联合用药对于复杂疾病的治疗至关重要,其基本原理是联合使用靶向多个靶点、通路或细胞过程的药物,这样可以有效降低单一药物治疗的耐药性,提高治疗效果,同时通过减少单一药物的剂量而降低药物带来的毒性。然而,对于海量的可用药物组合搜索空间来说,仅通过经验筛选或高通量实验筛选技术是远远不够的。目前已有多个研究应用机器学习算法预测出具有协同作用的联合用药疗法,以快速、低成本地找到大量有效的新型药物组合。
近日,军事医学研究院伯晓晨、何松课题组在Briefings in Bioinformatics杂志发表了题为Machine learning methods, databases and tools for drug combination prediction的方法学综述,全面评述了近些年来用于预测新型联合用药疗法的机器学习方法以及相关的数据库、软件工具,并总结了该领域目前存在的挑战和未来的相关工作。

机器学习方法工作流程
使用机器学习方法预测新型药物组合的工作流程如图1所示,大致分为以下几个部分:
(1)收集数据。收集样本、标签与特征数据。分类或回归任务使用的标签数据介绍见“联合用药中协同作用的定义(Definition of synergistic effect in prediction Task)”小节。“可用数据库、交互网站与软件工具(Databases, web servers and software tools)”一节综述了研究使用的样本、标签与特征数据库。
