李猛,数据领域专家,Elastic Stack国内顶尖实战专家,国内首批Elastic官方认证工程师21人之一。2012年入手Elasticsearch,对Elastic Stack技术栈开发、架构、运维、源码、算法等方面有深入实战经验。负责过多种Elastic Stack项目,包括大数据分析领域、机器学习预测领域、业务查询加速领域、日志分析领域、基础指标监控领域等。十余年技术实战从业经验,擅长大数据多种技术栈混合,系统架构领域。
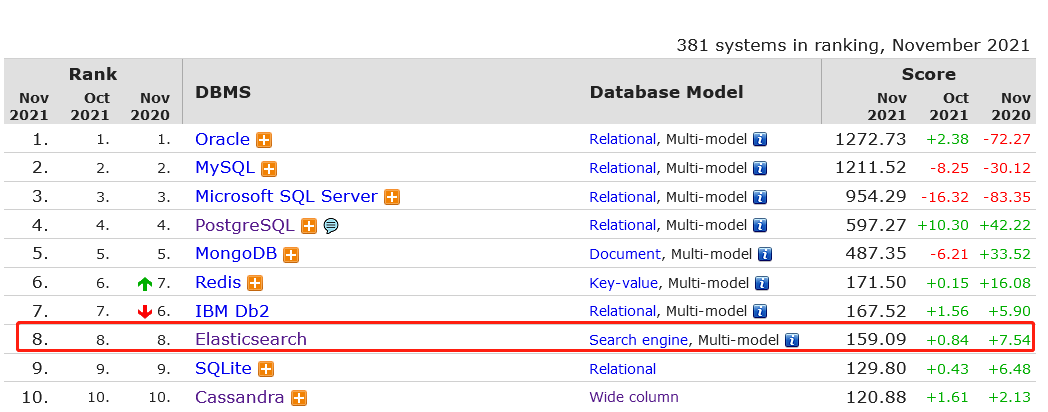
图示:Elasticsearch目前在DB-Engine综合排名第8
Elasticsearch博大精深,提供了非常丰富的应用场景功能,也提供了丰富的API命令操作,有些API非常好用,有的API用一用就要出大事,防不胜防。
以下围绕某客户一次客户端应用程序生产事故错用Cluster State命令展开,从问题定位到问题解决,记录自己的过程与方法,还有一些心得总结(注:具体客户信息不便透漏,以下部分图片信息仅为示意图)。
客户属于传统型金融行业,ES用来解决日常的数据查询与存储,利用ES非常好的横向扩展特性,满足多种场景应用。
ES集群版本属于5.6.x,已经超出Elastic官方支持的版本,集群节点数不到10个,节点硬件配置属于均衡一致性,标准的性能型合理范围硬件配置,应用于业务系统提供查询或者更新等,日常都有提供定期巡检,基本正常稳定,不过一直侧重的是集群运维本身,很少会深入到应用端程序去巡检分析,业务线太多,经费有限。
ES集群设置并未采用Master与Data分离设计,所有节点均是同等角色权限。ES集群数据量也是属于正常支撑能力范围,集群索引的分片数量在2w以上,注意这个数字,后面会基于此来突破寻找问题。
客户端应用程序基于Spring data elasticsearch开发框架,引用Trasnport-client直连模式,中间未采用任何代理Proxy负载产品。
客户端应用程序部署了多个实例,按照2的倍数增加,需要做一些“大量”数据的写入与查询,瞬间并发的操作ES集群,无论怎么操作,ES的并发数并不高,但应用端程序就是运行不快,这很不合常理也不合事宜,常识告诉我这不正常。
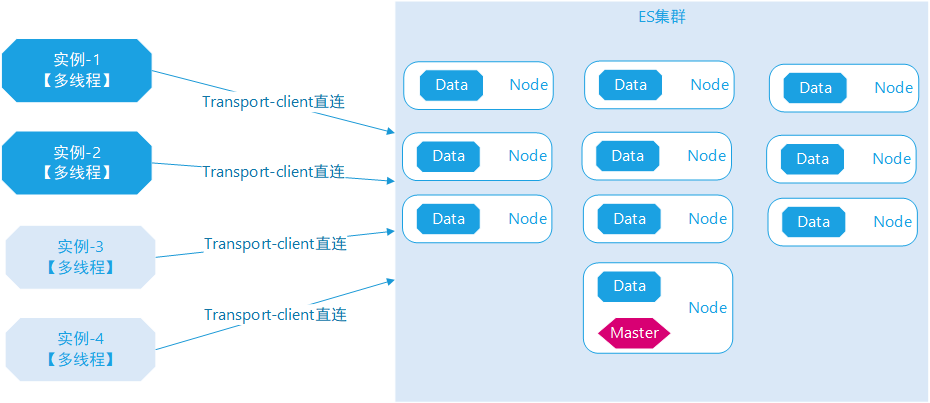
图示:客户公司的应用项目架构示意图,客户端采用Transport-client直连模式
客户端应用程序只要开始运行,ES集群立刻会慢起来,但查看ES集群整体资源消耗,ES所在节点CPU/MEM/硬盘IO并不高,其数据节点甚至非常低,远远没有达到节点的瓶颈。
经过细细观察发现,集群的Master节点流量特别高,其余节点数据流量都传给Master节点,超出了Master单节点网络IO的极限,这显然不正常。但在生产环境上并不容易排查。后面经过在本地开发环境模拟压测,终于确定了问题来源,是客户端的某个集群管理操作 API引起的。
最终,找到了 Cluster State Api 统计命令引起的,客户端应用程序每次做实际业务前,都会调用这个API命令获取集群一些索引与Mapping信息,由于客户端是采用多线程设计,且部署多个实例,只要并发数高,所有流量必然打到Master节点,造成整个集群响应慢。由于整个集群有近2w个分片,执行一次State 命令,需要统计汇总集群所有索引分片信息,并最终汇总到Master节点,造成实际Master节点网络IO超过极限。
