
循环神经网络 (RNN) 是一种流行的「序列数据」算法,被 Apple 的 Siri 和 Google 的语音搜索使用。RNN使用内部存储器(internal memory)来记住其输入,这使其非常适合涉及序列数据的机器学习问题。
本文介绍引入RNN的问题--Language Model,并介绍RNN的重要公式,作为Stanford cs224n lecture6的总结和补充。
1. Language Model
在介绍RNN之前,我们先介绍最初引入RNN的问题---「Language Modeling」。
「定义:」 Language Modeling就是预测下一个出现的词的概率的任务。(Language Modeling is the task of predicting what word comes next.)
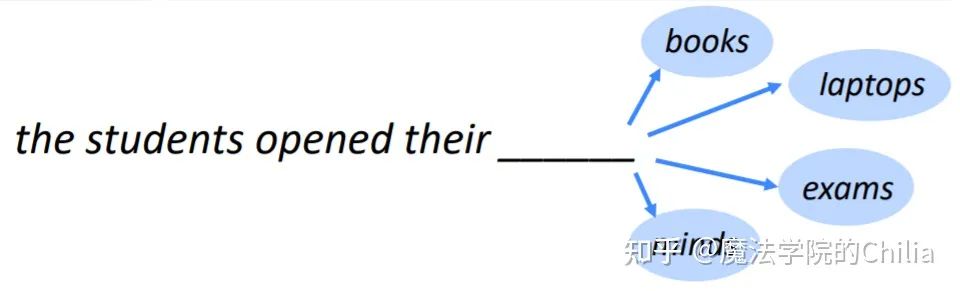
即:
1.1 统计学方法:n-gram language model
简化:一个词出现的概率只和它前面的n-1个词有关系,这就是"n-gram"的含义。因此有:

n-gram model 是不使用深度学习的方法,直接利用「条件概率」来预测下一个单词是什么。但这个模型有几个问题:
- 由于丢弃了比较远的单词,它不能够把握全局信息。例如,“as the proctor started the clock” 暗示这应该是一场考试,所以应该是students opened their 「exam」. 但如果只考虑4-gram,的确是book出现的概率更大。
- sparsity problem. 有些短语根本没有在语料中出现过,比如"student opened their petri-dishes". 所以,petri-dishes的概率为0. 但是这的确是一个合理的情况。解决这个问题的办法是做拉普拉斯平滑,对每个词都给一个小权重。
- sparsity problem的一个更加糟糕的情况是,如果我们甚至没有见过"student open their",那么分母直接就是0了。对于这种情况,可以回退到二元组,比如"student open".这叫做backoff
1.2 neural language model
想要求"the students opened their"的下一个词出现的概率,首先将这四个词分别embedding,之后过两层全连接,再过一层softmax,得到词汇表中每个词的概率分布。我们只需要取概率最大的那个词语作为下一个词即可。
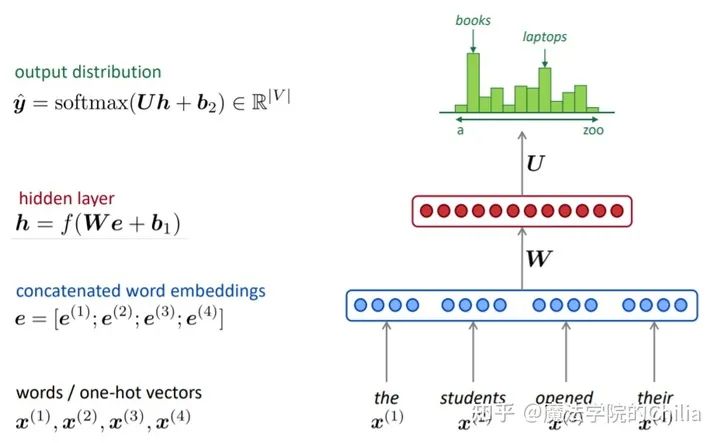
「优点:」
- 解决了sparsity problem, 词汇表中的每一个词语经过softmax都有相应的概率。
- 解决了存储空间的问题,不用存储所有的n-gram,只需存储每个词语对应的word embedding即可。
「缺点:」
- 窗口的大小还是不能无限大,不能涵盖之前的所有信息。更何况,增加了窗口大小,就要相应的增加「权重矩阵W」的大小。
- 每个词语的word embedding只和权重矩阵W对应的列相乘,而这些列是完全分开的。所以这几个不同的块都要学习相同的pattern,造成了浪费。
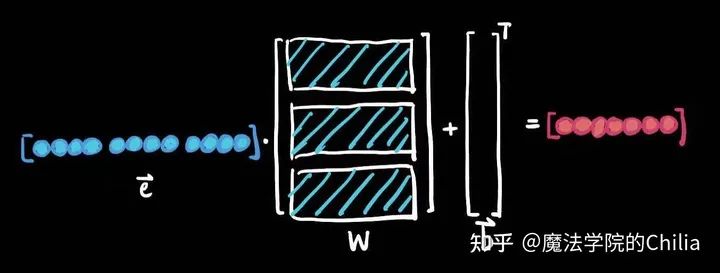
2. RNN
正因为上面所说的缺点,需要引入RNN。
2.1 RNN模型介绍

