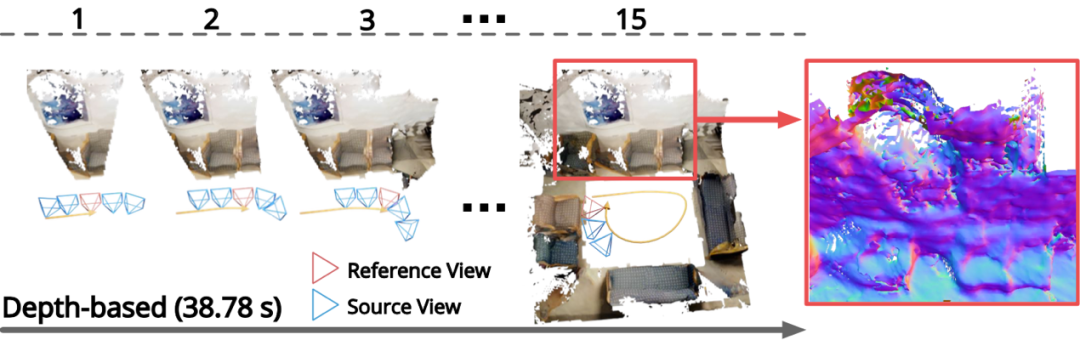
图 | 基于深度图融合方法的重建效果
NeuralRecon:新型三维场景重建框架
为解决上述痛点,该团队提出这一新型三维场景重建框架 NeuralRecon,下图展示了它的算法流程。这是一个轻量级的实时端到端系统,可直接从已知相机位姿的多视角图像中,重建基于稀疏 TSDF 表示的三维场景几何信息。
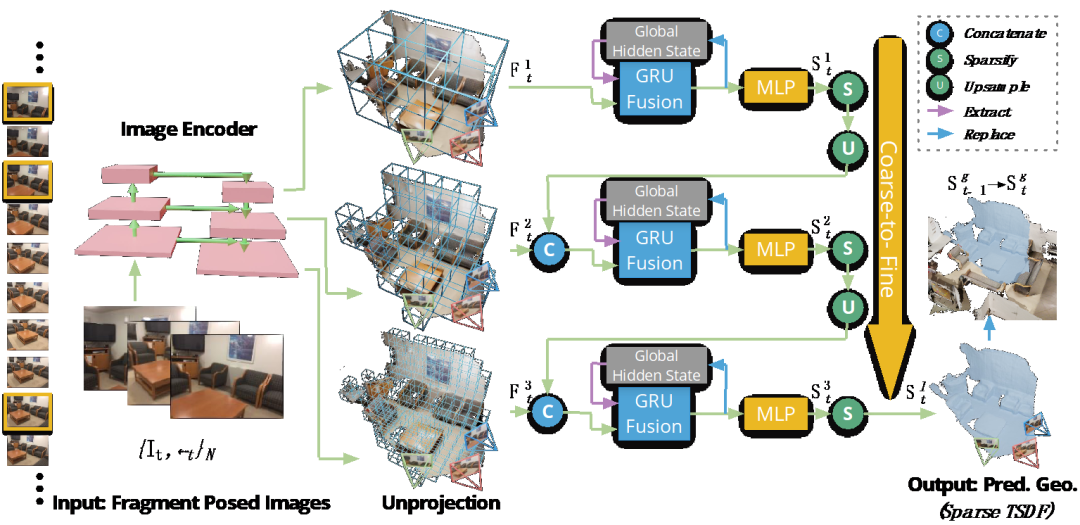
图 | NeuralRecon 的整体架构图
NeuralRecon 主要有如下两个步骤,第一步是关键帧的选择。
关键帧选择的目的,是为了在提供足够运动视差的同时,还能保持多视角的共视关系,因此所选关键帧之间的距离,不能太近也不能太远。具体来说, 假如一个新传入的帧和上一个关键帧的相对平移大于 t [max],并且相对旋转角度大于 R [max],那么就可选择该帧作为关键帧。而具备 N 个关键帧的窗口,可被定义为一个片段。
第二步是联合片段重建和融合,其中涉及三个分步骤。
第一个分步骤是图片特征提取和反投影,这里指的是某个视频片段中的 N 张图片,最初会通过一个 CNN 网络来提取多个分辨率下的图像深度特征。而图片特征会反投影到三维空间中,得到三维特征体。
第二个分步骤是从粗到细的三维场景重建。采取从粗到细的方式,分阶段地预测并细化场景的几何信息。在每个阶段中,稀疏三维卷积神经网络会被用来处理三维特征体,最终通过一个多层感知机 (MLP),获悉占有分数 (Occupancy score) 和 TSDF 值。
