在实践中,特征工程目前依然是建模过程中最为核心的一块,也是提升最快最简单的部分;有些公司的搜索推荐团队只使用了embedding相关的信息,并希望通过embedding的交叉或者序列等信息建模得到最终的推荐结果,并没有加入非常多人为构建的特征。
但在很多的场景下,特征工程还是非常重要的。尤其是在有好几年数据积累的场景中,数据量是非常大的,甚至可以上PB级别,在建模的过程中基本上是不大可能把所有的数据全部使用上,我们一般会选择使用最新的数据,但为了尽可能不浪费老的数据信息,会选择通过特征工程的方式从老的数据集中提取尽可能多的信息。为模型带来提升,而在我们的实践中,也发现,特征工程带来的提升还是非常大的。
为了消除数据特征之间的量纲影响,让不同特征之间具有可比性,需要对特征进行归一化处理。常用的的归一化方法有Max-Min归一化、Z-Score归一化。
在实际应用中,特征归一化并不是万能的,但线性回归、逻辑回归、SVM、NN等模型需要通过梯度下降发求解的模型通常是需要进行归一化的。
类别特征常见的策处理略:
Target Encoding
Count Encoding
Categorifying
Target Encoding
Count Encoding
Categorifying
详细的文本特征可以参考炼丹笔记往期干货《数据挖掘20大文本特征》。
expansion编码
consolidation编码
文本的长度特征
标点符号特征
特殊词汇特征
词频特征
TF-IDF特征
LDA特征
上面内容更多的是一些基础的特征处理技巧。很多较为传统,如果转化业务中该如何构建特征工程呢?此处我们描述一套特征框架,过多的细节不阐述,毕竟是很多大佬打磨了很多从非常多的实践中实践得到的,而且也不一定各种业务都会100%有效。
首先我们建模的目的是为了预估:
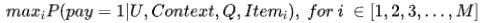
其中,
- 是上下文相关的特征,例如时间,访问使用的app等;
找到所有商品中最有可能被购买的那一件,然后曝光给用户。从上面的定义中,我们可以发现,特征至少可以划分为下面的几块。
这块特征实在是有些多,还有一些专门做用户画像的组。包含的特征有很多:
- 用户的固定属性特征,比如:用户的性别、年龄、身高其它信息;
- 用户的历史统计特征,比如:过去某段时间的购买率、点击率、消费次数、平均每次消费额、平均消费间隔、最近一次消费的时间等等。
- 用户的其它特征,比如:喜好特征, 实时行为建模,更细粒度的对当前请求下的兴趣刻画与描述等等;
这块特征非常多,很多组都有一套自己的特征组。
和用户的特征类似,商品的特征也是海量的:
- 商品的固定属性特征,比如:商品的上架时间、商品的体积、商品的价格、是否是当季商品、是否促销、是否有优惠活动等等;
- 商品的历史统计特征,比如:商品的历史点击率、商品的曝光次数、商品的加购率、商品的购买率、商品上次被购买的时间等等;
- 商品的其它特征,比如:商品是否有代言,代言人,代言人的粉丝情况等等;
这块特征非常多,很多组都有一套自己的特征组。
这块在搜索相关的竞赛中,也是非常多的,参见阿里妈妈IJCAI2018年的竞赛:
- Query的固定属性特征,比如:Query的embedding,Query中关键词的统计信息;
- Query的历史统计特征,比如:Query的历史出现次数,Query的历史点击率,购买率等等;
这块的特征和用户以及商品是类似的,也是自成一套。
特征交叉这块是探讨最多的,因为交叉信息实在是太多了,从很多大佬的分享以及相关的数据竞赛最后的分享方案中,我们也发现:短短的几个原始字段在进行交叉之后都可以得到成百上千的特征,更别说是在工业界了,工业界的字段都有几百个,甚至会有上千个,所以这块要是单纯的做特征交叉,可以枚举几个月甚至几年。
从kaggle的诸多特征专家写的write-ups来看,特征又可以分为:二阶的交叉,三阶的交叉,四阶的交叉......
