一直以来,贝叶斯深度学习的先验都不够受重视,这样真的好么?苏黎世联邦理工学院计算机科学系的一位博士生 Vincent Fortuin 对贝叶斯深度学习先验进行了重新审视。
众所周知,先验的选择是贝叶斯推断流程中最关键的部分之一,但最近的贝叶斯深度学习模型比较依赖非信息性先验,比如标准的高斯。在本篇论文中,来自苏黎世联邦理工学院计算机科学系的博士生 Vincent Fortuin 强调了先验选择对贝叶斯深度学习的重要性,概述了针对(深度)高斯过程、变分自编码器、贝叶斯神经网络的不同先验,并从数据中总结了学习这些模型先验的方法。作者 Vincent Fortuin(下图右)专注于深度学习和概率建模接口的相关研究,特别热衷于遵循贝叶斯范式开发更具解释性和数据效率的模型,并且尝试利用更好的先验和更有效的推断技术来改进深度概率模型。
论文链接:https://arxiv.org/pdf/2105.06868.pdf贝叶斯模型在数据分析和机器学习领域中应用广泛。近年来,如何将模型与深度学习相结合也引发了研究者的兴趣。贝叶斯建模的主要思想是使用一些观察到的数据 D 来推断模型参数θ的后验分布,采用的贝叶斯定理如下: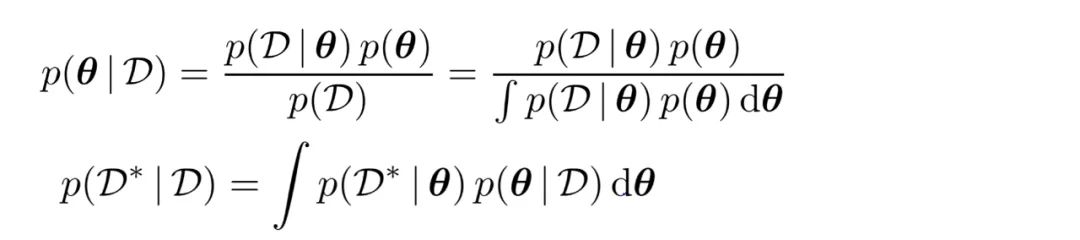
其中 p(D|θ)是似然,p(D)是边际似然(或证据),而 p(θ)是先验,D * 是未见过的新数据。但相比先验,人们的注意力更多地集中在后验预测的性质上,比如预估以上等式的积分或使用边际似然进行贝叶斯模型选择。在传统的贝叶斯主义中,选择先验的方式是应使其能够在看到任何数据之前准确反映出人们对参数θ的判断。这是贝叶斯模型构建的最关键部分,也是最难的部分,因为将从业者的主观判断明确地映射到可处理的概率分布上通常不是一件易事。因此,在实践中,选择先验通常被视为麻烦事,并且已经有许多人尝试避免必须选择客观先验、经验贝叶斯或两者相结合这样的先验。特别是在贝叶斯深度学习中,通常的做法是选择看似「无信息」的先验,比如标准高斯。这种趋势令人不安,因为选择不好的先验会对整个推断工作造成不利影响。尽管选择非信息性(或信息性较弱)的先验通常是出于 Bernstein-von-Mises 定理的渐近一致性保证(asymptotic consistency guarantee),但因为其正则条件不满足,该定理实际上在许多应用中并不成立。此外,在实际推断的非渐近状态中,先验对后验有很大的影响,通常将概率质量强加到参数空间的任意子空间上,例如在看似无害标准高斯先验情况下的球形子空间。
更糟糕的是,先验的错误肯定会破坏那些迫使首先使用贝叶斯推断的特性。比如说,边际似然在先验的错误指定下可能变得毫无意义,导致在使用贝叶斯模型时选择次优模型。甚至可以证明,当先验的指定不正确时,就泛化性能而言,PAC - 贝叶斯推断可以超过贝叶斯推断。因此,批判性地反思贝叶斯深度学习模型中的先验选择是必要的。本篇论文将着重讨论标准非信息性先验的替代选择,并重新回顾审视(深度)高斯过程、变分自编码器、贝叶斯神经网络的现有先验设计,最后简要概述从先验数据中学习先验的方法。高斯过程(Gaussian process, GP)在贝叶斯机器学习中有着很长的历史,为其带来了很多有用的特性,并且与贝叶斯深度学习有很深的联系。下文将具体介绍如何通过深度神经网络(DNN)对 GP 先验进行参数化,如何堆叠 GP 以构建更深的模型,以及如何将深度神经网络转化为 GP 或由 GP 评估。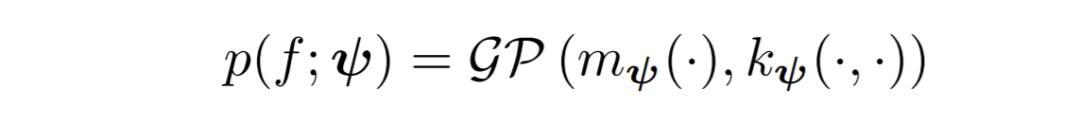