(2)建立训练数据集。将收集到的数据进行特征对齐、归一化、拼接或融合等处理,得到用于训练模型的输入(样本特征数据)与输出(样本标签数据)数据。
(3)训练模型。构建机器学习模型,使用建立的数据集训练模型、并优化模型参数。
(4)评估模型性能。使用多种验证方案与指标评估模型性能,验证方案包括交叉验证、外部测试集验证、文献验证、实验验证等。
(5)可解释性分析。解释预测过程,提取影响预测结果的关键因素,探讨输入与输出的非线性关系与预测相关的作用机制。“用于联合用药预测的机器学习方法(Machine learning methods used in drug combination prediction)”一节综述了应用于联合用药预测的不同机器学习方法的工作流程、算法特点、验证方案、评估指标、解释性分析以及研究的优缺点。
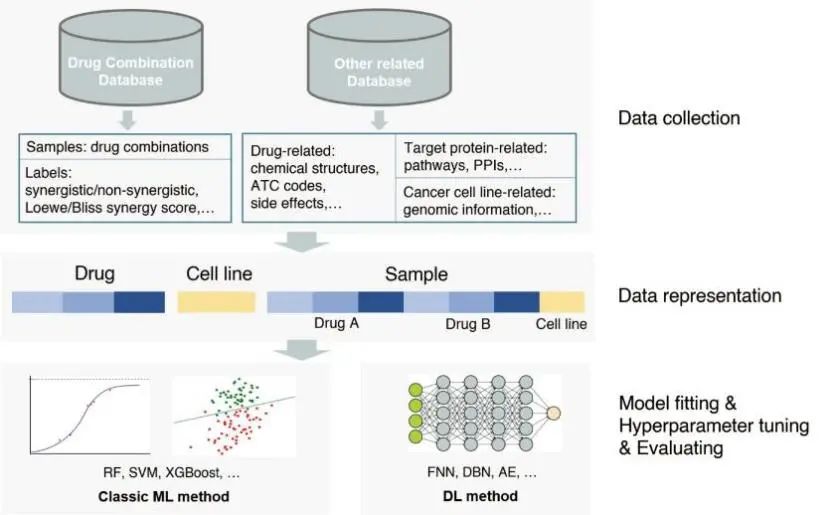
图1 联合用药预测中的机器学习方法工作流程
联合用药中协同作用的定义
联合用药的预测通常可分为分类和回归任务。在分类任务中,联合用药的作用效果常被分类为协同、加和与拮抗作用,也有研究者们增加了强协同、强拮抗等的类别。在回归任务中,目前该领域尚未对协同、拮抗作用的量化模型和准确定义达成共识,最为广泛使用的两个协同效果的计算模型分别是Loewe additivity model和Bliss independence model,它们可根据生物实验获得的细胞反应数值进行计算,得出相应的分数量化该药物组合的协同效果。本节针对这两个计算模型的定义及区别进行了介绍。
