👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
来源丨量子位
时序数据,也就是时间序列的数据。
像股票价格、每日天气、体重变化这一类,都是时序数据,这类数据相当常见,也是所有数据科学家们的挑战。
所以,如果你有朝一日碰到了时序数据,该怎么用Python搞定它呢?
时序数据采样
数据集
这里用到的例子,是2011年11月到2014年2月期间伦敦家庭的用电量。
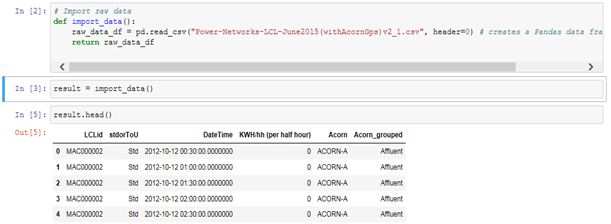
可以看出,这个数据集是按照每半小时统计一次的节奏,记下每家每户用了多少电。可以根据这些数据,生成一些图表分析。
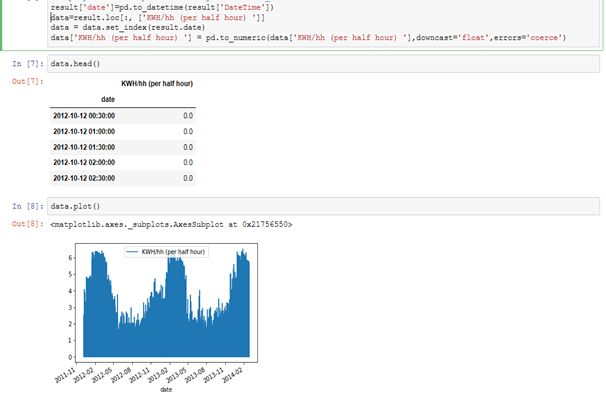
当然,因为我们考虑的数据主要是时间和用电量两个维度,所以可以把其他的维度删掉。
重采样
我们先从重采样开始。重采样意味着改变时序数据中的时间频率,在特征工程中这个技能非常有用,给监督学习模型补充一些结构。
依靠pandas进行重采样的方法类似groupby,通过下面的例子,可以更方便的理解。
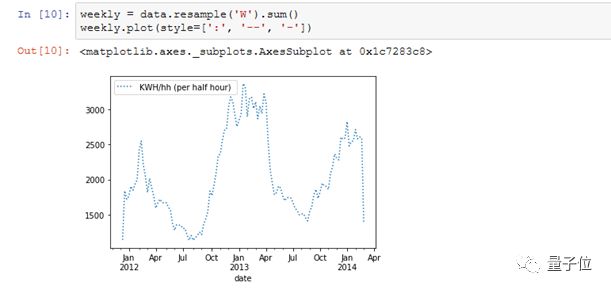
首先,需要把采样周期变成每周:
· data.resample() 用来重采样数据帧里的电量(kWh)那一列。
· The ‘W’ 表示我们要把采样周期变为每周(week)。
· sum()用来求得这段时间里的电量之和。
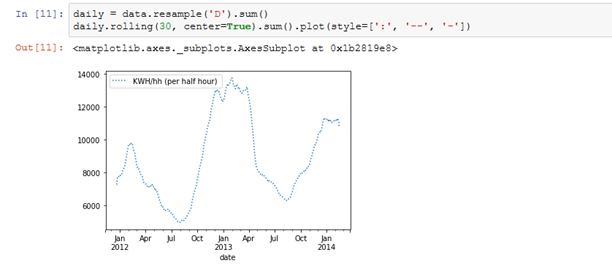
当然,我们也可以依葫芦画瓢把采样周期变成每天。
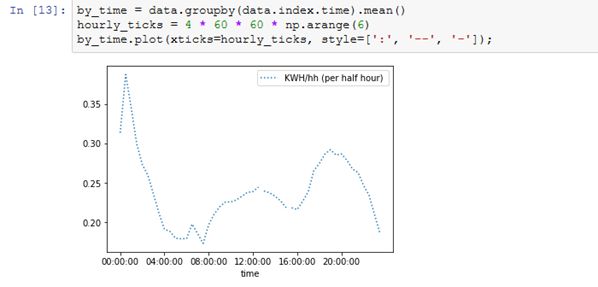
pandas里内置了很多重采样的选项,比如不同的时间段:
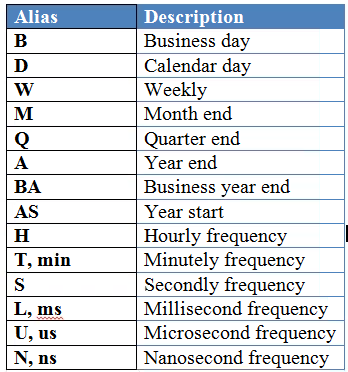
还有不同的采样方式:
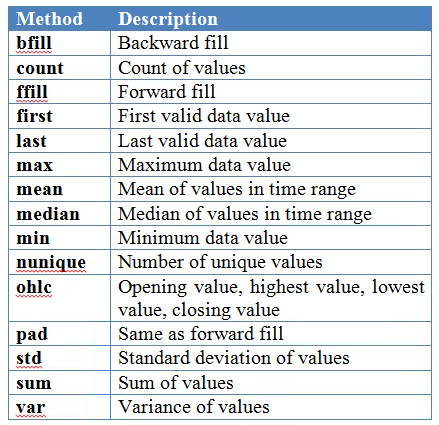
这些你可以直接用,也可以自己定义。
用Prophet建模

