开源最前线(ID:OpenSourceTop) 猿妹 整编
整理自:https://github.com/pwxcoo/chinese-xinhua
最近,清华大学在GitHub开源了一项神器叫万词王(Want Wrong),号称是首个支持中文及跨语言查询的开源在线反向词典。
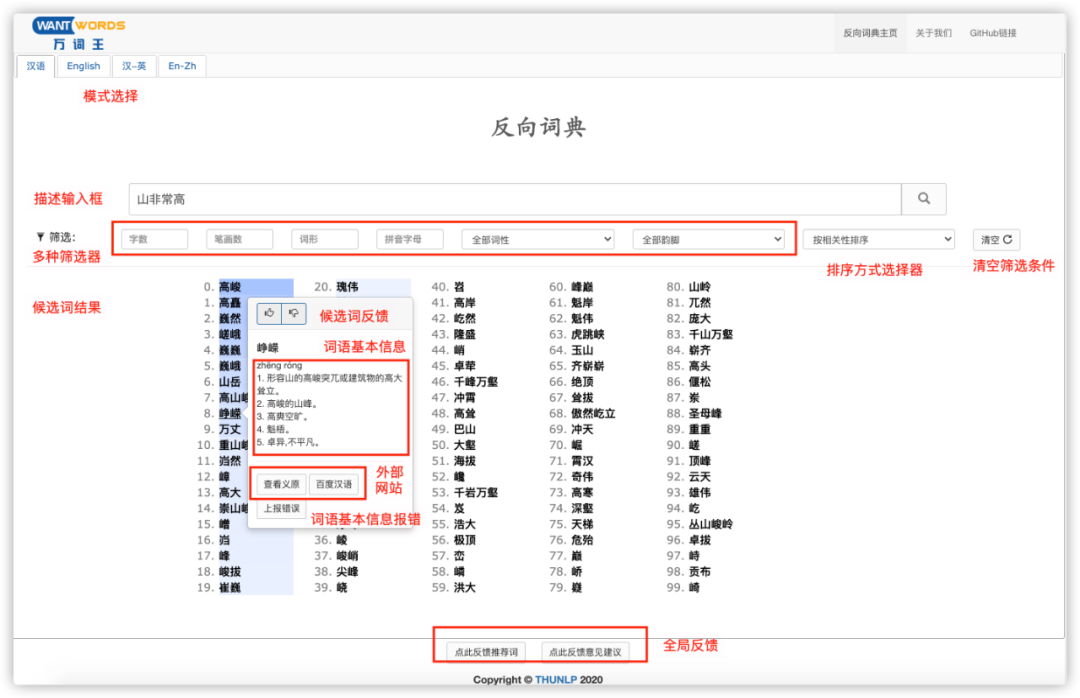
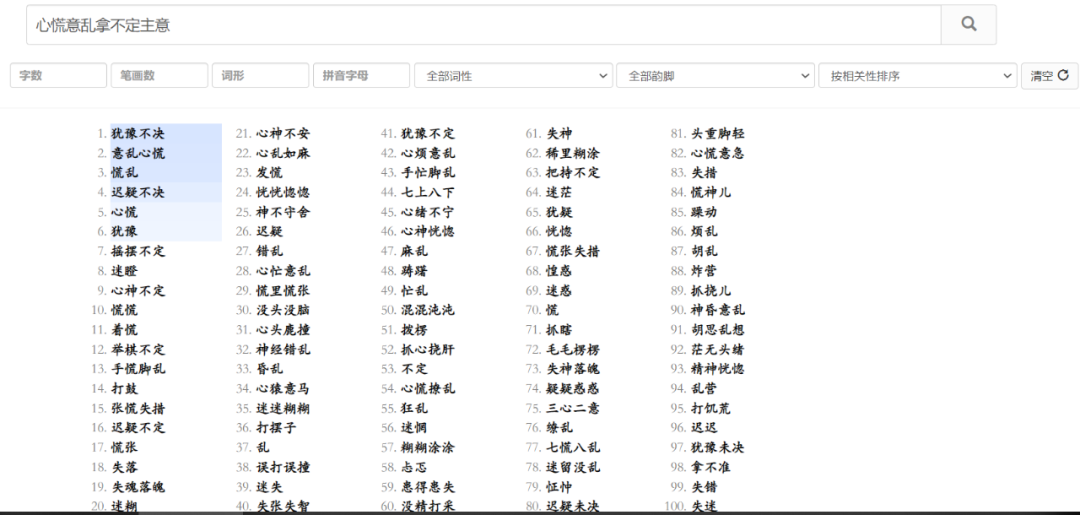
什么叫反向词典呢?普通的词典告诉你某个词语的定义,而反向词典恰好相反,可以告诉你哪些词语符合你输入描述的意思。下图为万词王在线反向词典的页面截图,其中演示了反向查词的一个示例,输入“山非常高”,系统将返回一系列模型认为表达“山非常高”意思的词语,例如“高峻”、“巍峨”等。简单来说,就是现在的年轻人都会有词穷的时候,当你词穷的时候,这个工具就可以派上用场了,比如你心慌意乱拿不定主意的时候,不知道用哪个词,你就可以将它输进去,就会得到犹豫不决、不意乱心慌等100个词语。而且词性和韵脚也是可以自定义选择。