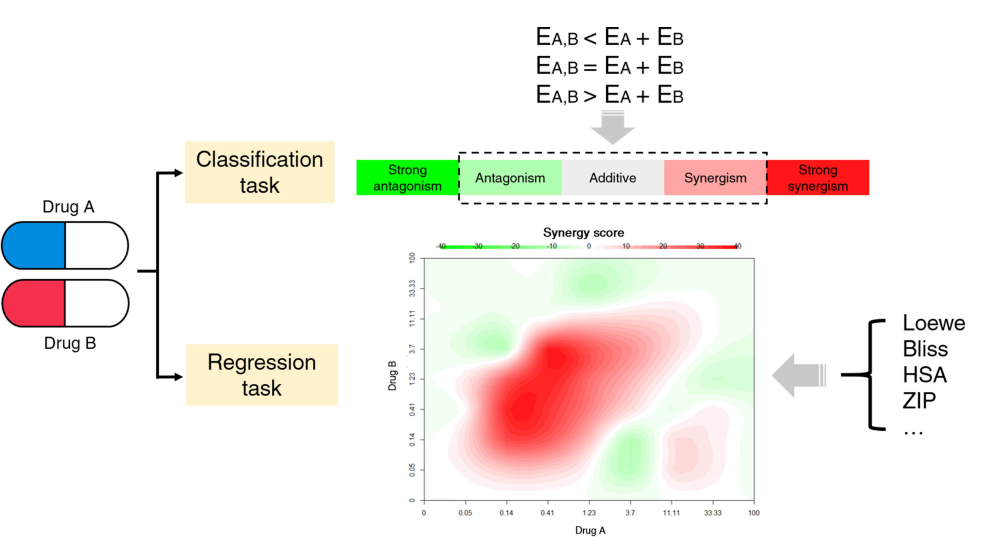
图2 药物组合预测中的分类和回归任务
可用数据库、交互网站与软件工具
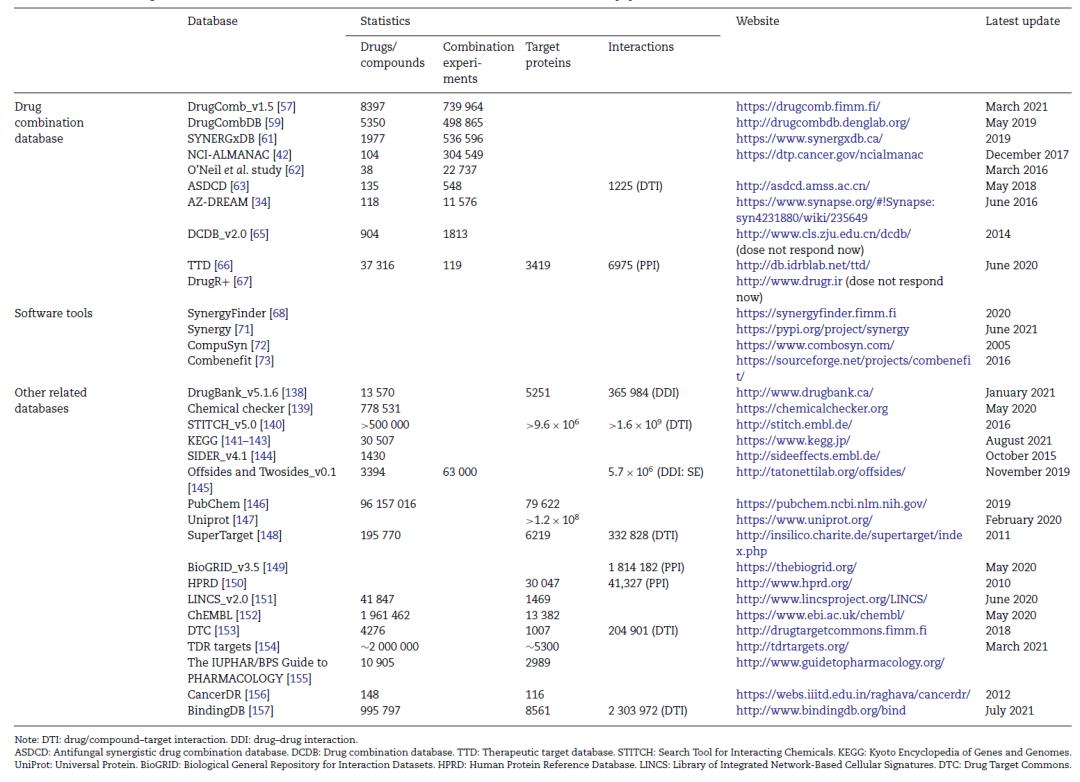
本节综述了提供样本与标签数据的药物组合数据库与提供特征数据的其他相关数据库,以及可在线查询或计算协同作用效果的交互网站与软件工具。涉及数据库的部分统计信息见表1。
表1 本文综述的部分数据库的统计信息
用于联合用药预测的机器学习方法
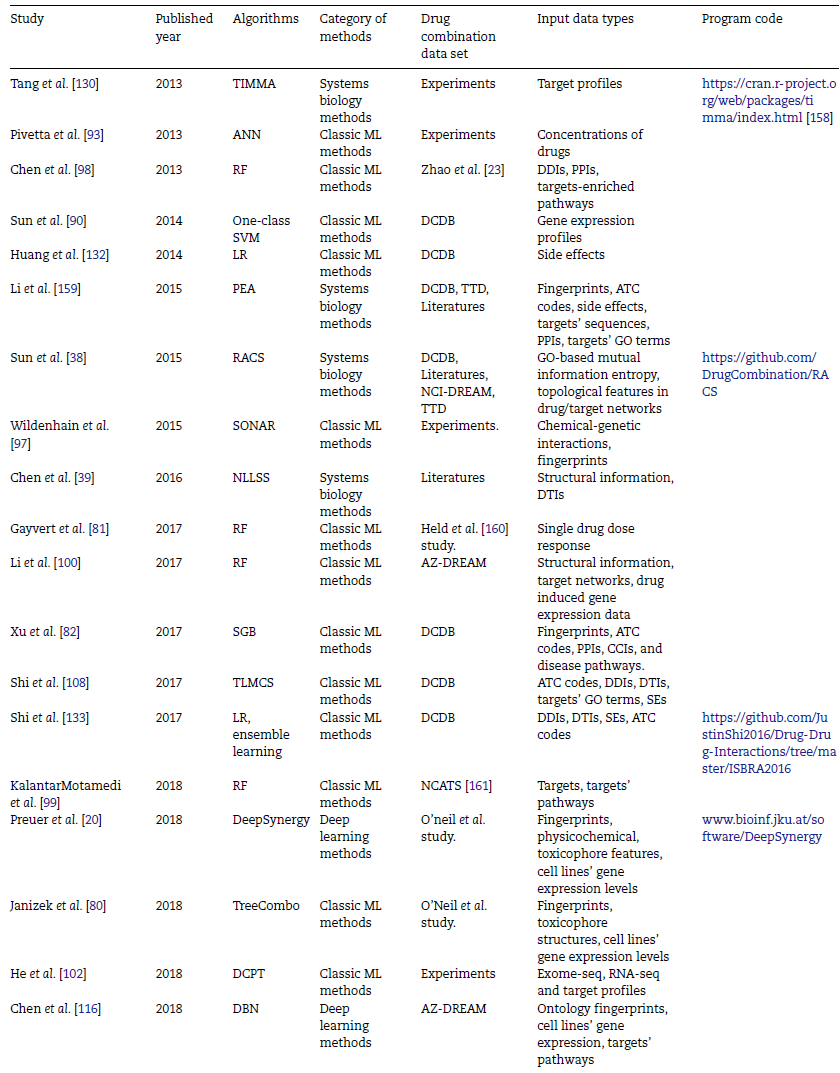
广泛使用的机器学习方法可分为传统机器学习方法与深度学习方法,传统机器学习方法包括支持向量机、随机森林等,深度学习方法包含前馈神经网络、图神经网络等。由于其具有多个处理层的结构特点,深度学习方法需要大量的训练数据、超参数、计算资源与内存,其性能会根据训练数据量的增加而大大提高,尤其适用于超过数十万个样本的大规模数据集。而在中小型规模的训练数据集上,传统机器学习方法的预测性能可能会优于深度学习方法。在本文综述的多个算法中,多数传统机器学习算法会用到多种特征类型进行样本表示,而深度学习方法仅使用结构和物理化学性质信息来表示药物,表2列出了文章综述的部分方法使用的输入数据与相关信息。此外,一些传统的机器学习方法相比深度学习方法更具有解释性。