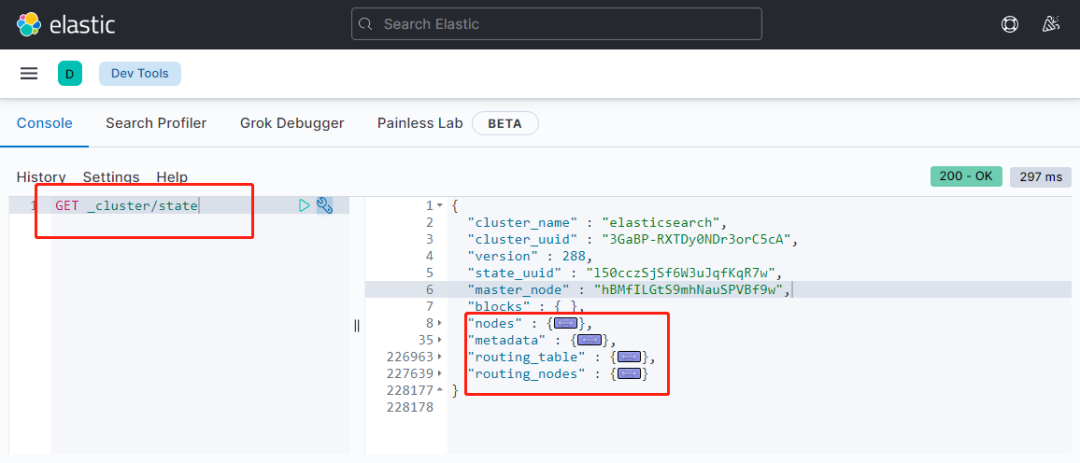
图示:cluster state api返回内容,索引越多,返回内容越大。
以上我们快速讲了一下问题现象与事故原因, 下面重点聊一下问题排查过程以及采用的工具方法思维等。
特别说明,由于是远程协作分析排查以及客户公司的行业特性,外部不能直接操作远程任何节点,必须通过客户公司运维人员间接指导操作排查,过程稍微有点曲折。
首先是ES集群问题排查,这是很正常直接的思维,在问题爆发点排查(ps:类似警察先赶到案发现场,采集证据)。由于集群版本是5.6.x,一些原因并未启用官方的XPack功能,所以也就没有自带的Kibana监控可视化报表,国内早期多数用户都是采用开源免费版本搭建集群,客户公司基于Zabbix搭建有集群节点的基础指标监控,总算是有一个,非常难得。
1)zabbix监控分析
很快基于Zabbix展开各个ES机器节点指标监控分析,按照常规套路,分析了CPU、内存、磁盘IO等一切正常,并不高。这就非常令人困惑,明明集群响应很慢,客户端应用程序开发人员也如实反应,部署的实例非常少,所以初次分析下来,并未发现明显定位到问题。
接着分析节点网络IO,貌似发现了问题点,其中Master节点流量特别高,超出了网卡的极限;按照此套路,继续查看了其它数据节点网络IO,也比较高,然后观察发现,数据节点的网络IO流量累计起来刚好等于Master节点网络IO流量,终于算是找到了一个突破口。
注意,基于Zabbix虽然能监控各个独立节点的网络流量,但并不能看到节点之间网络流量,以及应用客户端与服务端之间,这很不友好,若有一张全网络流量图,将会更容易定位分析问题。
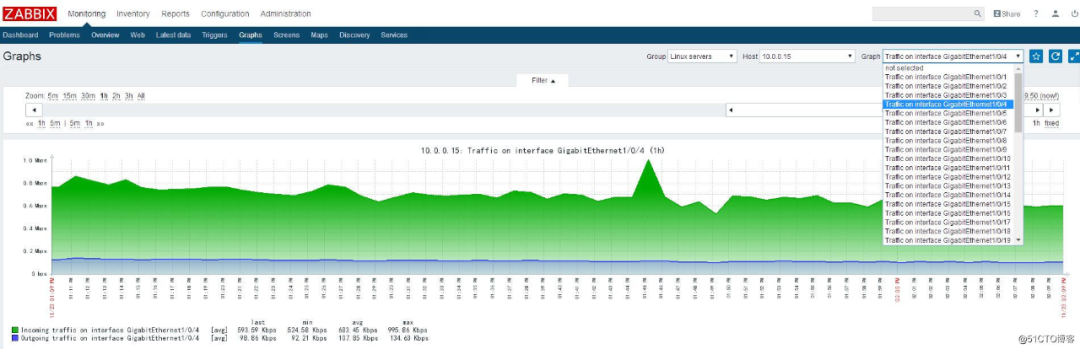
图示:Zabbix 网络流量示意图,仅仅能快速查看单独节点
2)iftop监控分析
借助Zabbix算是找到了突破口,接下来就需要一张网络流量关联图。此时第一个想到的是 Elastic Stack Packetbeat 网络IO流量包可视化监控监控,瞬间与客户公司讨论,能否安装配置,显然这个过程太慢,需要申请更多资源等麻烦,时间预计来不及。后面客户公司运维工程师临时安装 Linux 络指令iftop,终于能够分析ES所有节点网络IO流量的流进流出方向,但是观察分析相对来说比较痛苦,而且并不能绘制一个网络图谱,所以观察起来还是不够全面。
iftop仅仅在单机节点执行,所以只能看到单个节点的网络流量进与出,不过这已经非常好了,只是时间长一点。
基于网络IO流量进出初步分析观察,很快做出了决策,先是重启了现有Master节点,让ES集群重新选举新的Master,结果发现依然新选举的Master节点流量依然巨大;接着也临时申请增加2个新的ES节点,以为可以分散客户端访问的压力,事实上并未从根本上排查解决。此时的判断是认为某些业务索引查询,造成流量比较大,刚好在Master节点中转汇总,这里其实还没有分析到客户端的流量,所以做了一些无用的紧急服务端调整,但也证明了问题不在ES服务端。
