
大家好,欢迎来到 Crossin的编程教室 !
长假结束,大家是不是都已经回到各自的工作岗位,继续开启努力的搬砖(摸鱼)生活了呢?
从19年开始,每逢十一就会上映一部以 我和我的** 主题的电影来喜迎国庆,并且按照前两年票房趋势,这部电影的欢迎程度远大于同时期上映的其它电影,票房稳居第一。
今年也不例外上映了一部《我和我的父辈》,以4个片段来讲述父母与孩子之间的故事,内容也受到大众的肯定。
但令人意外的是它的票房,要远低于另一部国庆档《长津湖》,热度和好评数远高于前者,关于其中的具体细节,本文尝试来做个影评分析。
本文挑选了在今年国庆上映三部电影,分别是《我和我的父辈》、《长津湖》以及《五个扑水的孩子》。
《五个扑水的孩子》这部电影许多读者可能是第一次听到,热度远不及前两部,但它的确是在今年国庆期间上映的,而且根据猫眼排名,热度还不低,位居第三。
技术栈
开始之前,先说下本文所用到的技术栈,主要分为以下两方面:
语言:Python,javascript
库:echarts,styleCloud
影评对比分析
首先是从影评角度来分析一下,这里借助 Python 获取到三部电影的在豆瓣上的部分影评,关于豆瓣影评的爬取,这里我就不过多介绍了,不太熟悉的参考旧文,核心代码贴在下方:
headers = {
"Cookie":"bid=tulFhUK9Lzo; douban-fav-remind=1; ll=\"118160\"; _vwo_uuid_v2=D55143433EAF6AF4EB29A904F8BE781A1|4d5d27125abfe3f6d29caa68ba504fed; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1632849782%2C%22https%3A%2F%2Fwww.google.