这么做下去,几乎是一个天文数字,再加上这么大的数据量,我们对每个新构建的特征进行验证,耗费的资源也将会是一个天文数字,而且存储资源也是无法接受的,举个最简单的例子,我们做用户和商品的二阶交叉特征,
- 在很多朋友,用户都是上千万甚至是上亿的,商品的个数更不用说了,最少也是上百万的,所以简单的交叉可能会带来上亿*上百万的个数,当然实践中肯定没这么多,如果从存储的代价角度看,这将会是一个非常巨大的负担。
- 从上面的角度来看,做用户和Query和商品的三阶交叉将会是一种巨大的负担。
大家都知道这些特征是非常有用的,但是直接做交叉的代价又是巨大的,怎么办呢?我们可以使用下面的两个技巧来进行处理。
1.Top截断:
这几乎在所有的大数据竞赛中都有提到,例如IJCAI18年的竞赛就是,在我们的数据量非常大的时候,我们会选择保留排序之后TopN的信息,例如:
- 保留用户最常购买的TopN个Item的点击率,购买率等等;
- 保留用户最常访问的TopN个Query的点击率,购买率等等;
- 保留Query下最常购买的TopN个Item的点击率,购买率等等;
2.转变为分布表示:
该技巧也主要来源于推荐相关的竞赛,以及AAA21年最新的竞赛分享中,大致的思路是将原先的直接统计user+item的信息转而去统计其它的特征:
- 先统计商品的历史点击率,然后拼接到商品信息中,当做商品的统计信息,然后再统计用户关于商品的这些统计信息的统计特征。
该方法被称之为用商品的点击/购买分布来表示用户。类似的,商品也可以用用户来表示,即。
- 先统计用户的历史点击率,然后拼接到用户信息中,当做用户的统计信息,然后再统计商品关于用户的这些统计信息的统计特征。
这种用交叉信息的一侧主体的统计信息来表示另外一侧主体的策略也是极其方便的一种策略。
这块的特征如果从技术的角度来看都是可以被包含到上面的几大类中的,但是因为这些特征是通过最新的一些硬件或者其它的技术发展带来的,例如边缘计算等,此处我们将其单独列举出来作为一节。
最典型的一些特征就是阿里巴巴EdgeRec文章中所列举的:
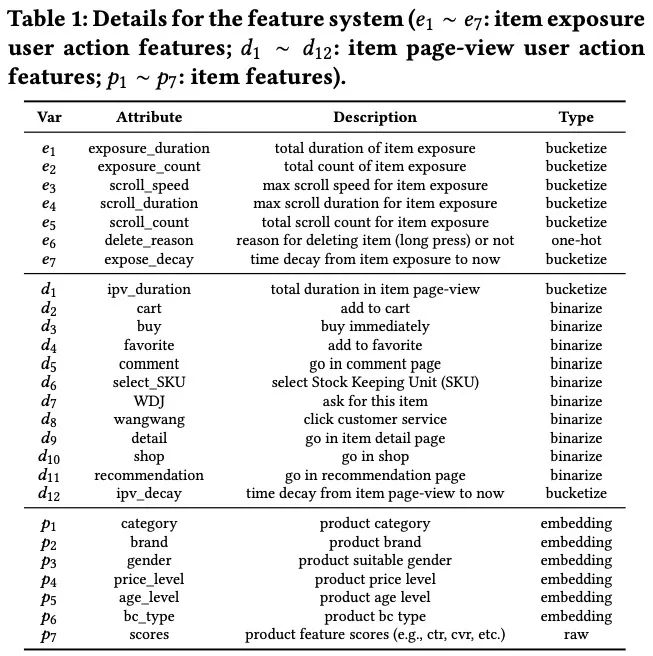
这个在KDD20的竞赛中有看到,大致就是利用模型上游的很多统计或者其它模型输出的一些特征,每个公司产出的可能不一样,此处不做过多描述。
上面的特征工程只是冰山一角,因为随着业务相关的数据集的扩充,肯定也会涉及到非常多其它相关的特征。比如与图片相关的特征,用户购买商品之后对于商品的文字评价等等诸多的信息,这些都可以作为商品或者用户商品相关的信息加入模型。
整体来说,特征作为模型的输入能带来非常大的帮助,所以还是非常重要的,我们通过特征工程的方式能在原先的基础上带来非常大的提升。