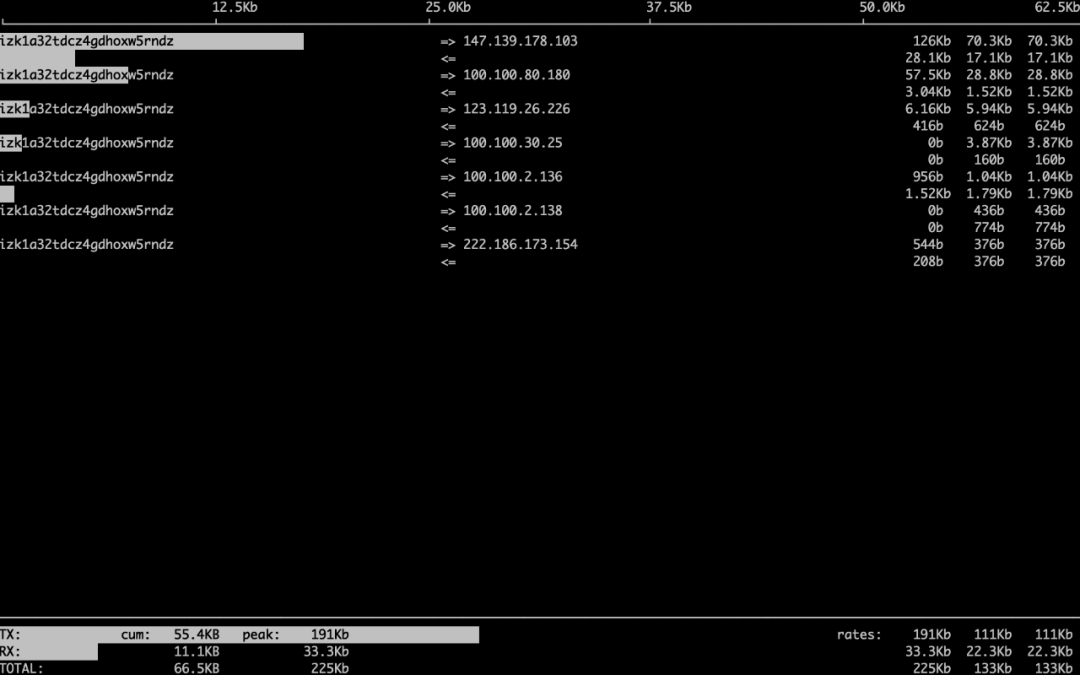
图示:iftop网络流量示意图,能分析到单节点的流量进出,也是不错了
3)packetbeat监控分析
由于一些原因,并未部署Elastic Stack 监控分析产品,特别推荐Packetbeat网络流量监控分析产品,官方默认提供的网络流量图,非常有用,可以更快速定位流量走向,相比ittop,更加全面一些,可以总结为iftop的网络版本。Packetbeat内置官方一些可视化报表,如果觉得不够,可以基于ES提供的分析能力自行设计。
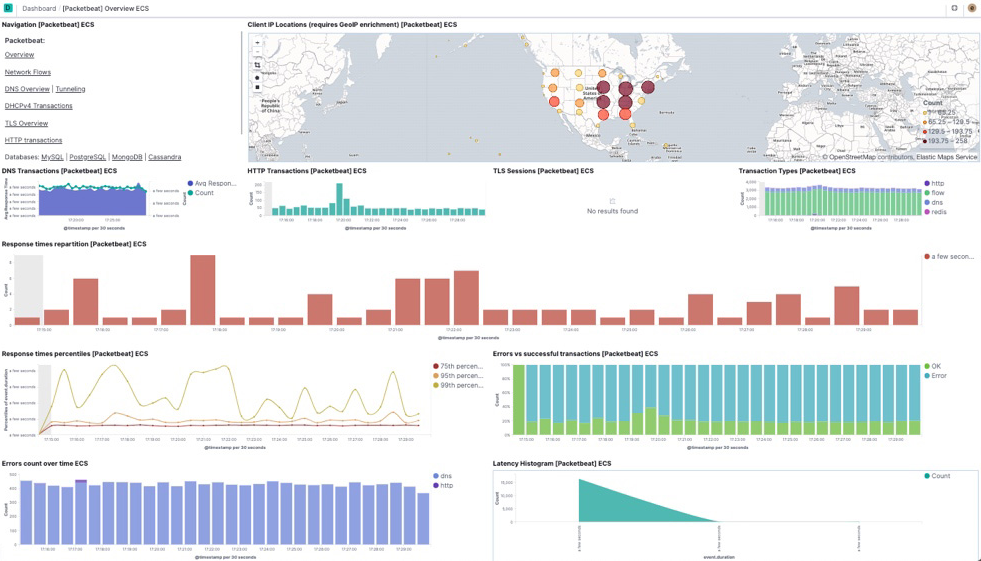

图示: packetbeta网络IO流量监控分析图,输入与输出
其次是从客户端应用排查。但实际上,客户公司运维人员第一时间发现问题,联系到我,我的第一个问题就是客户端应用在做什么业务,业务类型是什么。运维人员也如实告知正在做的业务类型以及应用情况,其实只能概要说明一下,详细的业务操作流程与影响的是不知道的,对于我来说,反正就知道了有个业务操作在影响着集群,具体怎么影响,还得继续排查。必须说明一下,这个可能是国内IT运维界的通病,看起来运维属于末端支持,本质更应该参与到业务系统的前沿阵地,从业务开始了解背后的运维问题。
然后通过ES服务端排查,掌握了一些信息,但远远不足以定位到问题,客户端排查就任重道远,必须要找出问题所在。ES集群响应慢有很多,但服务端只能发现问题,并不能从根本上解决,于是通过在服务端运行 thread_pool 与 task 命令,发现了集群的管理线程池特别多,任务一直爆满,这不正常,这就更加肯定一定是客户端的某些应用在恶意操作这些命令。
1)thread_pool 监控分析
集群响应慢,集群线程池是一个必须考虑的点,其中会查看到累计的任务量,经过打开指令观察,其中的 management 线程池特别高,由此判断客户端正在做一些任务,且属于management 线程池的,目前具体的依然不能确定,因为没有看到客户端应用具体的代码调用方式。

图示:thread_pool示意图,可以监控ES节点任务数
2)task监控分析
借助thread_pool分析,可以定位到 management 线程池正在大规模做任务,同理借助task 查看分析 具体做的任务是什么。(ps:实际客户环境中,发现是大量的state、stats任务,其中state任务数明显要高,且非常不正常,这里不方便透漏,后面会详细列出如何压测出来此结果)

图示:task示意图,可以查看到具体的任务类型
3)stats监控分析
借助 task 监控分析,发现有大量的stats指令,接着在服务端执行一次,看看情况如何,实际发现响应也比较慢,但按理是正常的,产生的队列次数并不高,只是执行慢,基于以上判断应该是别的任务阻塞导致。
stats 负责集群监控检查响应,常规的集群yellow,red,green就来自与此;另外也收集索引的统计信息,节点的统计信息,返回的数据量不多,常规下可以忽略不记,不过注意后面transport-client 访问需要。
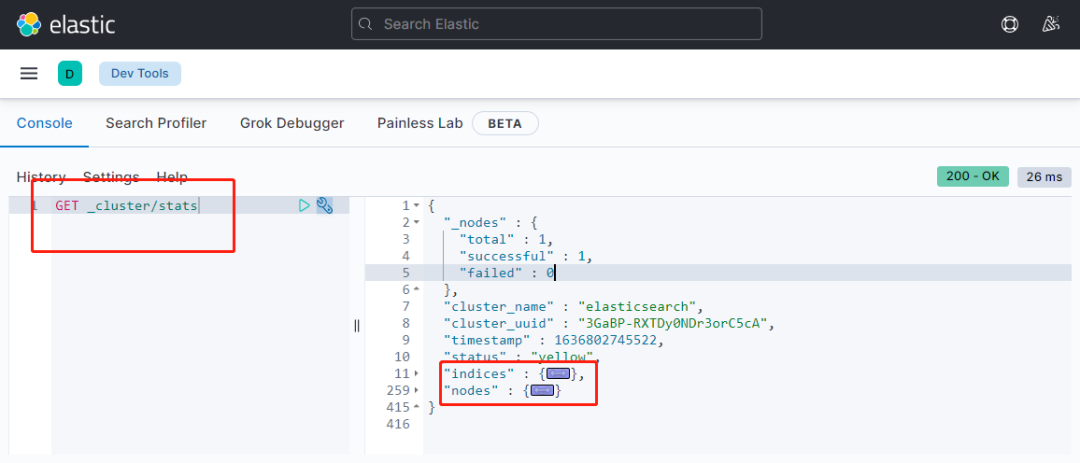
图示:stats命令执行示意图
4)state监控分析