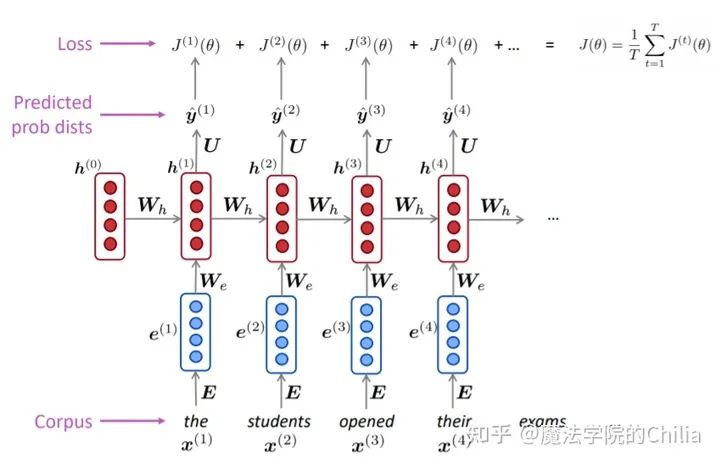
「RNN的结构:」
- 首先,将输入序列的每个词语都做embedding,之后再和矩阵 做点乘,作为hidden state的输入。
- 中间的hidden state层: 初始hidden state 是一个随机初始化的值,之后每个hidden state的输出值都由前一个hidden state的输出和当前的输入决定。
- 最后的输出,即词汇表V的概率密度函数是由最后一个hidden state决定的
「RNN的优势:」
- 前面很远的信息也不会丢失(这样我们就可以看到前面的"as the proctor start the clock",从而确定应该是"student opened their exam"而不是"student opened their books").
- 模型的大小不会随着输入序列变长而变大。因为我们只需要 和 这两个参数
- 对于每一步都是一样的(共享权重),每一步都能学习 ,更加efficient
「RNN的坏处:」
- 实际上,不太能够利用到很久以前的信息,因为梯度消失。
2.2 RNN模型的训练
- 首先拿到一个非常大的文本序列 输入给RNN language model
- 对于每一步 t ,都计算此时的输出概率分布 。(i.e. predict probability distribution of every word, given the words so far)
-
对于每一步 t,损失函数 就是我们预测的概率分布 和真实的下一个词语 (one-hot编码)的交叉熵损失。
2.3 Language Model的重要概念--困惑度(perplexity)
我们已知一个真实的词语序列 ,

即,困惑度和交叉熵loss的指数相等。
2.4 基础RNN的应用
(1)生成句子序列

每一步最可能的输出作为下一个的输入词,这个过程可以一直持续下去,生成任意长的序列。
(2)词性标注
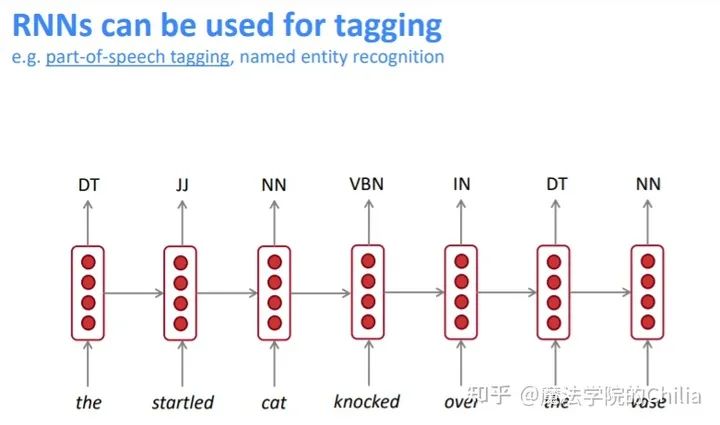
每个隐藏层都会输出
(3)文本分类
其实RNN在这个问题上就是为了将一长串文本找到一个合适的embedding。当使用最后一个隐藏状态作为embedding时:
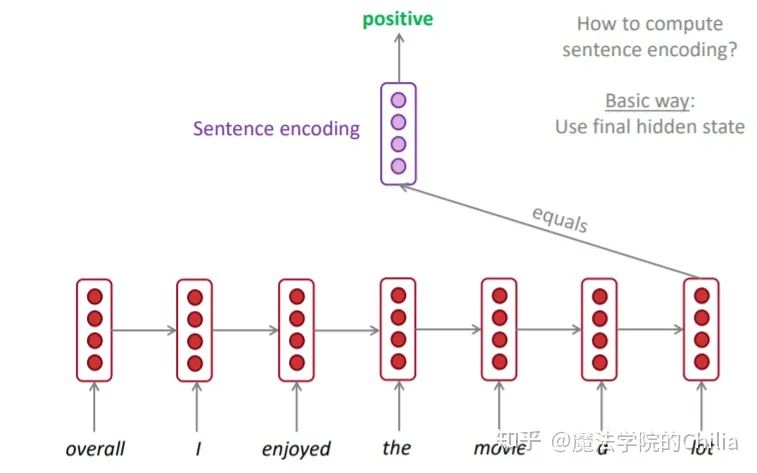
当使用所有隐藏状态输出的平均值作为embedding时:

本文参考资料
[1]
cs224n-2019-lecture06: https://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture06-rnnlm.pdf
- END -

进技术交流群请添加AINLP小助手微信(id: ainlper)
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏







