AI美颜的其中一种模式,就是直接使用端到端的训练模式。
这里详细介绍一种端到端的美颜算法,使用的论文是:AutoRetouch:Automatic Professional Face Retouching
这篇论文是一个典型的端到端美颜模式,即原图输入网络,美颜后的效果图输出,这种模式基本上都是使用Pix2Pix类似的GAN网络架构来实现。此类模式,非常适合美颜类特效的处理。理论上,只要有成对的有规律的数据,使用Pix2Pix就是个不错的选择。这也是一种偷懒的方式,因为你不必理会效果中缩包含的复杂的算法,你缩担心的问题只有数据。
原版的Pix2Pix有些问题,比如清晰度不够,无法生成高清图像等,因此有了Pix2PixHD版本,这些内容大家可以到网上自行了解,这里要讲的是论文算法。
论文的网络结构:G和D网络
D网络使用了Pix2Pix的原版D网络;
G网络如下:
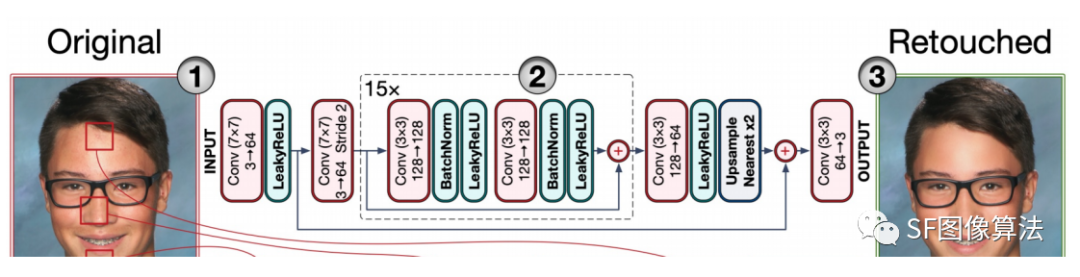
这个网络也比较简单,截图来自论文,输入3通道的原图,输出美颜后的效果图。原图输入后先做了一个大核7X7的卷积,通道扩增为64,然后是LeakyReLU层,接着是卷积下采样(这里下采样通道数好像写错了,应该是64-128),下采样之后是个15层的Resblock模块,每个模块中包含两次卷积+BN+LeakyReLU,最后是跳跃层Add。Resblock之后,是卷积和上采样,同时与前面对应层进行连接Add,在卷积输出效果图。整体上看是一个极简单的Unet结构,只是用了一次下采样,一次连接层。论文中说这样做的目的是为了更好的保留细节纹理。
有了G和D网络,剩下的就是LOSS,这篇论文依旧采用很普遍的LOSS:
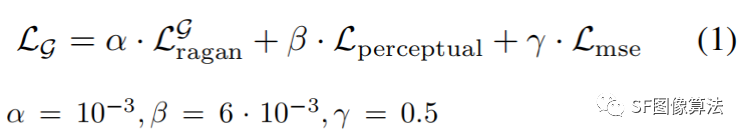
LOSS使用的是标准GAN 的LOSS和感知LOSS以及MSE三者的加权,权重选择如上所示。单独使用 MSE 损失可以得到平滑的图像,加入 perceptual loss(感知损失)可以改善这种情况。但是,感知损失仍然不能保留精细的细节。加上 adversarial loss 可以促使网络对图像进行尽可能少的改变。
整体上看,这篇论文是个中规中矩的GAN网络训练论文,本文只是借此来说一下这种美颜的模式。
论文效果图如下:
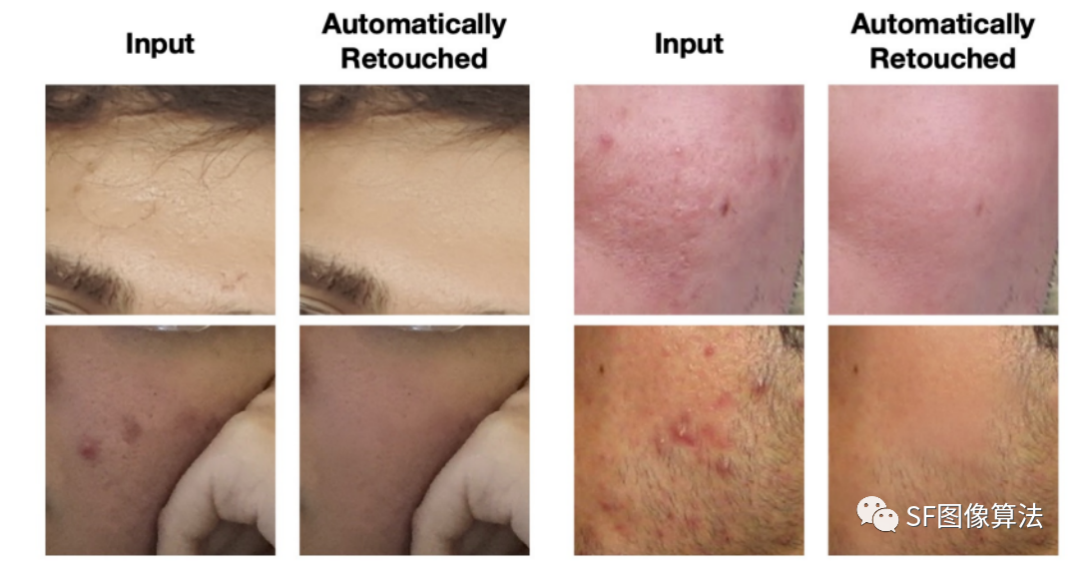

论文使用的数据集是FFHQR Dataset,地址:https://github.com/skylab-tech/ffhqr-dataset
论文地址:
https://link.zhihu.com/?target=https%3A//openaccess.thecvf.com/content/WACV2021/papers/Shafaei_AutoRetouch_Automatic_Professional_Face_Retouching_WACV_2021_paper.pdf
本人复现的代码如下:
def resblock(self, inputs, out_channel = 32): x = Conv2D(out_channel, kernel_size = (3,3), padding = "same")(inputs) x = BatchNormalization(momentum=0.8)(x) x = LeakyReLU(alpha = 0.2)(x) x = Conv2D(out_channel, kernel_size = (3,3), padding = "same")(x) x = BatchNormalization(momentum=0.8)(x) x = LeakyReLU(alpha = 0.2)(x) return Add()([x, inputs]) def build_generator(self