借助 task 监控分析,发现有大量的state指令,接着在服务端执行一次,发现了问题点,执行一次时间很长,且响应返回的内容超过70mb,这是问题,可以回答为什么之前的master节点流量如此之高。终于问题越来越清晰了,也越来越确定了。
图示:state命令执行示意图
5)transport-client应用访问
借助前面服务端现象分析,越来越确定问题出在客户端应用代码,大概率是操作不正确。
首先与客户交流,询问客户端应用代码访问ES的方式与程序版本,客户端开发团队很好配合,很快了解到应用客户端基于spring data elasticsearch框架,采用transport-client机制访问操作ES,但此时是不能定位是客户端造成的,也不能匆忙要求客户端提供源码。接下来很快在本地编写相应的测试程序源码。
Transport-client客户端绑定代码
@Configurationpublic class TransportClientConfig extends ElasticsearchConfigurationSupport {
@Bean public Client elasticsearchClient() throws UnknownHostException { Settings settings = Settings.builder().put("cluster.name", "elasticsearch").build(); TransportClient client = new PreBuiltTransportClient(settings); client.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); return client; }
@Bean(name = { "elasticsearchOperations", "elasticsearchTemplate" }) public ElasticsearchTemplate elasticsearchTemplate() throws UnknownHostException {
ElasticsearchTemplate template = new ElasticsearchTemplate(elasticsearchClient, elasticsearchConverter); template.setRefreshPolicy(refreshPolicy());
return template; }}
6)jmeter压测模拟
因为某些原因,我们只能提供间接性的服务方式,所以为了彻底解决上面的问题,需要在本地模拟测试,必须要模拟出生产的问题,才能要求客户端给出到源码。基于前面服务端与客户端应用了解到的信息,接下来就是要做压测,特别选择了jmeter工具,很快配置好本地集群,附加客户端应用访问代码。压测进行时,同步观察ES服务端threadpool与task,能够复现生产的问题,很快就得到了想要的结果。
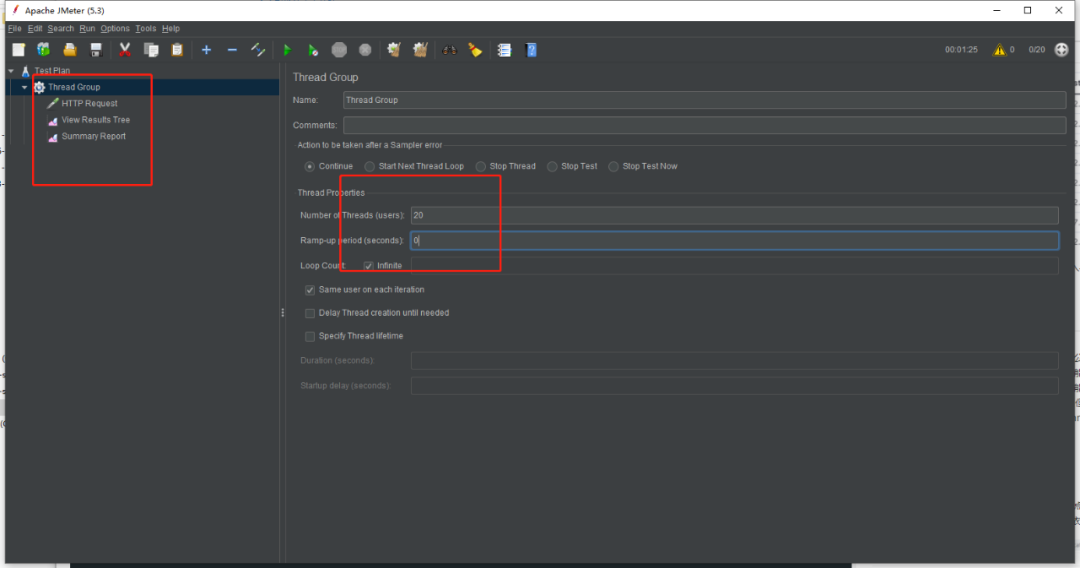
图示:jmeter压测示例,开启更多线程数,超过ES测试服务器线程数
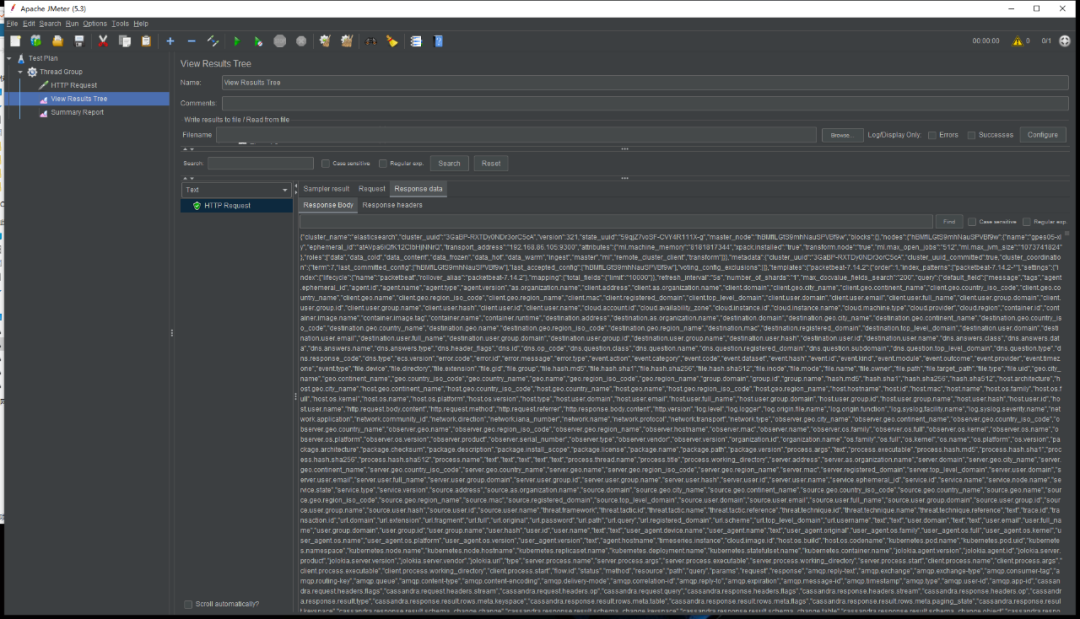