表2 文章综述的部分方法使用的输入数据与相关信息
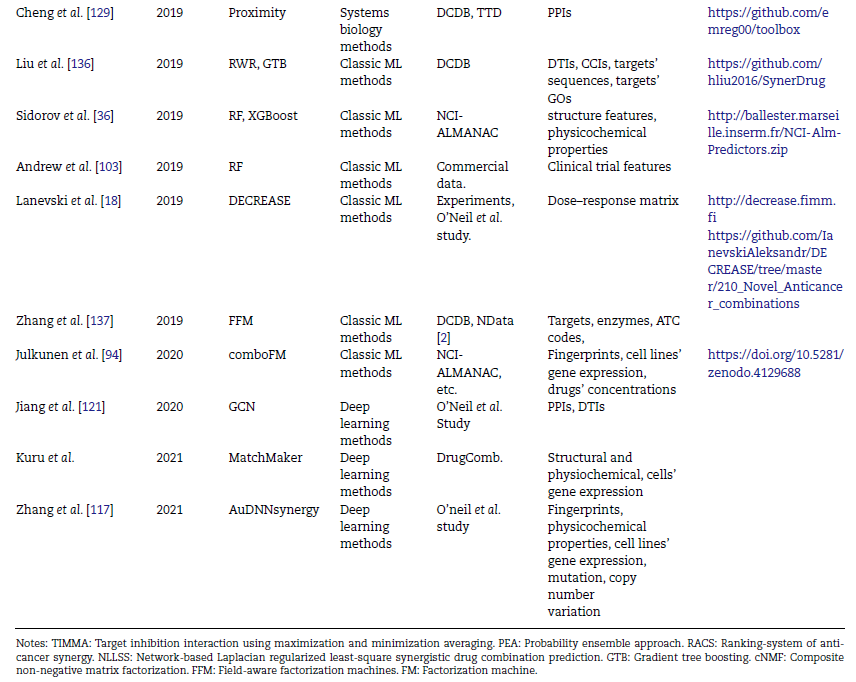
传统机器学习算法分为基于单一模型与基于集成学习的算法两类,如图3所示。基于单一模型的算法指仅使用一个分类器或回归器进行预测,例如决策树。而基于集成学习的算法集成多个单一模型(基分类器)的预测结果,因此常具有更高的预测性能,例如随机森林。本文针对具有高性能或特色结构的算法进行了介绍与评价。
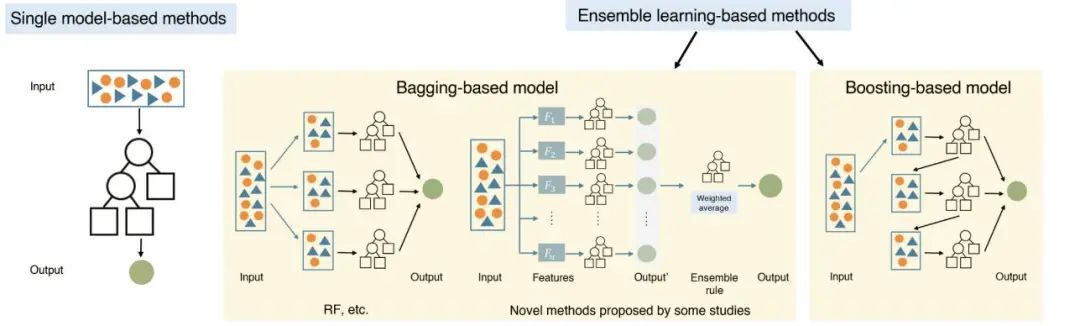
图3 传统机器学习方法的框架
深度学习方法具有多个数据处理层,能够更好地拟合输入与输出之间的非线性关系。本文重点介绍了五种应用于联合用药预测的深度学习方法,前馈神经网络、深度信念网络、自编码器、图卷积神经网络、可见神经网络。
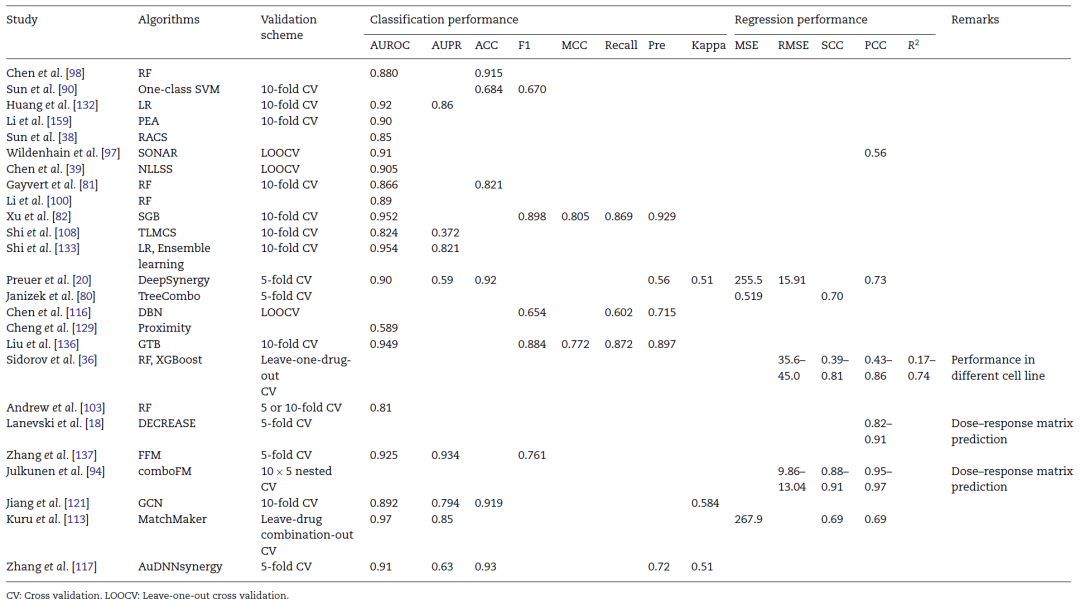
图4展示了文章综述的部分典型机器学习算法的工作流程。表3列出了本研究综述的部分研究的验证方案与评价指标结果。
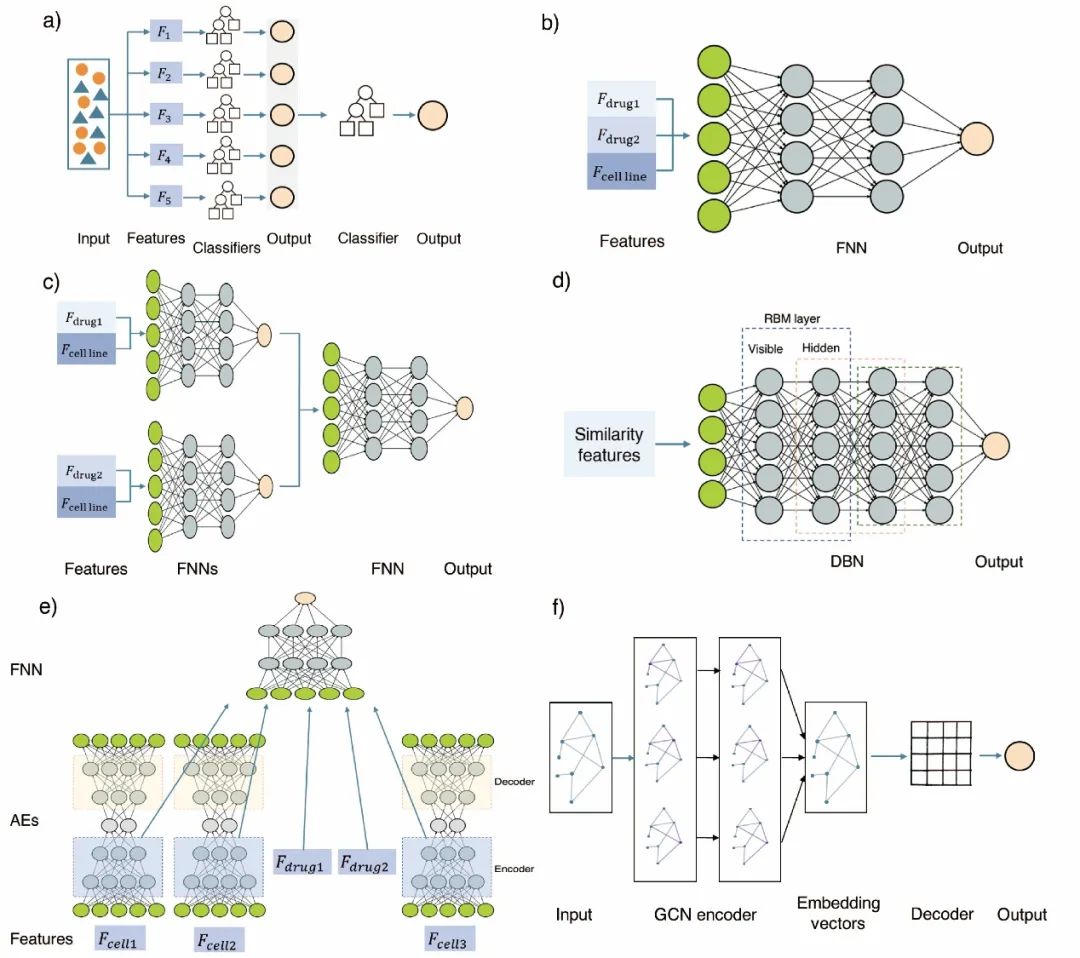
图4 典型算法的工作流程
表3文章综述的部分算法的验证方案与性能指标结果
挑战与未来的工作