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.52492667.1628212627.1629608096.1632849782.3; __utmc=30149280; __utmz=30149280.1632849782.3.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utma=223695111.788106722.1629608096.1629608096.1632849782.2; __utmb=223695111.0.10.1632849782; __utmc=223695111; __utmz=223695111.1632849782.2.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utmb=30149280.3.10.1632849782; _pk_id.100001.4cf6=254979423a09aae4.1629608097.2.1632851386.1629608485.",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
}
#
#Part1 数据爬取改一下 id 即可
movieId = "35030151"
for offset in range(0,220,20):
url = "https://movie.douban.com/subject/{}/comments?start={}&limit=20&status=P&sort=new_score".format(movieId,offset)
res = requests.get(url,headers= headers)
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
time.sleep(2)
for comment_item in soup.select("#comments > .comment-item"):
try:
data_item = []
avatar = comment_item.select(".avatar a img")[0].get("src")
name = comment_item.select(".comment h3 .comment-info a")[0]
rate = comment_item.select(".comment h3 .comment-info span:nth-child(3)")[0]
date = comment_item.select(".comment h3 .comment-info span:nth-child(4)")[0]
comment = comment_item.select(".comment .comment-content span")[0]
# comment_item.get("div img").ge
data_item.append(avatar)
data_item.append(str(name.string).strip("\t"))
data_item.append(str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"))
data_item.append(str(date.string).replace('\n','').strip('\t'))
data_item.append(str(comment.string).strip("\t").strip("\n"))
data_json ={
'avatar':avatar,
'name': str(name.string).strip("\t"),
'rate': str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"),