图示:jmeter压测示例,一次state命令执行需要消耗非常多的资源
既然在本地环境,借助jmeter压测出来生产上同样的问题,那么最后一步就是与客户应用开发团队一起review代码,这一步非常快,很快就定位到 客户应用端代码在具体业务操作前,会调用Cluster State API,进行业务逻辑判断,判断索引是否存在,判断索引字段是否存在等。
最终问题定位到了,产生原因也知道了,事情也算告一段落。
public Map<String, Object> getMappingByField(String indexName, String type) throws IOException { ImmutableOpenMap<String, MappingMetaData> mappings = getClient().admin().cluster().prepareState().execute() .actionGet().getState().getMetaData().getIndices().get(indexName).getMappings(); if(mappings.isEmpty()) { return null; } Map<String, Object> mapping = mappings.get(type).getSourceAsMap(); Map<String, Object> properties = (Map<String, Object
>) mapping.get(ES_PROPERTIES); return properties; }
服务端分析,寻找突破口
客户端分析,缩小排查范围
模拟测试,复现生产问题,确定问题产生原因
应用端代码分析,找出问题代码
修改观察,确认问题已经解决
经验总结,复查所有其它相关代码
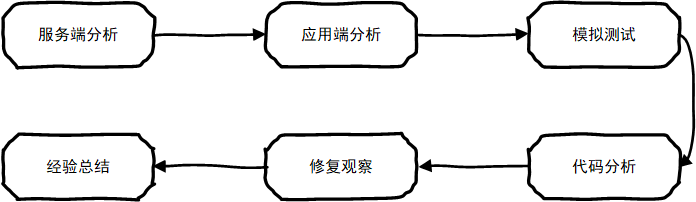
图示:问题排查过程与流程
本次ES问题排查涉及到的知识点以及技术性原理特别多,这里也来特别说明一下与此关联的架构原理,供大家日后参考与分析。
ES对外虽然宣称是个分布式架构,可以横向扩展,但那说的是数据节点或者其它非管理节点。实际上ES是典型主从架构模式,一个集群只有一个Active Master节点,Master节点负责管理集群所有元数据信息,其中包括节点信息、索引信息、分片信息、节点与索引路由信息、节点与分片路由信息等,集群执行一次管理型的命令都需要先在Master执行,然后分发到其它节点等。
了解这一点非常重要,可以很好的解释,为什么在本次ES故障中,Master的网络流量刚好等于其余节点网络流量之和。客户端应用发起一次State统计,首先都是Master节点接受指令,接着分发给其它节点执行State统计,最终汇总到Master节点,造成了Master节点网络流量奇高,超过网卡极限,ES集群响应慢,但实际CPU与内存消耗又不高。
联想到这里,集群架构是不是可以想象型的大胆设计一下,现在的ES集群只有一个大当家,随着集群规模越来越大,大当家压力越来越大,大当家如果出现故障,就重新选大当家,这听起来好像不符合社会组织学。那能否下次修改一下,设计一个有大当家与二当家的模式,大当家与二大家职责再分离一下,大当家太忙,二当家分担一些。