Facebook Prophet诞生于2017年,可以用Python和R语言操作。
Prophet天生就是分析时序数据的一把好手,适配任何时间尺度,还能很好的处理异常值和缺失数据,对趋势变化非常敏感,还考虑到了假期等特殊时间的影响,可以自定义变更点。
在使用Prophet之前,我们先重命名一下数据集中的每列。数据列为ds,我们要预测的值列为y。
下面的例子就是以每天为间隔的时序数列。

导入Prophet,创建模型,填充数据。
在Prophet里,changeprior prior scale这个参数可以控制对趋势变化的敏感程度,参数越高越敏感,设置为0.15比较合适

为了实现预测功能,我们创建未来数据帧,设置预测未来多少时间和频率,然后Prophet就可以开始预测了。
这里设置的是预测两周,以天为单位。

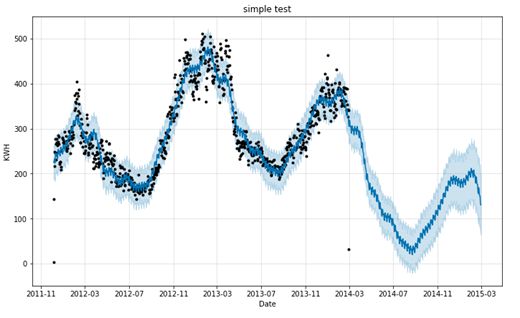
搞定了,可以预测未来两个月的家庭用电量了。
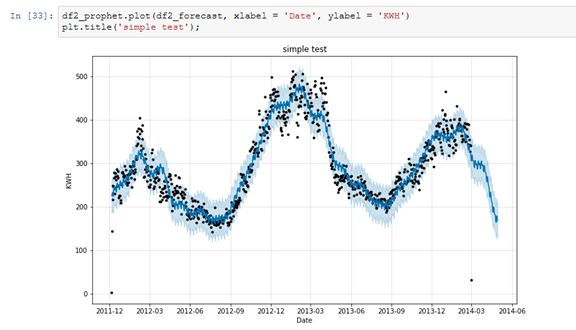
图中,黑点为实际值,蓝点为预测值,浅蓝色阴影区域表示不确定性。
当然,如果预测的时间很长,不确定性也会增大。
利用Prophet,我们还可以简单地看到可视化的趋势图。
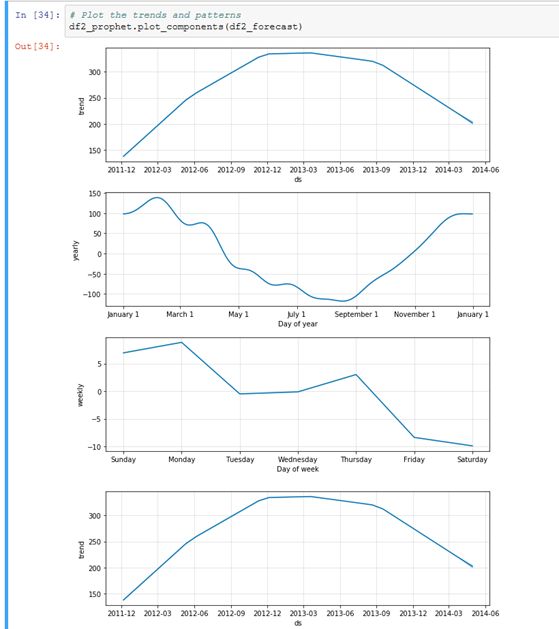
看上面第二张图,以年份为单位,可以明显看出秋冬家庭耗电量增大,春夏则减少;周日耗电量要比一周里的其他六天多。
LSTM预测
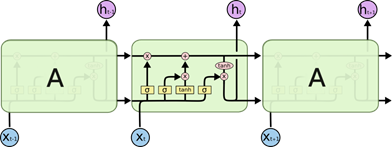
LSTM-RNN可以进行长序列观察,这是LSTM内部单元的架构图:
LSTM似乎很适合时序数据预测,让它来处理一下我们按照一天为周期的数据:
LSTM对输入数据的规模很敏感,特别是在使用sigmoid或tanh激活函数时。
你也可以把数据标准化,也就是将数据重新调整到[0,1]或[-1,1]的范围,可以使用scikit-learn库中的MinMaxScaler预处理类轻松地标准化数据集。