既然 GP 先验由参数化函数确定,那么选择 DNN 作为函数,自然是可行的。但是,因为大多数神经网络函数实际上不会得到合适的核函数,所以必须仔细处理深度核函数。从神经网络中提取核函数的一种选择是将网络的最后一层用作特征空间,并将核函数定义为该空间中的内积,即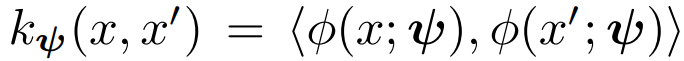 。 这导致了网络特征空间中的贝叶斯线性回归,也叫做贝叶斯最后一层(Bayesian last layer, BLL)模型。开发深度核函数的另一种选择是从基本核 k_base(·,·)开始,例如长度尺度为λ的径向基函数(radial basis function, RBF)核 k_RBF(x, x′ ) = exp(−λ(x − x′)^2) ,然后可以将此内核应用于 DNN 特征空间,从而产生内核:
。 这导致了网络特征空间中的贝叶斯线性回归,也叫做贝叶斯最后一层(Bayesian last layer, BLL)模型。开发深度核函数的另一种选择是从基本核 k_base(·,·)开始,例如长度尺度为λ的径向基函数(radial basis function, RBF)核 k_RBF(x, x′ ) = exp(−λ(x − x′)^2) ,然后可以将此内核应用于 DNN 特征空间,从而产生内核: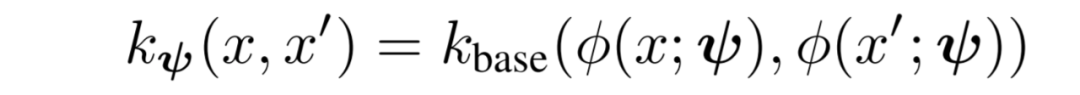
如果选择线性核函数 k_lin(x, x′) = 作为基础核,则可以简化至上面的 BLL 模型。然而,在选择像 RBF 这样的内核时,该模型仍然产生了无限维再现核 hilbert 空间,因此提供了不会缩至有限贝叶斯线性回归的完整 GP。这些方法不仅可以产生非常有表现力的模型,而且还可以改善诸如对抗性鲁棒性之类的属性。当使用深度均值函数代替深度核函数或结合使用时,只需采取较少的预防措施,因为任何函数实际上都是有效的 GP 均值函数。因此,神经网络本身就可以被用作均值函数,而且 GP 中的深层均值函数已经与其他流行的学习范式相关,例如功能性的 PCA。但是,与上面的深层核函数一样,主要问题是如何选择函数。由于 DNN 难以解释,在查看任何数据之前选择参数似乎是不可能完成的任务。因此,这些方法通常会与其他一些学习算法结合使用,基于一些目标函数来设置其参数。此外,关于一种特定类型的 GP 内核,即卷积内核,它本身并不是由神经网络进行参数化的,而是受到卷积神经网络(CNN)的启发,从而提高了对于图像的性能。既然 GP 可以与深度神经网络结合,那么它们自然也可以用于自构建深度模型,比如深度 GP。与深层神经网络类似,深度 GP 也是随着深度增加而分布得更复杂。但与神经网络不同,深度 GP 仍然包含了完全的贝叶斯处理。而与标准 GP 相比,深层 GP 还可以对大规模输出分布建模,其中包括具有非高斯边际的分布。为了增加灵活性,这些模型还可以与 GP 层之间的翘曲函数结合使用。此外还可以将它们与上述卷积 GP 内核结合使用,以产生与深层 CNN 相似的模型。尽管这些模型似乎远优于标准 GP,但仍付出了一定的灵活性作为代价:封闭形式的后验推断不再易于处理。这意味着必须使用近似推断技术来估计后验,例如变分推断、期望传播和摊销推断。一种非常流行的 GP 近似推断技术是基于归纳点的,它们被选为训练点或训练域的子集。该技术还可以扩展到深度 GP 的推断或由变异随机特征的替代。而与推断技术相反,对于深度 GP 的先验选择并未得到充分的研究。虽然深度 GP 可以基于函数建模一个复杂的先验,但就 m_ψi 和 k_ψi 而言,单层的先验通常选择得比较简单。将 GP 连接到 DNN 的另一种方法是通过神经网络限制。由于具有单个隐藏层的贝叶斯神经网络(BNN)和任何独立的有限方差参数先验 p(θ)诱导的函数空间先验 p(f)收敛于无穷大的极限,且考虑到中心极限定理,GP 先验的限制由下式给出: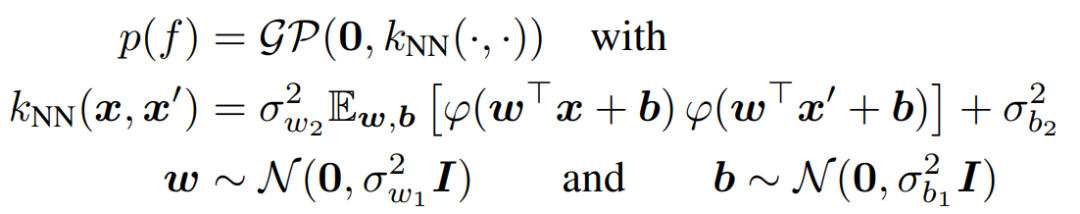