'date' : str(date.string).replace('\n','').replace('\t','').strip(' '),
'comment': str(comment.string).strip("\t").strip("\n")
}
if not (collection.find_one({'avatar':avatar})):
print("data _json is {}".format(data_json))
collection.insert_one(data_json)
except Exception as e:
print(e)
首先,我们先看下关于这三部电影的评论在每个时间段有没有数量方面的差异,于是就有了下面图1
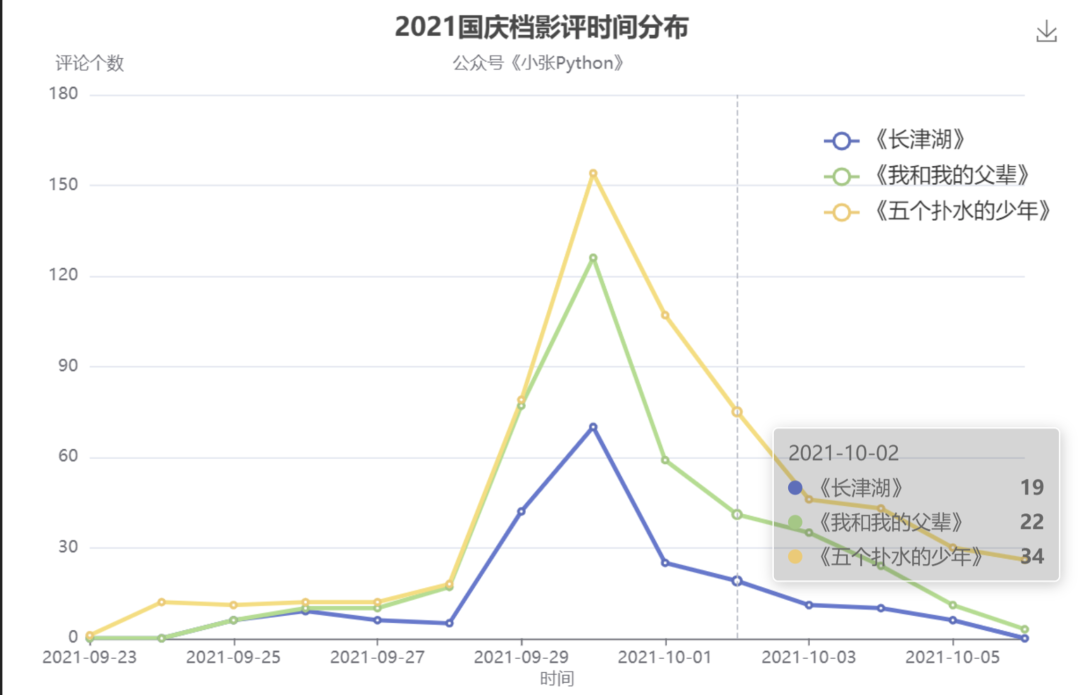 图1
图1根据图1可视化结果来看,三部电影的评论趋势是一致的,从 24日开始评论数慢慢增加,到 30 日达到高峰,之后慢慢回落。
这个趋势也比较合乎常理,30日及30日之前的评论都可以被认为是用户看完点映之后反馈,也是出品商为了利益最大化,为电影增加热度的一种方式。
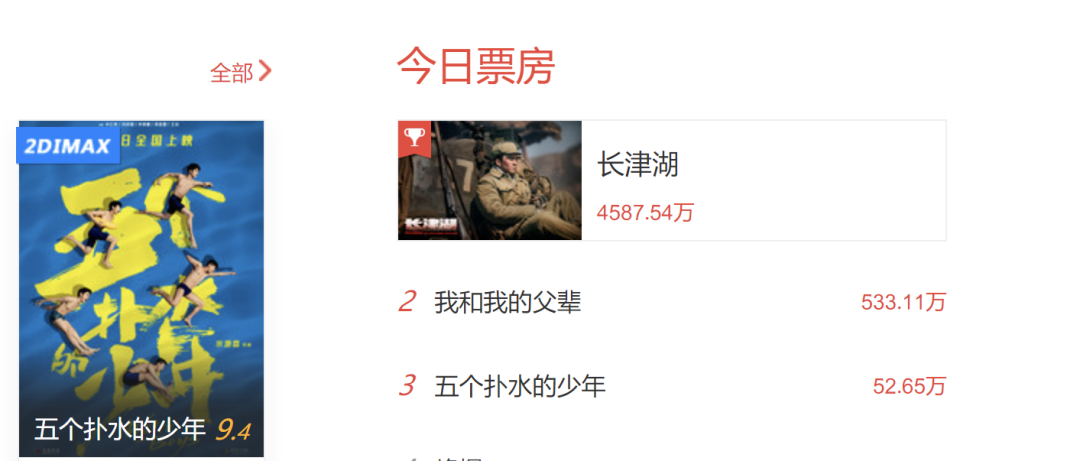
但是这里面比较大的一个问题是 评论数量对比,根据这个折线图显示,《五个扑水的少年》的评论数远大于《长津湖》和《我和我的父辈》,无论影评好坏,根据传播学的角度前者的热度要远高于后者,而后面票房对比结果却恰恰相反,至于为什么出现这种趋势,这个只能大家自己细品……只能说《长津湖》出品方是真的自信,评论热度低,但票房却很出众。
与影评相关的星级分布,在这里我也做了个简单对比,《少年》、《长津湖》、《父辈》(这里偷个懒,都用简称来替换 ) 可视化效果见图2,图3、图4