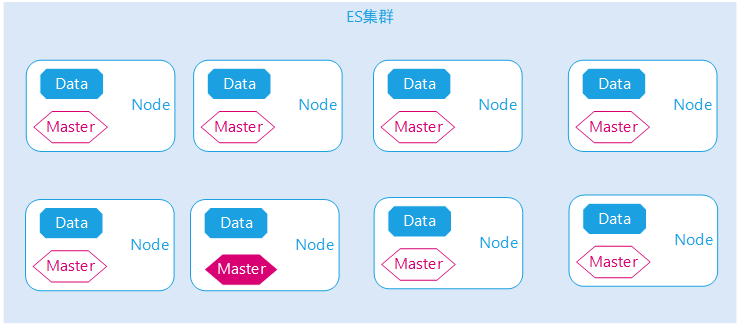
图示:ES主从架构分布式示意图,一个集群只有一个Active Master节点
ES是个数据库产品,内部设计了多个任务线程池,不同的线程池任务与职责不一;线程池也分为多种类型,不同的线程池类型应对任务场景不一样;ES不同版本,线程池数量与类型会有大的差异,尤其是5.x与7.x版本,这种跨大版本,差异相当大。
由于在某机构做ES老师,时常与Java学员交流,发现了一些严重的认知误区:1.很多学员认为Java不能开发数据库产品,因为GC机制;2.多数人学习掌握的Java线程池都只用来做简单的多线程业务场景,从未想象过,类似ES这样集成了几十个线程池的玩法。所以必须承认,ES是一个非常好的Java开发高手学习参考的产品,特别是做后端开发,想要更加深入进阶的同学。
了解ES线程池内部设计非常重要,可以很好的解释,为什么本次ES故障中,只有Active Master节点的 management 线程池特别繁忙,其余线程池总体很闲,其余节点的线程池也非常闲。客户端应用发起一次State统计,首先接收任务的是Master节点的management线程池,此线程池类型为 scaling,且最大的线程数是一个固定值,不超过实际CPU合数,也不能超过固定值5,而不是根据节点CPU核数来自动弹性设计的。
当客户端应用采用多线程执行模式,且每次执行业务操作前,都先执行一次State 统计做业务逻辑判断,这就无形中增加了集群的负载,增加了Master节点的任务数量,客户端应用实例数量越多,并发线程数也越多,集群Master节点就几乎无法消化,毕竟Master节点就一个;也正是由于负责执行State任务的线程池是个固定值,Master节点CPU也不会打满,这就阻塞了所有的业务操作。
有时候官方文档并没有列出来,需要通过ES源码去查看,这点我至今也没有想明白,不光是过去历史版本,包括当前最新版本也是一样的,如当前 7.15.x,有的线程池就没有在官方文档列出来,但能在集群监控中查看到。
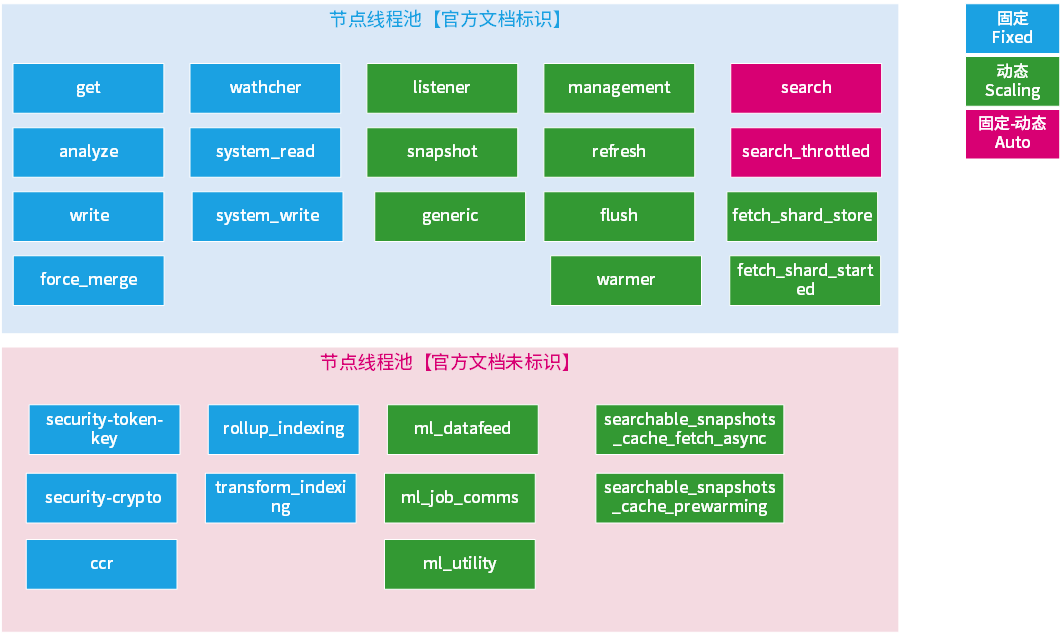
图示:ES内部线程池划分,(版本7.13.x,来自某机构ESVIP课程)
public class ThreadPool implements ReportingService<ThreadPoolInfo>, Scheduler { public ThreadPool(final Settings settings, final ExecutorBuilder>... customBuilders) { builders.put(Names.MANAGEMENT, new ScalingExecutorBuilder(Names.MANAGEMENT, 1, boundedBy(allocatedProcessors, 1, 5), TimeValue.timeValueMinutes(5)));、 }}
Cluster State Api 执行一次指令,指令会传输给Active Master节点,Active Master分发指令给各个节点,各个节点收集好信息之后回传给Master,然后由 Master响应给客户端。
