点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
前言 本文介绍了两个实验,展示了padding在深度学习模型中的影响。
作者:Harald Scheidl
实验一
卷积是平移等变的:将输入图像平移 1 个像素,输出图像也平移 1 个像素(见图 1)。如果我们对输出应用全局平均池化(即对所有像素值求和),我们会得到一个平移不变模型:无论我们如何平移输入图像,输出都将保持不变。在 PyTorch 中,模型如下所示:y = torch.sum(conv(x), dim=(2, 3)) 输入 x,输出 y。
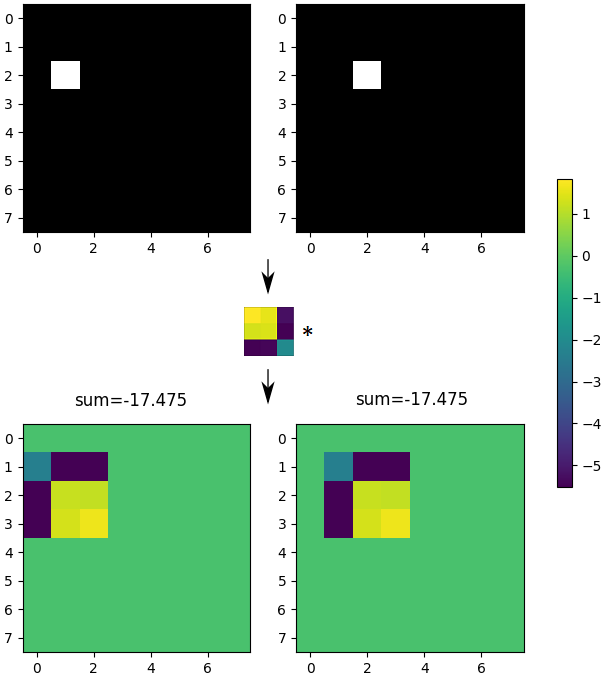
图 1:顶部:包含一个白色像素的输入图像(原始和 1 个像素移位版本)。中:卷积核。底部:输出图像及其像素总和。是否可以使用此模型来检测图像中像素的绝对位置?
对于像所描述的那样的平移不变模型,它应该是不可能的。
让我们训练这个模型对包含单个白色像素的图像进行分类:如果像素在左上角,它应该输出 1,否则输出 0。训练很快收敛,在一些图像上测试二元分类器表明它能够完美地检测像素位置(见图 2)。
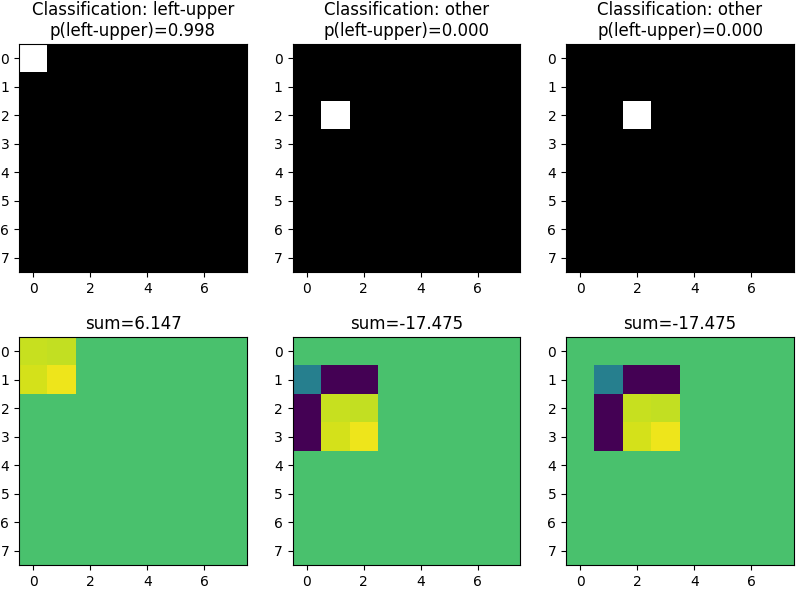
图 2:顶部:输入图像和分类结果。底部:输出图像和像素总和。
模型如何学习对绝对像素位置进行分类?这仅可能由于我们使用的填充类型:
图 3 显示了经过一些 epoch 训练后的卷积核
当使用“same”填充(在许多模型中使用)时,内核中心在所有图像像素上移动(隐式假设图像外的像素值为 0)
-
这意味着内核的右列和底行永远不会“接触”图像中的左上像素(否则内核中心将不得不移出图像)
但是,当在图像上移动时,内核的右列和/或底行会接触所有其他像素
我们的模型利用了像素处理方式的差异
只有正(黄色)内核值应用于左上白色像素,从而只产生正值,这给出了正和
对于所有其他像素位置,还应用了强负内核值(蓝色、绿色),这给出了负和
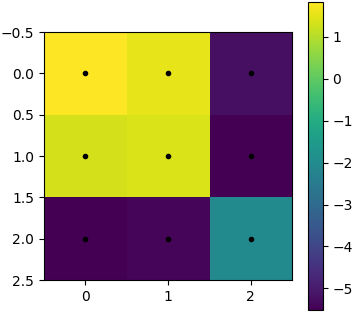
图 3:3×3 卷积核。
尽管模型应该是平移不变的,但事实并非如此。问题发生在由所使用的填充类型引起的图像边界附近。
实验二
输入像素对输出的影响是否取决于其绝对位置?
让我们再次尝试使用只有一个白色像素的黑色图像。该图像被送入由一个卷积层组成的神经网络(所有内核权重设置为 1,偏置项设置为 0)。输入像素的影响是通过对输出图像的像素值求和来衡量的。“valid”填充意味着完整的内核保持在输入图像的边界内,而“same”填充已经定义。
图 4 显示了每个输入像素的影响。对于“valid”填充,结果如下所示:
内核接触图像角点的位置只有一个,角点像素的值为 1 反映了这一点
对于每个边缘像素,3×3 内核在 3 个位置接触该像素
对于一般位置的像素,有 9 个核位置,像素和核接触
