什么是视觉深度估计?

视觉深度估计的目的就是估计图像中场景的深度,即场景中各点像素到相机成像平⾯的垂直距离,分为绝对距离和相对距离。我们看下面这个例子,左边是原图,右边是算法估计的对应深度图:

视觉深度估计的应用
最近⼏年,⾃动驾驶 、⼈机交互、虚拟现实、机器⼈等领域发展极为迅速,尤其是视觉⽅案在⾃动驾驶中取得惊艳的效果,在这些应⽤场景中,如何获取场景中的深度信息是关键且必须的。同时,从深度图中获得前后的关系更容易分辨出物体的边界,简化了CV中很多任务的算法,例如3D⽬标检测和分割、场景理解等。相⽐于激光雷达测距,相机价格低廉、体积小巧,操作简单等优点,目前视觉深度估计是三维视觉最重要的基础模块之一,不仅在学术届各大CV顶会上有很多深度估计相关新的论文,在工业界应用也非常广泛,是比较热门的研究⽅向。


视觉深度估计方法分类
单⽬深度估计
基于多视点的深度估计通常对同⼀场景采⽤摄像机阵列进⾏图像采集,并利⽤多视点图像之间
的冗余信息进⾏深度信息的计算,这类技术通常能够获得较为准确的深度信息。
从数学上讲,该问题是⼀个病态问题,其原因在于单幅RGB图像对应的真实场景可能有⽆数
个,而图像中没有稳定的线索来约束这些可能性。基于RGB图像与深度图之间存在着某种映射关系这⼀基本假设,研究者提出了诸多数据驱动的机器学习的 单⽬深度估计⽅法。

双⽬深度估计
流程:特征点匹配->极线矫正->视差计算->视差转深度
特征点匹配:

极线矫正:

视差计算:
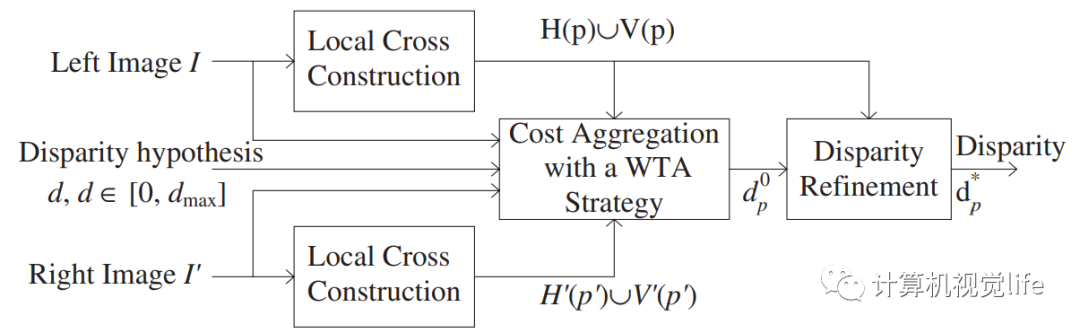
三⻆测量:
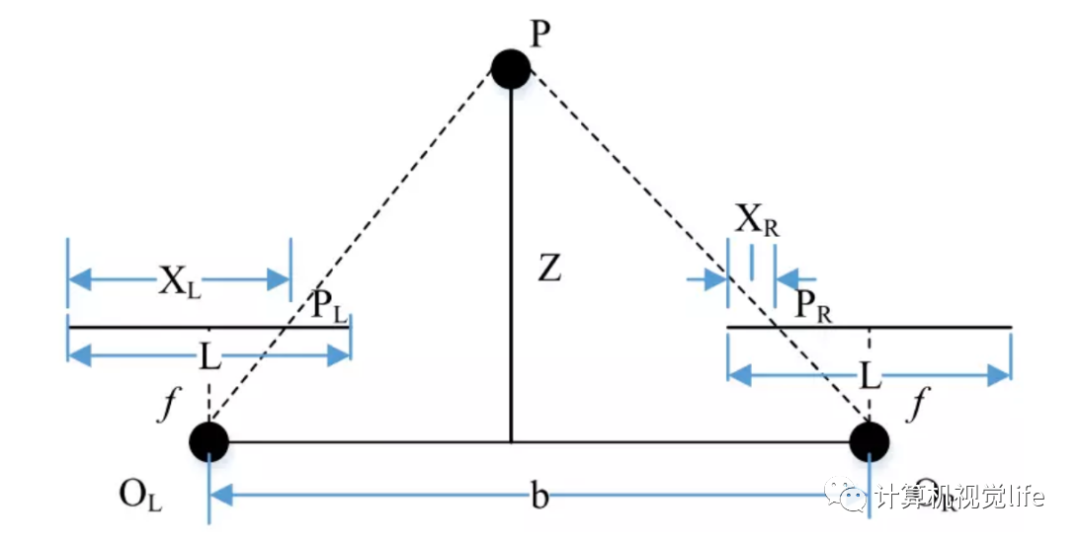
结果:

TOF
Time of Flight,通过连续发射光脉冲到被观测物体上,然后接收从物体反射回去的光脉冲,通过探测光脉冲的往返⻜⾏时间来计算被测物体离相机的距离。
TOF深度相机可以通过调节发射脉冲的频率改变相机测量距离,测量精度不会随着测量距离的
增⼤而降低,抗⼲扰能⼒也较强,在测量距离要求⽐较远的场合TOF深度相机具有⾮常明显的优
势,但也容易产⽣空洞区域。

结构光
通过主动投影多副相移图案来标记唯⼀位置,确定对应匹配点,利⽤三⻆关系计算距离。主动投射已知编码图案,有助于提升匹配效果,不收光照变化和物体表⾯纹理影响,测量精度⾼
但有效距离较近。

基于此,计算机视觉life推出了新课程《单双目视觉深度估计:从 理论到实战》,不仅讲述了基于传统CV的双目深度估计算法,也讲述目前最新的基于深度学习的单目深度估计算法。理论与实战并重,并且针对每章提供对应的作业和考试,并根据学习情况每月有机会获得100元学习基金,根据周作业、大作业、课程完成度等数据,评选最终的课程优秀学员,全额退还课程费用+发放优秀学员证书+至少1次内推机会!
现在前100名立减100元,扫描学习↓

课程学习大纲

招生及课程规划表:
为了保证课程学习质量,本期招生限200名学员,招满即止;
招生日期:2021/12/9-2022/2/18;课程进度一半即停止招生。
开课日期:2022/1/7
课程安排可参考学习规划表~

课程讲师及学员要求
课程讲师:
小马老师,硕士毕业于C9高校,现就职于CV独角兽企业,有3年以上工作经验。
课程适合人群:
适合人群:自动驾驶、三维视觉、SLAM等领域的高年级本科生、硕士、博士研究生等,有项目需求需要快速拥有实战经验的算法工程师
。希望能够快速上手并学以致用的从业者。自学能力差、需要有人督促带动一起学习的朋友。
课程使用C++和Python语言和Pytorch框架。
运行环境:Ubuntu 16.04/18.04/20.04 均可
硬件要求:普通台式机/笔记本电脑均可,无需GPU。课程使用公开数据集,不需要机器人、相机传感器等其他硬件








