
说起非监督学习,总逃不过Yann LeCnn的这张图,他将强化学习比做蛋糕上的樱桃,将监督学习比做蛋糕的奶油,而将非监督学习比做蛋糕底座。这个比喻不止说明了这三种学习范式的江湖地位。更形象的指出了各自的特点,强化学习得到最多的关注,监督学习好吃但是相对价格更贵(需要人工进行数据标记),而非监督学习虽然潜力巨大,但却相对来说最默默无闻。
除了不需要人工数据标记这个优点,非监督学习的另一个优点是不会引入人的偏见。举一个具体的例子,如果要开发一个能够自动对手机里照片按照内容分类的工具,那么监督学习的做法就是将图像进行分类,看看图片中的主体是人物,动植物,建筑,自然风景或是文字,然后按照每张照片的分类将照片放到不同的相册中。而非监督的方式要做的是将每一张图片放到一个二维空间中,不是随便的放,而是要让内容相近的图片都凑到一起,最终出现几个图片簇,而在每个簇之间的距离要尽可能的大。
如何判断图片的语义是否相近了,可以假设同一个时间段拍摄的,在同一个地点拍摄的照片具有相似的内容。一旦训练好了这样一个将图片自动聚类(降维)的模型,那么你朋友第二天发给你的昨天聚会照片,即使系统显示的时间不在同一天,也会被归档在正确的相册中。
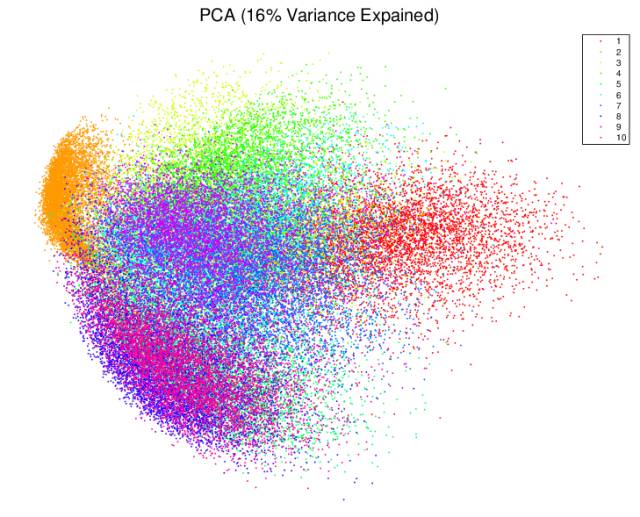
在深度学习出现之前,聚类已经有了很多种成熟的方法了,从最简单的K means到不需要设定聚类数的affinity propagation,再到层次化的聚类。然而,这些聚类方法对于非结构化的数据,例如图片,声音处理的不好,如果能够将非结构化数据的维度降低,那就可以使用传统的聚类方法了。然而,线性的聚类方法,例如PCA或MDS,在图像上的表现不佳。这里展示的是使用PCA对MINST数据进行降维的结果。不同的数字并没有被明显的区分开。
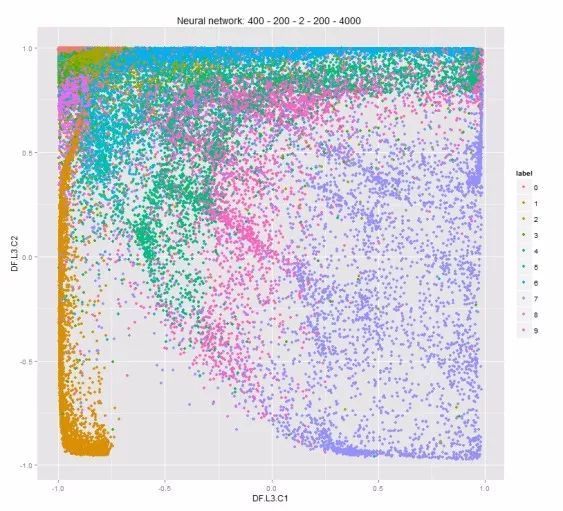
而使用非监督学习在深度学习中最典型的架构-自编码器,就可以做到对图像等非结构数据进行降维。下面展示的是用深度学习对手写数字进行的降维,不同的数字区分要比上一副图好的多。
任何深度学习的架构的构建,都是将想要达到的目标翻译成损失函数的过程,数据降维的目标是让降维后的数据能够更好的保持原有数据的区分度,让原来能分开的数据现在也能分开。但原始的没有标签的数据点之间距离都没有明确的定义,又如何用一个公式来量化降维后数据点之间的区分度。
如果在横向上无法解决问题,那可以试试在纵向上进行探索。先假设问题已经解决了,我们找到了一种完美的将MINST图像进行降维的方案,那么我们能拿这个方案做什么?假设每个MINST数据集中的图像有一个唯一的6位ID,越靠前的位置表示对该图片的越大类的分类。那么我们完美的降维方案给出的结果将可以100%的预测出图片的ID。接着假设我们还没有找到这个完美的降维方案,但已经差的不多了,那么我们根据降维后预测出的图像ID应该只在最后几位有差距。到了这一步,待优化的损失函数已经呼之欲出了,即降维后的特征生成的图像和原始的图像差距有多大。接下来要做的就是先训练一个神经网络来降维,再训练一个网络进行升维。
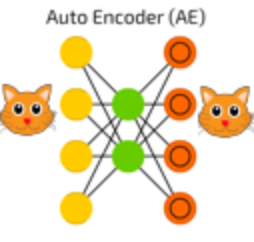
从最基本的自编码器出发,将损失函数进行改变,让输入加入误差,而待重构的是不带误差的原始数据,就可以得到变分自编码器(VAE)。而在网络结构上,也可以使用卷积网络或循环神经网络。然而不同于深度网络,自编码器的结构使得网络可以逐层训练。例如一个堆叠的自编码器,先将原始的100维数据降低为50维,再降低为10维,最后降低为3维。那么就可以先训练一个浅层的100->50->100的自编码器,训练好后将网络固定,再使用上次训练得出的降维数据训练50->10>50的自编码器,依次类推,最后将训练好的编码器和解码器按顺序堆叠起来。这样的训练方式可以避免梯度消失的问题。
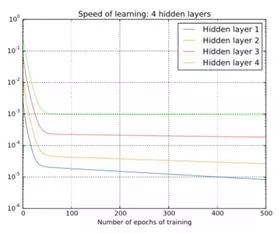
不同深度的网络学习率随着深度增加显著降低
自编码器进行数据降维的目地,是为了进行方便聚类。使用Kmeans等算法,可以对原来的Minst数据进行聚类。在有数据标签的时候,使用Normalized Mutual Information (NMI),可以来评价聚类的效果,这个数字越大,表示被正确的聚在一起的数字越多。如此,就可以评价使用原始的数据聚类和使用自编码器降维后的数据聚类的效果。

以下是Keras相关代码
# this is our input placeholder
input_img = Input(shape=(784,))
# "encoded" is the encoded representation of the input
encoded = Dense(500, activation='relu')(input_img)
encoded = Dense(500, activation='relu')(encoded)
encoded = Dense(2000, activation='relu')(encoded)
encoded = Dense(10, activation='sigmoid')(encoded)
# "decoded" is the lossy reconstruction of the input
decoded = Dense(2000, activation='relu')(encoded)
decoded = Dense(500, activation='relu')(decoded)
decoded = Dense(500, activation='relu')(decoded)
decoded =
Dense(784)(decoded)
# this model maps an input to its reconstruction
autoencoder = Model(input_img, decoded)
# this model maps an input to its encoded representation
encoder = Model(input_img, encoded)
autoencoder.compile(optimizer='adam', loss='mse')
pred_auto_train = encoder.predict(train_x)
pred_auto = encoder.predict(val_x)
km.fit(pred_auto_train)
pred = km.predict(pred_auto)
normalized_mutual_info_score(val_y, pred)
可以看到,使用自编码器+Kmeans 的方法,其MNI从0.50提升到了0.74,效果很明显。类似的,使用自编码器降维后的特征,也可以结合传统的机器学习算法,例如KNN,随机森林等进行分类任务,你可以训练多个层数不同自编码器,有的将原始数据(100维)降低为10维,有的降低为2维,再分别使用降维后的数据进行分类,这可以理解成集成弱分类器,也可以从神经网络的角度理解成残差网络,即在深度的网络中加入直接连接的短路层。