在开始排查问题中,初次判断失误,以为是客户端在做大量的业务数据查询任务,所有节点数据量都很高,其中大量依赖Master节点对外输出,实际不是。
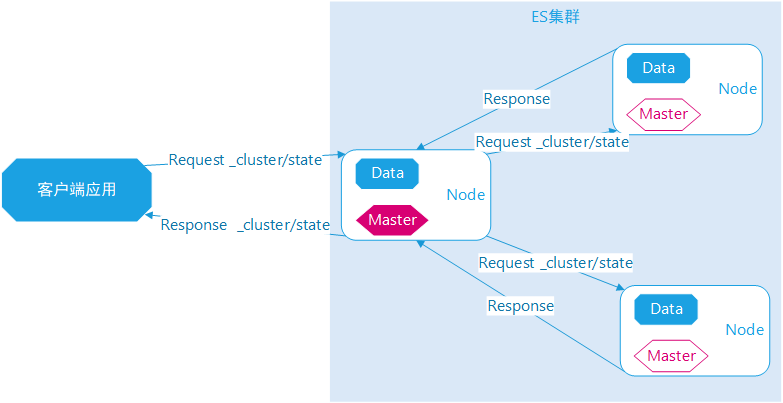
图示:Cluster State Api执行过程示意图
ES是典型的Free Schema数据产品,索引是可以动态创建的,索引的字段也是可以动态创建的,无需优先声明,更无需在应用代码中逻辑判断是否存在,是否需要创建,这是ES非常好的动态扩展能力之一,基于此给应用开发带来了相当多的便利,比如著名的“大宽表模式”查询场景,解决了海量数据关联实时查询的问题。
ES可以提前创建索引,也可以不创建,写入第一条数据,即可动态创建索引,并同时创建索引自动的mapping索引内部结构。若第二条数据写入,增加了很多新的数据内容结构,则会自动更新当前索引的mapping,自动刷新mapping。若新增加的数据字段缺失,也不会出错。ES默认内部会根据字段进行推测其字段对应的类型。
PUT my-index-000001{}PUT my-index-000001/_doc/1{ "create_date": "2015/09/02"}PUT my
-index-000001/_doc/1{ "my_float": "1.0", "my_integer": "1" , "create_date": "2015/09/02"}
Transport client 是官方早期推出的应用接入访问机制,自Rest Api 推出之后,官方就竭力要求切换过来,其中缘由部分并没有特别说明。Transport是一种直连方式,直接连接到ES集群中,连接之后保持长连接,并且需要定时执行内部的一些stats命令,来检查集群监控状况,这个其实非常多余,在极端情况下也非常消耗集群资源。
ES集群内部通信或者执行其它指令,都是通过transport机制,即使是rest api执行,内部也是转换为transport机制来执行。
Rest 接入相比 Transport 更加解耦,也可以尽力避免恶意干扰 transport 通信,更多的此处不展开,后续会有另外的文章来写。

图示:transport-client与rest api连接示意图
此次从问题发现、问题定位、问题解决,花费了几天时间,有一些经验建议有必要特别说明一下。
监控体系是运维的眼睛,集群的各种运行信息,都需要借助强大的监控体系来保障,提供实时的分析等。本次案例中,客户公司监控体系相对来说比较传统落后,虽然有zabbix,但在一些新的分析问题方式上表现并不行,而且非常欠缺,如分析集群各个节点网络流量进出走向,包括服务端与客户端的关系,都是没有的。
选择一款全面性且非常有独立视角的监控产品非常重要,Elastic Stack 是新时代的产物,新事物可以帮助我们提升优化问题排查思维。
绝大多数数据库产品都提供了一些基本的安全策略与防护,可以通过设置一些安全用户群组与角色权限来限制避免此种问题。
比如传统的关系型数据库MySQL,可以通过给客户端应用分配更小的权限来限制。早期ES版本由于ES并未提供安全防护机制,很多应用团队都是直接使用,也没有做到基于用户群组的权限隔离。最新版本的ES提供了开源免费的基本安全策略,可以通过用户群组权限来避免客户端应用的无意识操作。