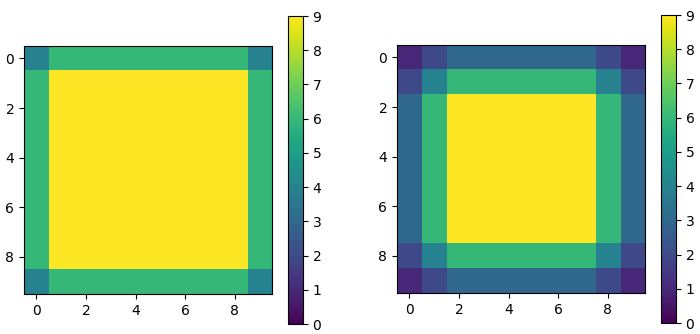
图 4:将单个卷积层应用于 10×10 图像。左:“same”填充。右:“valid”填充。
边界附近像素对输出的影响远低于中心像素,当相关图像细节靠近边界时,这可能会使模型失败。对于“same相同”填充,效果不那么严重,但从输入像素到输出的“路径”较少。
最后的实验(见图 5)显示了当从 28×28 输入图像(例如,来自 MNIST 数据集的图像)开始并将其输入具有 5 个卷积层的神经网络(例如,一个简单的 MNIST 分类器可能看起来像这样)。特别是对于“valid”填充,现在存在模型几乎完全忽略的大图像区域。
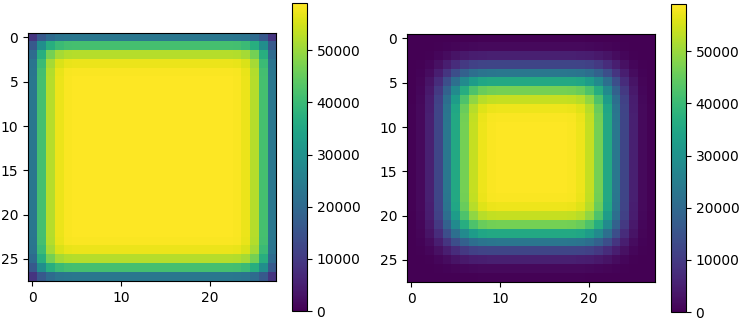
图 5:将五个卷积层应用于 28×28 图像。左:“same”填充。右:“valid”填充。
结论
这两个实验表明,填充的选择很重要,一些糟糕的选择可能会导致模型性能低下。有关更多详细信息,请参阅以下论文,其中还提出了如何解决问题的解决方案:
1. MIND THE PAD – CNNS CAN DEVELOP BLIND SPOTS
2. On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location
原文链接:
https://harald-scheidl.medium.com/does-padding-matter-in-deep-learning-models-176ed68fa348
----版权声明----
仅用于学术分享,若侵权请联系删除
独家重磅课程!
1、VIO课程:VIO灭霸:ORB-SLAM3源码详解,震撼上线!
2、图像三维重建课程(第2期):《视觉几何重建》课程及84页独家电子书上线!
3、重磅来袭!基于LiDAR的多传感器融合SLAM 系列教程:LOAM、LeGO-LOAM、LIO-SAM
4、系统全面的相机标定课程:单目/鱼眼/双目/阵列 相机标定:原理与实战
5、视觉SLAM必备基础(第2期):视觉SLAM必学基础:ORB-SLAM2源码详解
6、深度学习三维重建课程:基于深度学习的三维重建学习路线
7、激光定位+建图课程:激光SLAM怎么学?手把手教你Cartographer从入门到精通!

全国最棒的SLAM、三维视觉学习社区↓

技术交流微信群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群,请添加微信号 chichui502 或扫描下方加群,备注:”名字/昵称+学校/公司+研究方向“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓

— 版权声明 —
本公众号原创内容版权属计算机视觉life所有;从公开渠道收集、整理及授权转载的非原创文字、图片和音视频资料,版权属原作者。如果侵权,请联系我们,会及时删除。