除了 GP,另一种流行的贝叶斯深度学习模型是变分自编码器(VAE)。这些贝叶斯潜变量模型假设一个生成过程,通过似然 p(x | z),其中观察值 x 是从未观察到的潜变量 z 生成的。VAE 通过在观察数据上训练的神经网络进行参数化似然,由于此神经网络的非线性特性可精确地推断出后验 p(z | x),因此可以使用由神经网络进行参数化的变分近似值 q(z | x)对其进行推断。接着通过优化证据下界(evidence lower bound, ELBO)训练整个模型: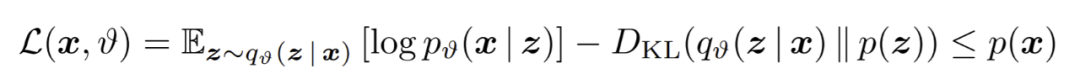
似然和近似后验通常被选作高斯,而先验则为标准高斯,即 p(z)= N(0, I)。接下来,作者在论文中具体讨论了可以直接替代标准高斯模型的适当概率分布、需要更改架构的一些先验,以及一个带有特异结构和神经过程先验的 VAE 模型。贝叶斯神经网络是通过贝叶斯推断确定参数,并使用后验预测进行预测的一种神经网络模型。近年来,由于它们的不确定度校准特性,这些模型越来越受欢迎。尽管研究者针对这些模型提出了许多不同的先验,但也有很多研究者认为基于参数的标准高斯先验是足够的,建模者的归纳偏差应通过架构选择来表示。经过对小型网络和简单问题的初步研究,这种观点得到了支持,但这些简单问题并未找到有关高斯先验误定的确凿证据。然而,在最近的研究中,高斯先验的充分性一直遭到质疑,特别是因为研究者发现了高斯先验会引起冷后验效应,而这种效应并不是由其他先验引起的。遵循先验错误指定的考量,作者建议考虑 BNN 的替代先验并在论文中回顾了在权重空间和函数空间中定义的先验,还展示了如何将这些思想扩展到神经网络的(贝叶斯)合奏。到目前为止,研究者已经探索了不同类型的分布和方法,以将先验知识编码为贝叶斯深度学习模型。但是,如果研究者没有任何有用的先验知识要如何编码呢?因为 ML-II 优化和贝叶斯元学习思想原则上可以用于学习上面讨论的大多数先验知识的超参数,所以作者按照上面的结构,重新回顾探索了高斯过程、变分自编码器、和贝叶斯神经网络中的学习先验。最后,作者做出了总结:在贝叶斯模型中选择良好的先验对实现实际的理论和经验属性至关重要,包括不确定性估计、模型选择、最佳决策支持。虽然贝叶斯深度学习的从业人员目前通常选择各向同性的高斯(或类似的无信息)先验,但是这些先验通常是错误指定的,并且在推断过程中可能导致一些意想不到的负面后果。另一方面,精心选择的先验可以提高性能,甚至可以实现新视角的应用程序。幸运的是,当下流行的贝叶斯深度学习模型有多种替代的先验选择,例如深度高斯过程、变分自编码器、贝叶斯神经网络。而且,在某些情况下,甚至可以仅从数据中学习到这些模型有用的先验。
与吴恩达共话ML未来发展,2021亚马逊云科技中国峰会可「玩」可「学」
2021亚马逊云科技中国峰会「第二站」将于9月9日-9月14日全程在线上举办。对于AI开发者来说,9月14日举办的「人工智能和机器学习峰会」最值得关注。
当天上午,亚马逊云科技人工智能与机器学习副总裁Swami Sivasubramanian 博士与 AI 领域著名学者、Landing AI 创始人吴恩达(Andrew Ng )博士展开一场「炉边谈话」。
不仅如此,「人工智能和机器学习峰会」还设置了四大分论坛,分别为「机器学习科学」、「机器学习的影响」、「无需依赖专业知识的机器学习实践」和「机器学习如何落地」,从技术原理、实际场景中的应用落地以及对行业领域的影响等多个方面详细阐述了机器学习的发展。
点击阅读原文,立即报名。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com