,input_shape=(None,None,3)): inputs = Input(shape = input_shape, name="inputs") channel = 64 x = Conv2D(channel, kernel_size = (7,7),strides = (1,1), padding = "same")(inputs) x = LeakyReLU(alpha = 0.2)(x) x0 = x x = Conv2D(channel * 2, kernel_size = (3,3),strides = (2,2), padding = "same")(x) for idx in range(15): x = self.resblock(inputs = x, out_channel = channel * 2) x = Conv2D(channel, kernel_size = (3,3),strides = (1,1), padding = "same")(x) x = LeakyReLU(alpha = 0.2)(x) x = UpSampling2D((2,2))(x) x = Add()([x, x0]) x = Conv2D(3, kernel_size = (3,3), padding = "same", activation='tanh')(x) model = Model(inputs, x) model.summary() return model def build_discriminator(self): def d_layer(layer_input, filters, f_size=4, bn=True): """Discriminator layer""" d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input) d = LeakyReLU(alpha=0.2)(d) if bn: d = BatchNormalization(momentum=0.8)(d) return d img_A = Input(shape=self.img_shape) img_B = Input(shape=self.img_shape) combined_imgs = Concatenate(axis=-1)([img_A, img_B]) d1 = d_layer(combined_imgs, self.df, bn=False) d2 = d_layer(d1, self.df*2) d3 = d_layer(d2, self.df*4) d4 = d_layer(d3, self.df*8) validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4) model = Model([img_A, img_B], validity) model.summary() return model
这里说下本人实现时遇到的问题,本人用了FFHQR中前面两万张数据进行训练测试,但是网络无法收敛,经常模型坍塌,后来发现有两个原因:
①数据太少,应该把7万数据都拿来训练,才能学到规律;
②数据中有些样本效果有问题,比如脸上的痘印,有些图去除的很干净,相反有些图却没有去掉,这种样本较多,导致了样本的无规律性,因此,如果样本数量较少,无法学到规律;