目前,学术界与工业界都致力于“机器学习+联合用药”的技术研发。学术界举办了两次DREAM挑战提升联合用药的预测性能,同时,许多新兴的生物制药企业也在结合多种机器学习算法进行联合用药研发。该领域中已有多项研究取得了较高的预测准确率,也存在着诸多挑战。本节列出了该领域存在的挑战与未来应当展开的研究工作。
(1)样本数据有限、模型缺乏泛化能力
样本数据中包含的肿瘤细胞系与药物数量有限,将影响预测模型的泛化性能,大多数方法难以泛化到新药和新细胞系上。未来的研究可通过增加外部测试集、在算法中添加正则化技术以提高模型的泛化能力。
(2)缺乏生物属性的特征类型
领域内性能最优的方法通常使用物理、化学属性表征药物,使用未被药物处理的细胞系的基因表达谱表征肿瘤细胞系,这可能会忽略了药物与细胞系之间的联系。未来的研究应考虑增加更多生物属性的特征类型,例如药物扰动的细胞的基因表达谱。
(3)标签数据不一致
研究人员尚未对协同、拮抗作用的量化和准确定义达成一致,已有的十多种量化模型计算出的量化协同作用可能具有截然相反的结果。未来的研究应集中于准确量化协同或拮抗作用,或在构建训练数据集时筛选出标签准确的样本。
(4)缺乏对拮抗作用的研究
拮抗作用在联合用药疗法的研究中也很重要,可能与多药副作用、联合用药的毒性有关。
(5)缺乏对联合用药剂量范围的研究
药物组合的协同效应取决于两个药物的剂量。药物组合经常被发现在一个范围内具有协同作用,而在另一个范围内具有拮抗作用。未来的预测研究中应该考虑给出联合用药协同作用的剂量范围。
(6)分类任务中存在类别不均衡问题