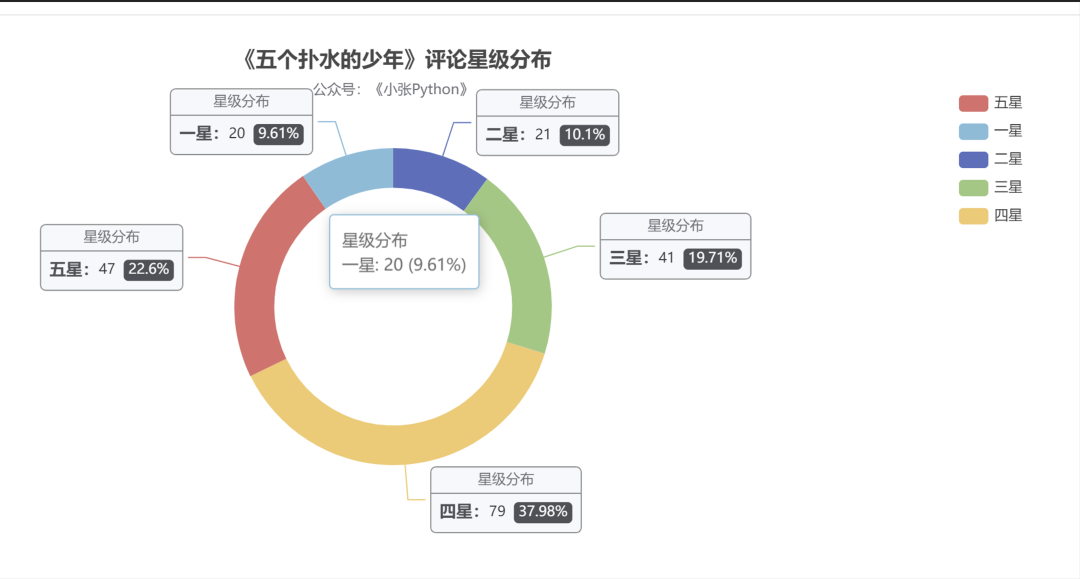 图2
图2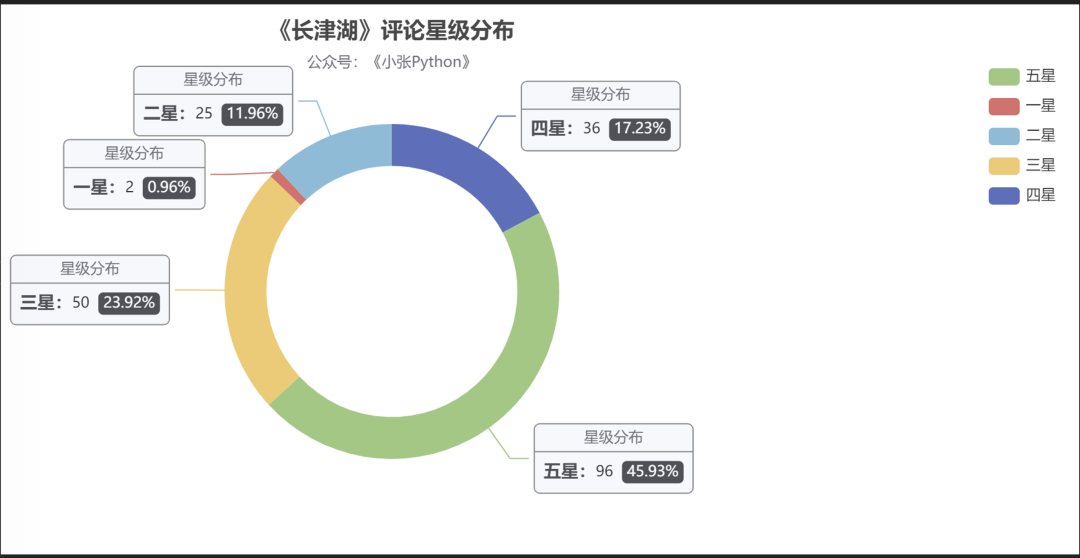 图3
图3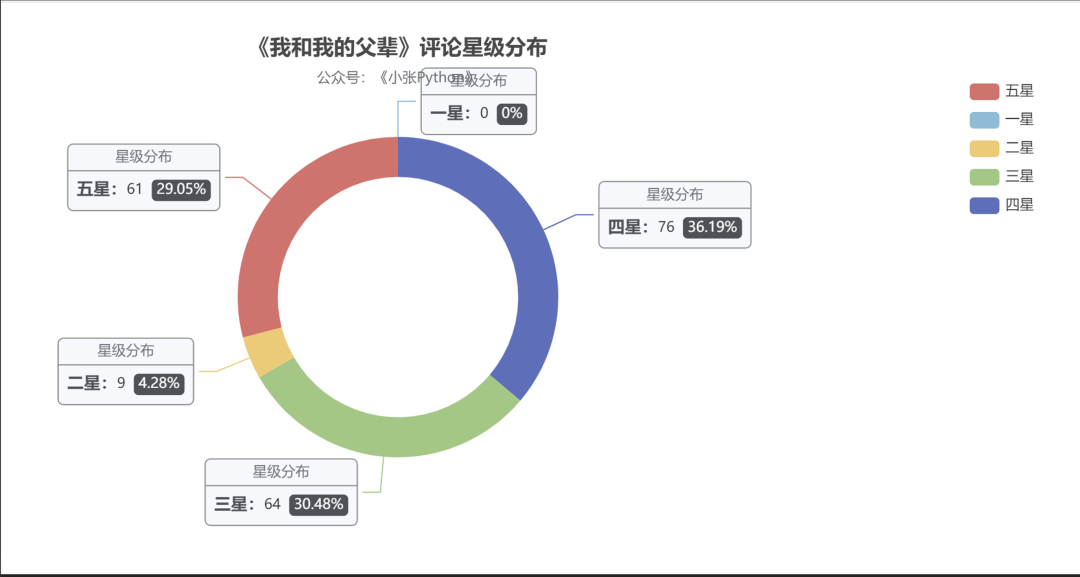 图4
图4从结果来看,《长津湖》的受欢迎程度最高,从采集到的样本中,五星级好评占比高达 45.93,近一半的比例,其次是《父辈》占据 29.05,最后是《少年》 22.6。
但目前在豆瓣上评分是这样的,《长津湖》 7.6,《父辈》:7.0,《少年》7.3,虽然豆瓣影评相对会权威一些,但对这个评分我还是持保留态度,原因见后面的票房分析。
关于一部电影的好坏,只看评分是没有意义的,毕竟评分根据资本的力量是可以改变的, 一部电影最终受不受欢迎,核心的还是票房,看用户愿不愿意为这部影片支付一张电影票的价格。
下面的票房数据来源于猫眼,根据三部电影的票房数据我绘制了两个图表,一个是当天的票房数,一个是自上映日开始的累计票房。
当天票房数统计结果见图5
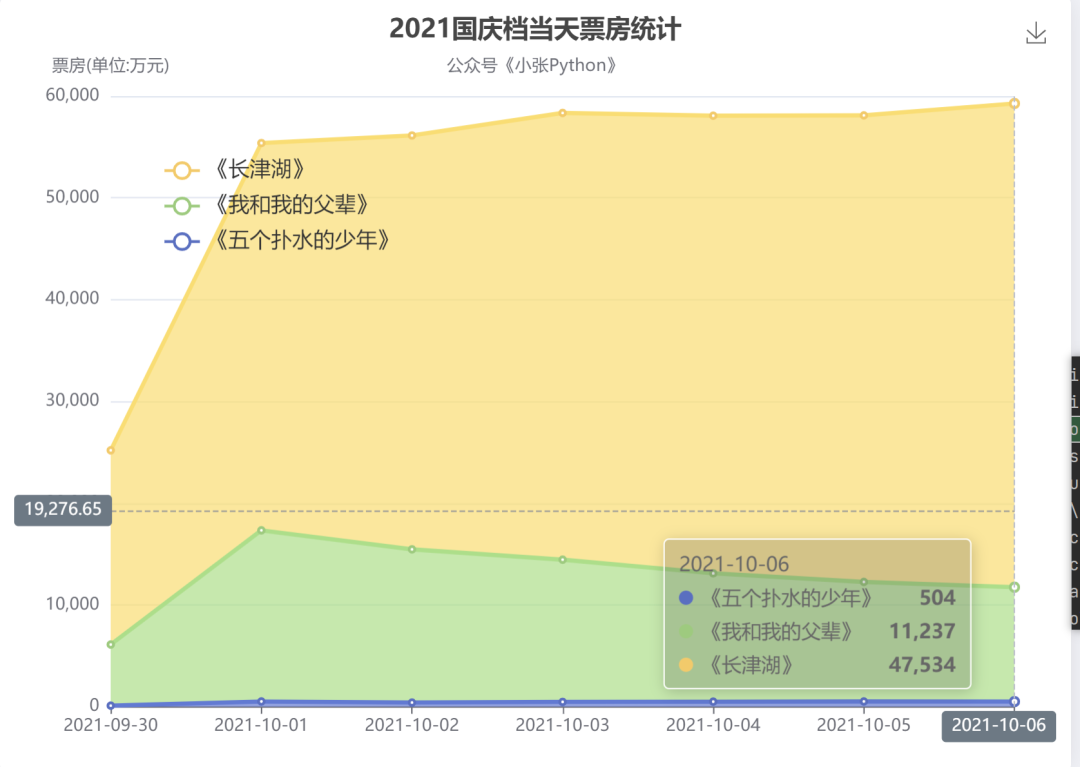 图5
图5看到这个表之后我惊了个呆,如果不加入《票房》统计这一维度的对比,原以为《少年》与前两部就算有差距,但不会差别特别大,看完这个表的数据之后,发现自己还是太年轻了,《少年》的票房与另外两部电影基本没有可比性。
请不要忽略图5 中最下面那条蓝线,那条线就是《少年》每天的票房数据统计
在10月6日这一天,《五个扑水的少年》的票房约500多万,而《长津湖》这一天单日票房仅 4.75亿,这之间相差近 90倍。
除了单日票房外,这里对三部影片的累计票房走势也绘制了一个折线图,结果见图6
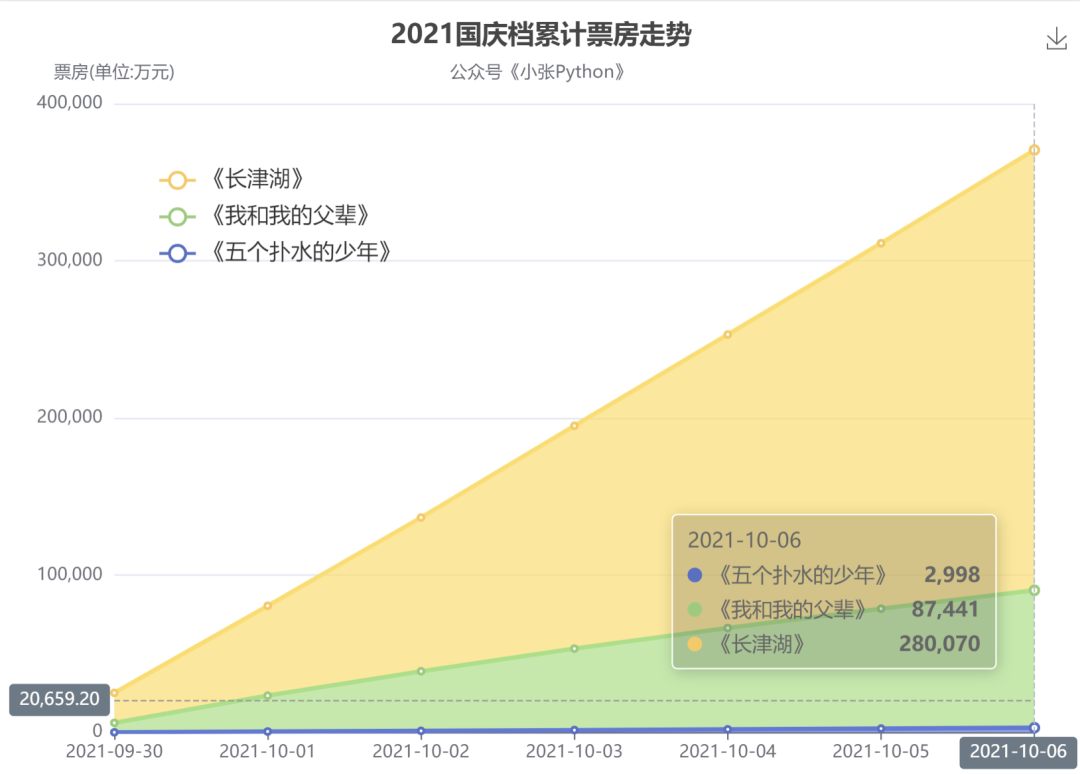
截止到10月6日,《长津湖》票房数累计 28亿,《父辈》累计 8.7亿,而《少年》仅有 0.3 亿左右;