其中,占有分数代表着三维特征体中体素在 TSDF 截断距离之内的概率。在每个阶段的最后,占有分数小于阈值的体素,都会被定为空、并会被除掉。而在稀疏化之后,稀疏三维特征体会被上采样。下图是稀疏 TSDF 表示的可视化。
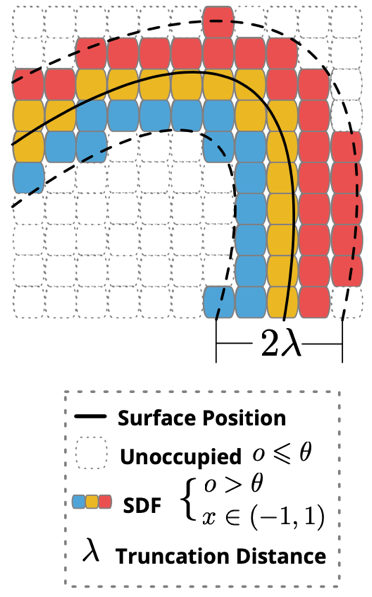
图 | 稀疏 TSDF 表示示意图
第三个分步骤是基于 GRU 的融合,这一步的目的,在于让片段的重建之间得以保持一致,希望当前片段的重建可建立在历史片段重建结果的基础上。
具体来说,该方法提出了一个基于 GRU 的联合重建与融合模块。如下图,在每个阶段,三维特征体都会首先通过一个三维稀疏卷积,并进行三维几何特征提取。然后,三维几何特征会被输入进 GRU 联合重建与融合模块。该模块会将三维几何特征与在历史片段重建中获得的隐变量进行融合,并通过一个全局感知机回归 TSDF 和占有分数。
直观地说,这里的 GRU 作为一种基于学习的选择性注意机制,可取代传统 TSDF 融合中的线性操作。在后续的步骤中,因为GRU 进行了联合重建与融合的操作,所以会直接将回归的 TSDF 替换对应区域的全局 TSDF,最终的重建结果可以从更新后的全局 TSDF 中通过 Marching Cubes 算法获得。
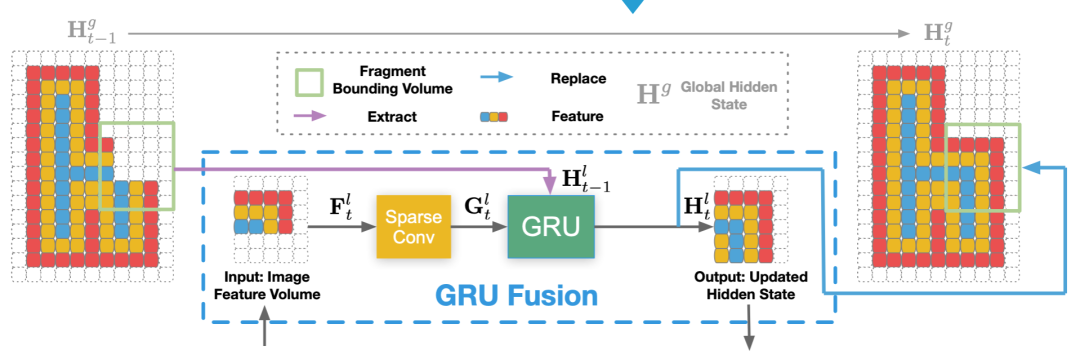
图 | 基于 GRU 的联合重建与融合
两大优势:重建结果具有一致性、重建过程用时更短
根据实验结果,作者们做出了可视效果的对比图。
对比可知,相比较传统的基于深度图的方法,NeuralRecon 主要有两方面优势:
其一,重建结果具有一致性;其二,重建过程用时更短。
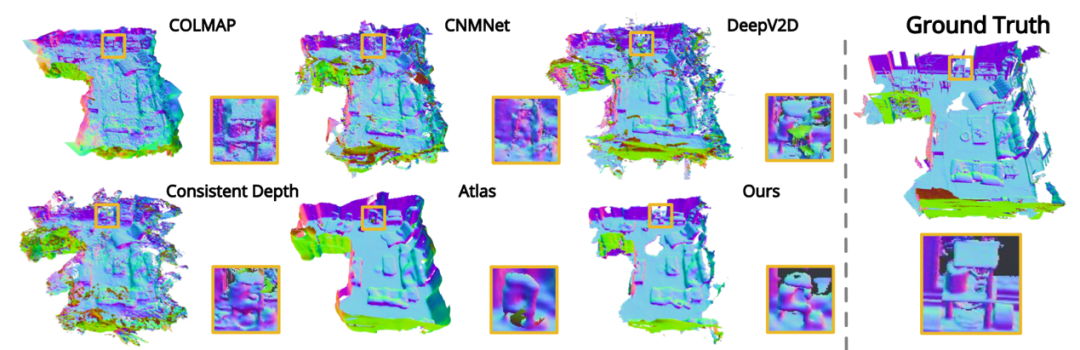