分类预测研究使用的训练数据集通常存在类别不均衡的问题。具有非协同作用的药物组合被视为负样本,其数量通常是协同组合(正样本)的10倍以上。分类研究中通常使用AUROC或Accuracy指标对预测模型进行性能评估。然而,当面对类别不均衡的训练数据集时,应用AUROC与Accuracy指标评估模型性能并不准确。F1分数、BACC、MCC和其他更多指标将更好地反映该问题的模型性能。
(7)模型缺乏可解释性
模型的可解释性对于生物医药领域的预测模型至关重要。利用预测模型、尤其是深度神经网络模型,虽然可以得到相对准确的预测结果,但研究人员无法了解其预测过程,以及影响预测结果的关键因素。已有一些工具可以帮助模型提取训练集中的关键特征,如TreeSHAP和DeepSHAP。然而,这依然难以解释生物过程的作用机制。
(8)与湿实验结合不足
构建模型实现预测后,可以通过湿实验验证筛选的药物组合。实验结果可用于调整计算模型,以获得更好的预测效果。
天津大学的硕士生武连莲、军事医学研究院的博士生文昱琦为该论文的共同第一作者,军事医学研究院伯晓晨研究员、何松副研究员为该论文的共同通讯作者。
原文链接:
https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbab355/6363058
【非原创文章】本文著作权归文章作者所有,欢迎个人转发分享,未经允许禁止转载,作者拥有所有法定权利,违者必究。