如果说《长津湖》是呈45度直线向上,那么《我和我的父辈》票房走势角度只有 30度,甚至不足于30度;而对比之下,《五个扑水的少年》的票房走势呈几乎水平状态,是真的惨;
影评分析到这里不由地会想起一句话:旱的旱死,涝的涝死。可能一些电影厂商特地会把电影放在国庆、春节 这种大流量的节日中,投资将很可能带来几倍甚至几十倍的收益。但从上面票房对比来看,这个策略不见得很明智,除非影片很受大众的肯定和喜欢,否则可能不但没有收益而且连前期投入的成本都收不回来。
《我和我的父辈》作为国庆档预期较高的一部影片,本以为票房会略低于《长津湖》,但从上面走势来看,《父辈》离后者还是有不小的差距。侧面也可以看出,如今大众群体对于好的电影绝不会吝啬,对于看电影这一娱乐方式我们绝不会亏待自己,但是看一部低质量影片,我们是不能容忍的。
词云绘制
最后,将每一部电影的影评绘制为一张词云图,看看对于每部电影,观众们都说了什么。
在《长津湖》的影评中,提到最多的是历史、志愿军、战争片、美军、震撼 等关键词;而这几个关键词确实与电影题材相符合,彰显现在美好生活的来之不易。

在《我和我的父辈》中,沈腾、吴京 两个导演的名字占据整张词云图的一大部分,受到观众们的喜欢;而对于这部剧的剧情方面的评价,出现最多的就是浪漫、喜剧、感动,虽然情感方面相差较大,但衬托出四位导演之间的不同风格。

原版、翻拍、改编、国产是《少年》这部剧的题材基调,而除此之外并没有看到与这部剧剧情相关的情感评价,也并没有什么好讨论的了。

小结
今年国庆档的影评分析到这里也就结束了,总的来说可以用一句话来概括:以前影片出品方能凭借炒作、前期流量IP宣传为票房创造不少收益,而这种情况在现在很少会发生,现在的观众已经不再那么好糊弄的了。
需要本篇文章中的代码和数据,可在公众号:Crossin的编程教室 后台回复关键词:电影
如果文章对你有帮助,欢迎转发/点赞/收藏~
作者:zeroingi
_
往期文章推荐_