除此之外,它还支持汉语、英语、汉英、英汉等多种不同转化方式。
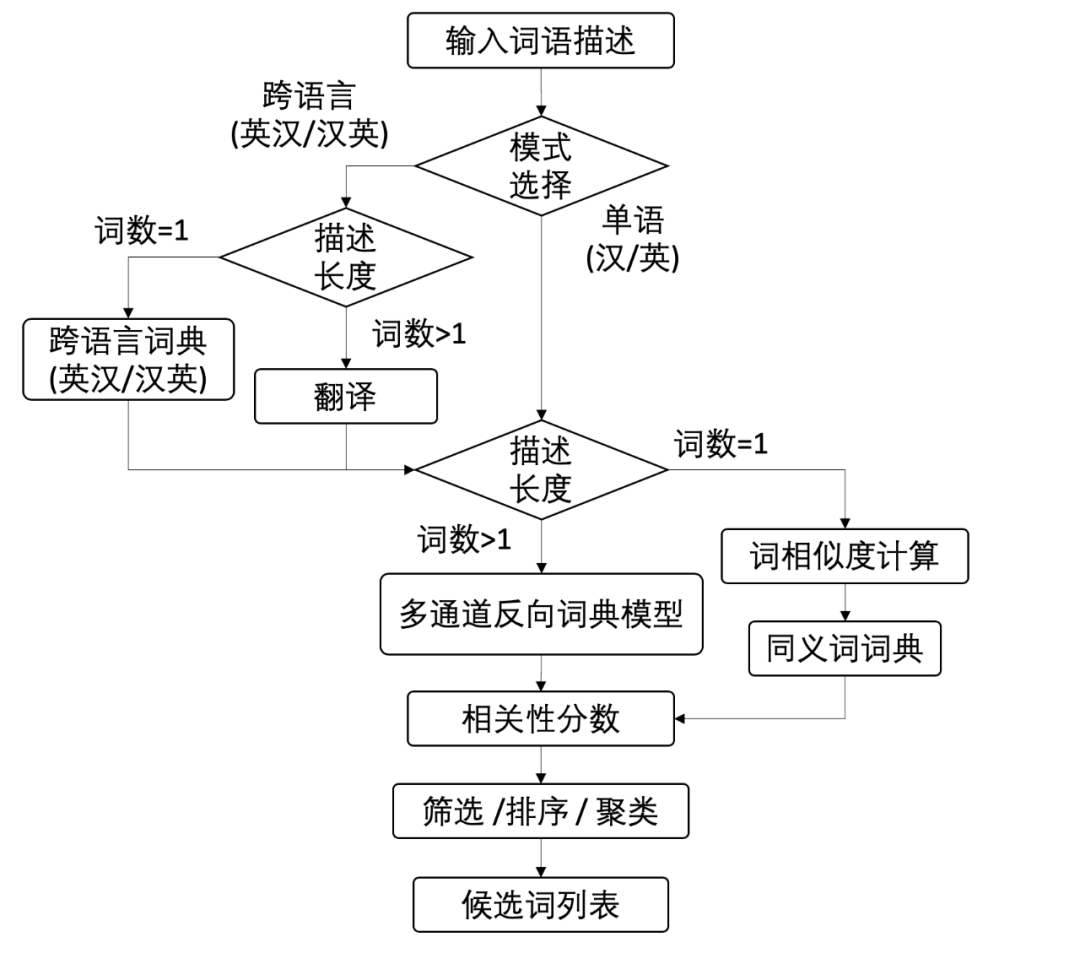
万词王的核心模型是之前清华大学计算机系自然语言处理实验室(THUNLP)发表在AAAI-20上的一篇论文提出的多通道反向词典模型:Multi-channel Reverse Dictionary Model [论文] [代码],其模型架构如下所示:
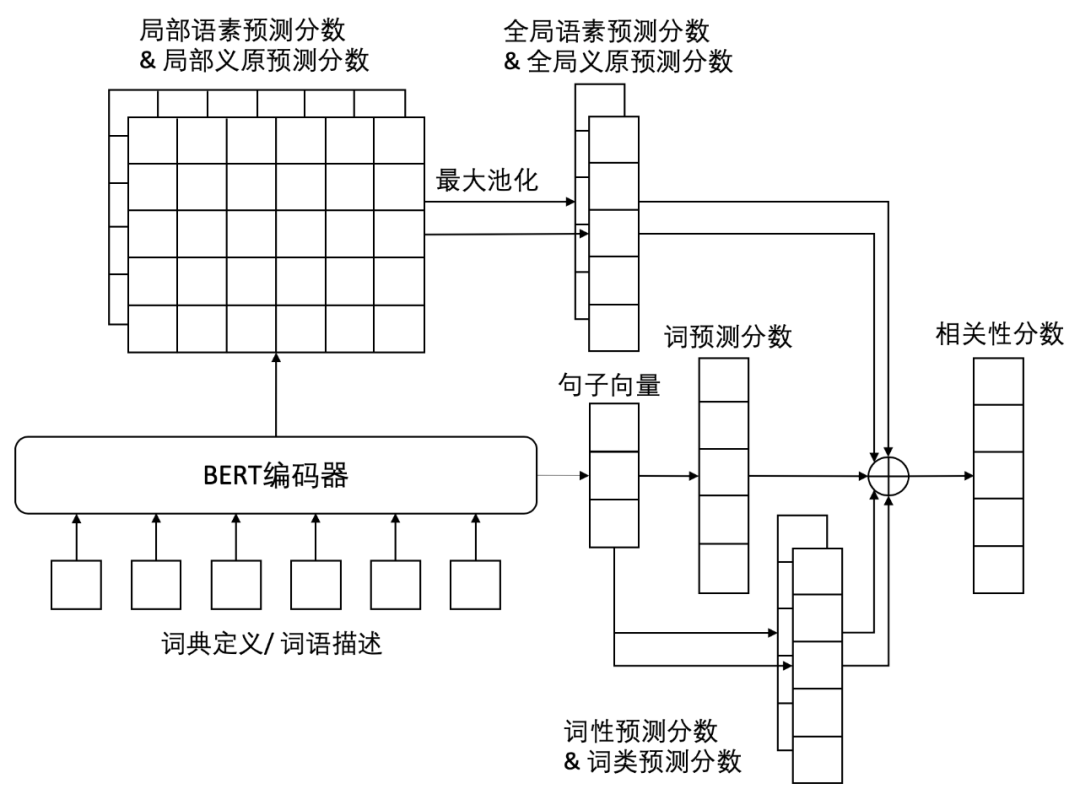
清华大学计算机系自然语言处理与社会人文计算实验室(THUNLP)成立于20世纪70年代末,最初在黄昌宁教授的带领下从事中文信息处理方面的研究工作,是国内开展自然语言处理研究最早、深具影响力的科研单位,同时也是中国中文信息学会(全国一级学会)计算语言学专业委员会的挂靠单位。实验室学术带头人为孙茂松教授,实验室教师队伍还包括刘洋教授和刘知远副教授。实验室面向以中文为核心的自然语言处理前沿基础课题开展系统深入的研究工作,研究领域涵盖计算语言学的核心问题以及社会计算和人文计算,近年来在973、863、国家自然科学基金等项目的支持下,实验室师生在IJCAI、AAAI、ACL、EMNLP等国际顶级会议和期刊上发表多篇高水平学术论文,与CMU、NUS、Google等国际名校和企业有长期良好的合作关系,培养的优秀毕业生大多到清华大学、谷歌、百度、阿里、微软等著名高校和企业工作。
WantWords由THUNLP开发和维护,项目指导教师为孙茂松教授和刘知远副教授,开发团队成员包括岂凡超,张磊,杨延辉。
目前,Wantwords已经在GitHub上标星 1K,累计分支 56 个(GitHub地址:https://github.com/thunlp/WantWords)社群福利:程序员技术交流群
这可能是你离头部大佬最近的一次,为提高群成员质量,表哥特意邀请了华为、腾讯、阿里的朋友进群,方便大家学习交流,一起进步。
有兴趣入群的同学,可长按扫描下方二维码,一定要备注:城市+昵称+技术方向,根据格式备注,可更快被通过且邀请进群

▲长按扫