现在,把数据集分成训练集和测试集。
下面的代码把80%的数据分成训练集,剩下的20%留着当测试集。

定义一个函数来创建新的数据集,用这个函数来准备建模。
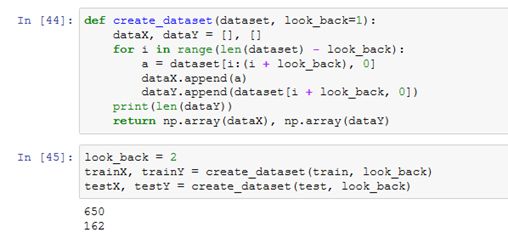
LSTM网络的输入数据需要设置成特定的阵列结构:[样本,时间步长,特征]。
现在用的是[样本,特征],我们需要加上时间步长,通过下面的方法把训练集和测试集变成我们想要的样子

搞定,现在设计调试LSTM网络。

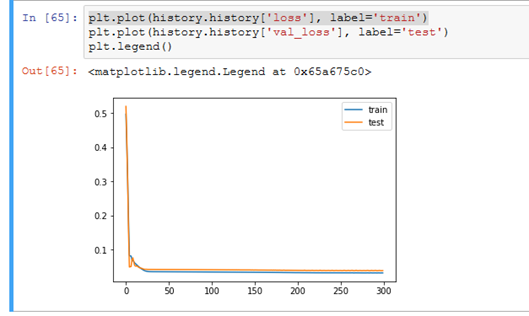
从损失图中,我们可以看到该模型在训练集和测试集上的表现相似。
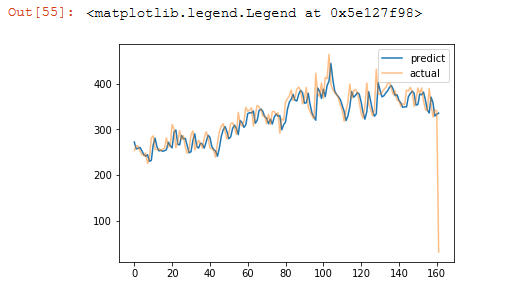
看下图,LSTM在拟合测试集的时候表现的非常好。
聚类
最后,我们还要用我们例子中的数据集进行聚类。
聚类的方法很多,其中一种是分层聚类(clusters hierarchically)。
分层的方法有两种:从顶部开始分,和从底部开始分。我们这里选择从底部开始。
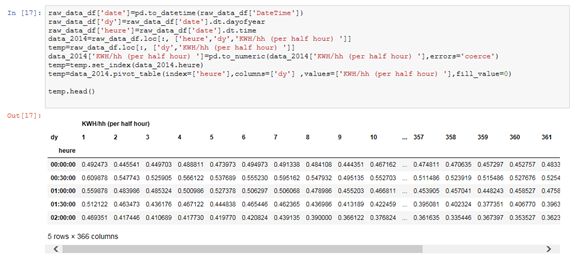
方法很简单,导入原始数据,然后为一年中的某一天和一天中的某一小时添加两列。
连接和树形图
连接函数将距离信息和分组对象根据相似性聚类,他们相互连接,创造更大的聚类。这个进程一直迭代,直到原始数据集中的所有对象都在分层树里相互连接在一起。
这样完成我们数据的聚类:

搞定,是不是很简单?
不过,代码里的ward是啥?
这是一种新的聚类方法,关键词ward让连接函数使用ward方差最小化算法。
现在,看一下聚类树形图:
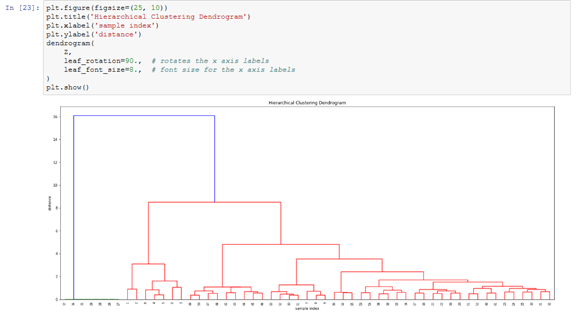
x轴上就是标签,或者说是样本索引;
y轴上是距离;
竖线是聚类合并;
横线表示哪些集群/标签是合并的一部分,形成新聚类;
竖线的长度是形成新聚类的距离。
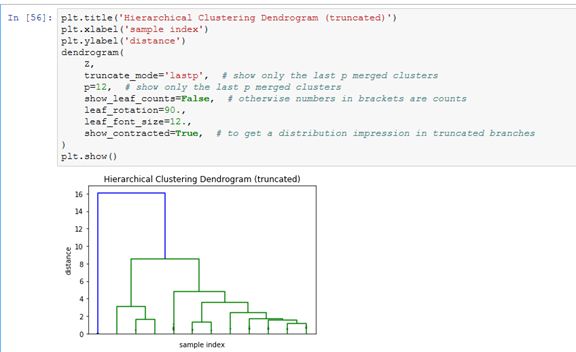
简化一下,更清楚:
传送门
https://towardsdatascience.com/playing-with-time-series-data-in-python-959e2485bff8