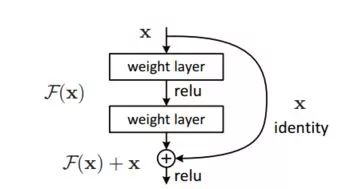
残差网络的结构

自编码器在监督学习中还有另一种应用。还是拿Minst数据分类举例,已知标签时,可以对每一个数字训练一个自编码器,然后一个待分类的数字来了,分别用在训练集中训练好的自编码器进行重构,根据那个自编码器的重构误差大小,使用softmax函数,将不同数字对应的自编码器的重构误差转化为该图片为那个数字的概率分布。
这样的分类方式下,假设你拿一张写着字母A的图片,那么这十个用手写数字训练出来的自编码器,就会出现没有一个重构误差足够小的情况,这使得你的模型能够发现异常点,而传统的分类模型,你的图片总会被归到一类中。再假设现在你在Minst数据集之外,又拿到了一万张手写的8的照片,这时你不需要重新训练模型,只需要重新训练数字8对应的自编码器。
假设你在训练中发现数字8和数字6总是容易区分不开,那你可以根据一个新的图片在数字6和8中对应的自编码器中的重构误差进行人为的调整,比对在经过softmax时放大其中的差异。这使的深度学习不在是一个黑盒,使得研究者可以看到预测过程中发生了什么。
在模型训练的过程中,也可以针对原始图像和生成图像的距离进行类似Relu函数的截断。通过更改权重,让模型在重构误差小于一定cutoff的情况就不进行优化,而只关注那些重构误差还相对较大的样本。这里的思路就类似Xgboost中将预测结果不好的样本再放回重新训练的思路了。
假设现在数字8的样本数已经是其他数字的100倍了,上述的使用自编码器的分类模型不会像传统的分类模型那样,受到样本数不均的负面影响。这对于医疗,金融这种正负样本量差距很大的应用场景,极其有用。同时,这样的方法进行的预测,更加稳健,不用担心图像修改一个像素,模型的预测结果就会改变。
将自编码器用于图像生成,可以避免GAN中的模式塌缩问题(只生成黄色的猫)。分别用猫和狗的图像训练自编码器,将原始图像的降维表示进行微调,就可以用来生成新的猫和狗的照片。由于生成的图片都在原始图片降维后的空间附近, 自编码器生成的照片,不会出现GAN那样五条腿的猫这种明显不符合常识的图片。
使用自编码器降维,还会有更好玩的应用。还是MINST数据集,将所有6的图片,分别转90,180,270度,这样一张图片就变成了4张,通过自编码器降维再进行Kmeans 聚类(K取4),是可以将图像按照转动的角度分成4类的。现在拿一张正常的9的图片交给自编码器去降维,这个图片会被分到旋转180度的那一簇6中,这说明模型可以学到图片的语义信息,这种在不同事物间进行关联的能力,是人类推理的基石。
更哲学一些的论述,非监督学习做的是根据现有的数据去预测将来。MInst数据集的例子可以看成是将一个人写数字的过程拍了下来,假设一个人要花3秒写数字,自编码器做的可以看成根据第三秒后的笔迹预测前一秒之前的笔迹,最终能够达到在一个数字还没有写完的时候就预测出这个数字本身是什么。(空间的降维再升维对应时间上的历史匹配加预知)
总结一下,这篇小文介绍了自编码器的原理,训练方法及在分类和聚类和图像生成中多种的应用场景及优势。自编码器的变种很多,发展很快,代码相比于CNN,RNN来,实现起来也不难,是一个值得细致学习的探索深度学习框架,这篇小文要做的只是抛砖引玉。
更多越多
R 语言中的深度学习 Minst数据集下的聚类分析
原创不易,随喜赞赏