图 | NeuralRecon 重建结果(Ours)与其他方法的可视化对比
作者们在 ScanNet 数据集上,将本次方法和当前最好的方法做定量对比。对比发现,本次方法在 F-score 上和速度上,都能超过此前方法,并能做到实时且精确的估计。
与此前最快的方法 MVDepthNet 比较,本次方法不仅速度略有领先,F-score 也从 0.329 提到了 0.562。相比此前精度最高的方法 COLMAP,本次方法在精度稍胜一筹的情况下,处理每个关键帧所需时间也从 2076ms 降至 30ms。
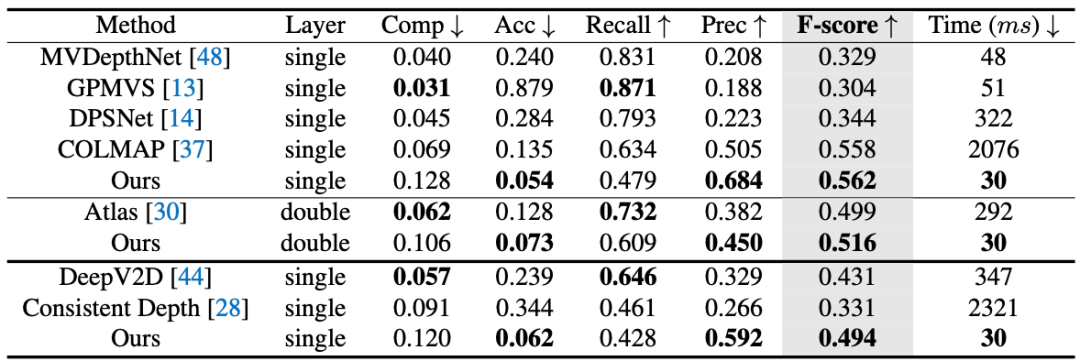
图 | 在 ScanNet 数据集上的定量评测结果
结语:NeuralRecon 为基于深度学习的三维感知系统打开新的可能性
概括来说,NeuralRecon 的核心思想,在于对每个视频片段的可视区域进行增量式的联合重建和联合融合。这个设计让 NeuralRecon 能实时输出精确、且具有一致性的三维表面。
展望未来,使用 NeuralRecon 重建的稀疏 TSDF 表示能直接用于三维语义分割、三维目标检测和可微渲染等下游任务。借助与下游任务的端到端联合训练,NeuralRecon 可为基于深度学习的三维感知系统提供出新的可能性。
-End-
参考:
NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video
https://arxiv.org/pdf/2104.00681.pdf
https://zju3dv.github.io/neuralrecon/