本次案例中,先从集群后端运行分析,到应用程序端源码分析,再到本地环境模拟测试,涉及到的技术点非常的宽泛,并不能从单一维度发现解决,也不能仅仅从ES知识层面排查解决;任何人都不能只从ES集群运行表象定位问题,很多问题爆发是属于末端,但引起的其实在另外一端,这就需要跨界的能力与思维,当然最重要的是构建自己的知识体系,有自己独立的解决问题排查思路,也得掌握必要的各种工具软件,不能仅仅局限在ES范围之内。
为了用好ES,我们需要掌握开发技能,熟练使用ES提供的开发特性,了解ES各种特性的边界,防止滥用。我们需要掌握ES集群架构基本的原理,基本的运行机制,避免认知上的误区,如ES是典型的主从架构分布式,并不是无中心的分布式。我们需要掌握常规的运维技能,从操作系统基础环境,到ES运行各种指标信息等。
随着业务需求与社会发展,我们更多的是需要全栈式的工程师,当然必须声明,不是要求一个工程师同时兼任多种工作,不是按照国内某些企业“压榨式的全栈”。而是特别强调工程师的专业水平,工程师可以依据工作岗位比较容易切换角色,不仅仅局限某一个固定职位。很多优秀的IT产品都不是本职工作的人做出来的,而是一些跨界的人士创作出来的。
本次案例中,看似集群的问题是服务端,但实际上是由于开发知识面局限造成的,最后解决也是在应用端修改代码解决,这是一个典型的跨界问题,由服务端逐步往前发现是应用端的问题。为了模拟生产环境问题,需要用压测工具,这貌似又属于测试职责,但为了解决问题,从后往前。为了确定线程池设置问题,下载ES对应版本源码,去查看阅读对应线程池的设置,因为官方文档没有。为了确定客户端应用代码问题,基于客户开发人员提供的信息,编写模拟客户端应用代码行为。
目前国内的大多数公司工程师都是单一职责职位与技能,尤其是注重前后端分离之后,前端与后端技能分裂的更严重了,前端很多薪资很高,涨幅快,看不起后端,后端也逐步远离前端应用,更加不关心前端运行方式;后端应用与大数据开发也是,将大数据开发与应用开发分离,导致工程师的专业素养下降很快,不少大数据工程师都不具备很好的编程能力,这是值得大家思考的问题。
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-state.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
elasticsearch transport client 参考文档
https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/index.html
spring data elasticsearch 参考文档
https://docs.spring.io/spring-data/elasticsearch/docs/4.2.6/reference/html/#reference
jmeter http request 参考文档
http://jmeter.apache.org/usermanual/component_reference.html#HTTP_Request
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn







