作为一家信息技术媒体公司,InfoWorld 成立于 1978 年,目前隶属于 IDG。
每年。InfoWorld 都会根据软件对开源界的贡献,以及在业界的影响力评选出当年的 “最佳开源软件” (BOSSIE),该奖项评选已经延续了十多年。
本次获奖的 29 个开源项目包括:软件开发、开发、云原生计算、机器学习等类型,下面我们一起来看看,有没有熟悉的面孔!
1、Svelte 和 SvelteKit
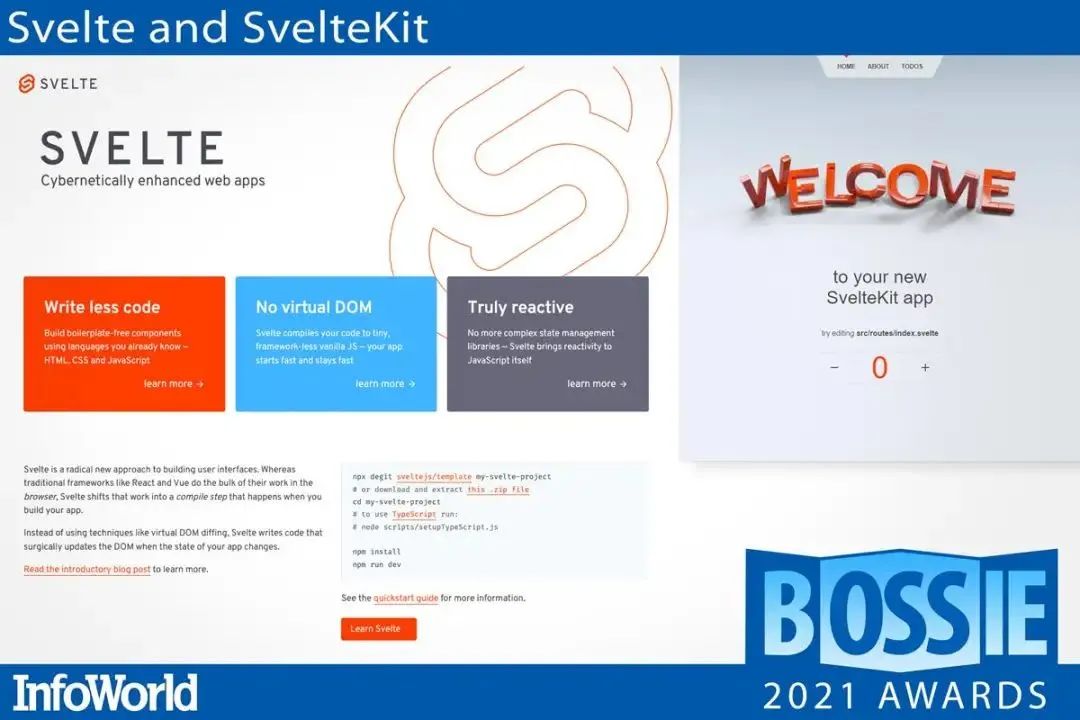
在众多创新的、开源的、前端的 JavaScript 框架中,Svelte 及其全栈对应的 SvelteKit 可能是最有野心和远见的。
Svelte 一开始就通过采用编译时策略来颠覆现状,并以出色的性能、持续的发展和卓越的开发者体验向前迈进。
SvelteKit 现已进入公测阶段,它延续了 Svelte 的传统,通过采用最新的工具,并将部署到无服务器环境作为一项内置功能来实现飞跃。
地址:https://github.com/sveltejs/svelte
2、Minikube
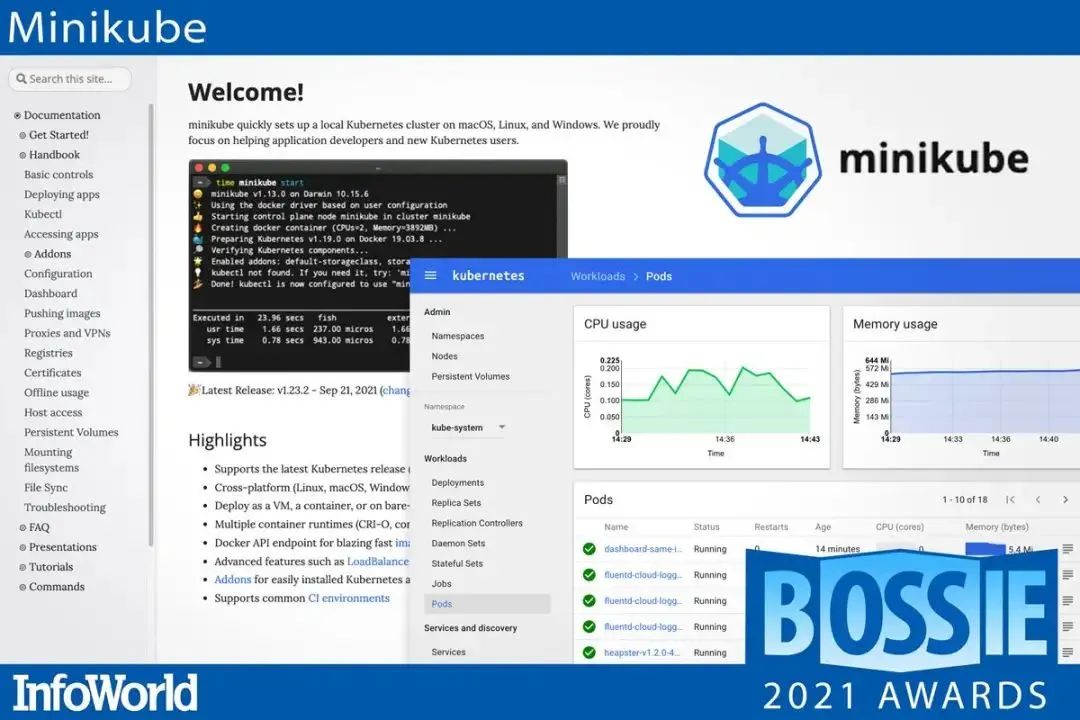
Minikube 是一个易于在本地运行 Kubernetes 的工具,可在你的笔记本电脑上的虚拟机内轻松创建单机版 Kubernetes 集群。便于尝试 Kubernetes 或使用 Kubernetes 日常开发。
地址:https://github.com/kubernetes/minikube
3、Pixie

Pixie 是 Kubernetes 应用的可观察性工具,它可以查看集群的高级状态,如服务地图、集群资源和应用流量;还可以深入到更详细的视图,如 pod 状态、火焰图和单个 full-body 应用请求。
Pixie 使用 eBPF 自动收集遥测数据,它在集群本地收集、存储和查询所有的遥测数据,使用不到 5% 的集群 CPU。Pixie 的用例包括集群内的网络监控、基础设施健康、服务性能和数据库查询剖析。
地址:https://github.com/pixie-io/pixie
4、FastAPI

FastAPI 是一个高性能 Web 框架,用于构建 API。主要特性:
快速:非常高的性能,与 NodeJS 和 Go 相当
快速编码:将功能开发速度提高约 200% 至 300%
更少的错误:减少约 40% 的人为错误
直观:强大的编辑器支持,自动补全无处不在,调试时间更少
简易:旨在易于使用和学习,减少阅读文档的时间。
简短:减少代码重复。
稳健:获取可用于生产环境的代码,具有自动交互式文档
基于标准:基于并完全兼容 API 的开放标准 OpenAPI 和 JSON Schema
地址:https://github.com/tiangolo/fastapi
5、Crystal
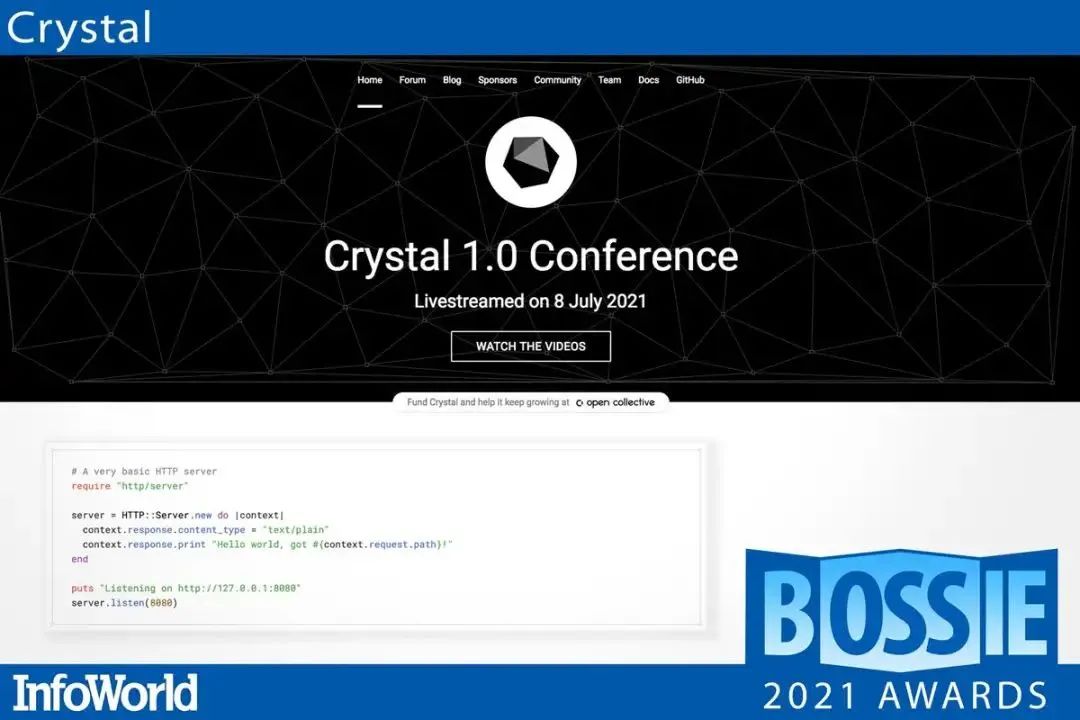
作为一个提供具有 C 语言的速度和 Ruby 语言的表现力的编程语言的项目,Crystal 已经开发了好几年了。随着今年年初 Crystal 1.0 的发布,该语言现在已经足够稳定到可以用于一般工作负载。
Crystal 使用静态类型和 LLVM 编译器来实现高速度,并避免在运行时出现空引用等常见问题。Crystal 可以与现有的 C 代码接口,以进一步提高速度和便利性,它还可以使用编译时宏来扩展基础语言的语法。
地址:https://github.com/crystal-lang/crystal
6、Windows Terminal
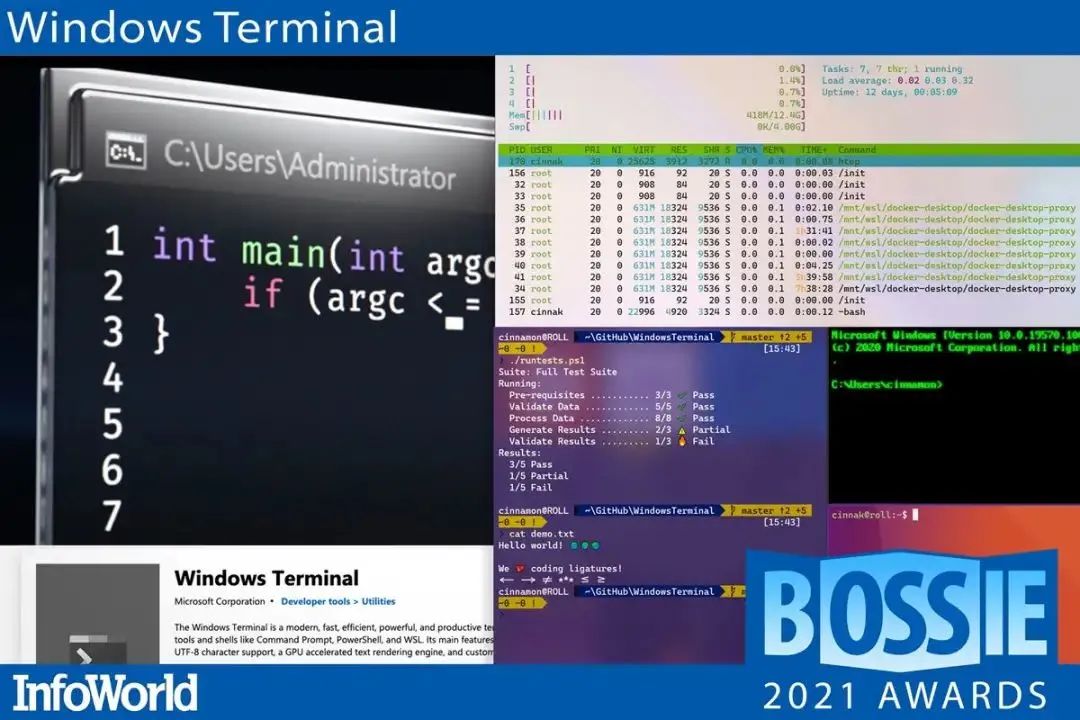
Windows Terminal 是一个全新的、流行的、功能强大的命令行终端工具。
包含很多来社区呼声很高的特性,例如:多 Tab 支持、富文本、多语言支持、可配置、主题和样式,支持 emoji 和基于 GPU 运算的文本渲染等等。同时该终端依然符合我们的目标和要求,以确保它保持快速、高效,并且不会消耗大量内存和电源。
地址:https://github.com/Microsoft/Terminal
7、OBS Studio
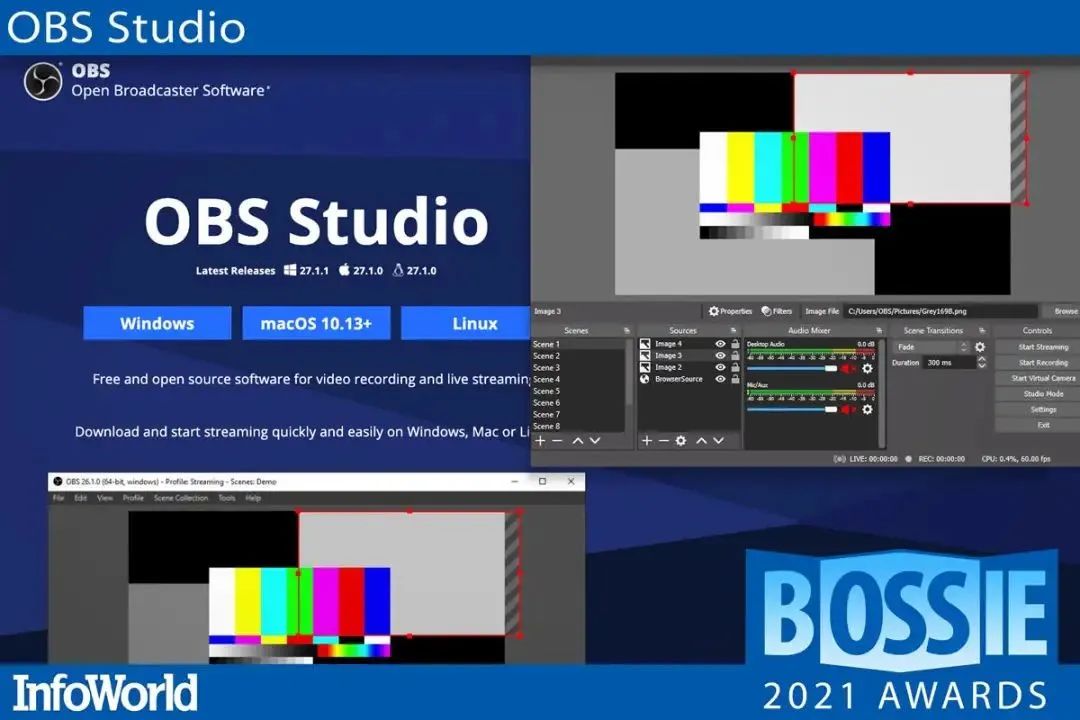
OBS Studio 是一款用于实时流媒体和屏幕录制的软件,为高效捕获,合成,编码,记录和流传输视频内容而设计,支持所有流媒体平台。关注公众号:程序员开源社区,回复:666领取资料 。
高性能实时视频 / 音频捕获和混合。创建由多种来源组成的场景,包括窗口捕获、图像、文本、浏览器窗口、网络摄像头、捕获卡等。
设置无限数量的场景,用户可以通过自定义过渡无缝切换。
带有每个源滤波器的直观音频混合器,例如噪声门,噪声抑制和增益。全面控制 VST 插件支持。
强大且易于使用的配置选项。添加新源,复制现有源,并轻松调整其属性。
精简的设置面板使用户可以访问各种配置选项,以调整广播或录制的各个方面。
模块化的 “Dock” UI 允许用户完全根据需要重新排列布局。用户甚至可以将每个单独的 Dock 弹出到自己的窗口中。
地址:https://github.com/obsproject/obs-studio
8、Shotcut
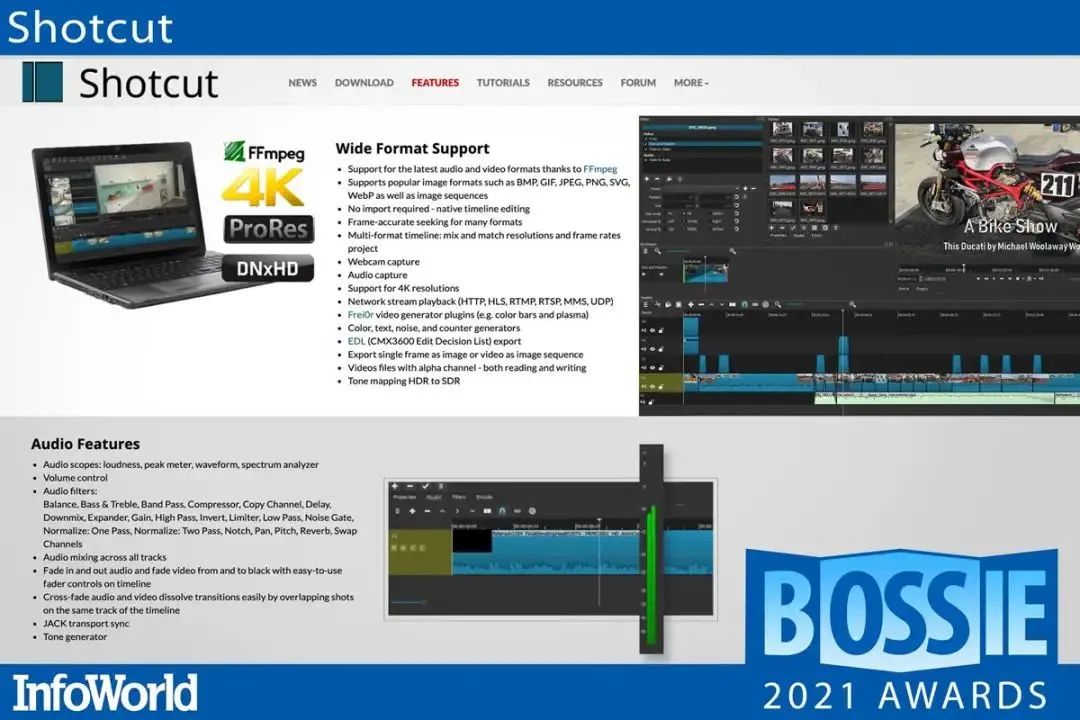
Shotcut 是一款跨平台的视频编辑工具,允许人们在应用效果和分层的同时,对音频和视频轨道进行所有的标准修正。Shotcut 有一个非常活跃的社区,并提供大量的操作视频和指导,以帮助新手和高级摄像师。
它可以在 Mac、Linux、BSD 和 Windows 上运行 -- 尽管是跨平台的,但与同类工具相比,它的界面很敏捷,使用起来也相对简单。
地址:https://github.com/mltframework/shotcut
9、Weave GitOps Core
Weave GitOps 支持有效的 GitOps 工作流,以将应用程序持续交付到 Kubernetes 集群中。它基于领先的 GitOps 引擎 CNCF Flux。
地址:https://github.com/weaveworks/weave-gitops
10、Apache Solr

Apache Solr 是基于 Lucene 的全文搜索服务器,也是最流行的企业级搜索引擎。Apache Lucene 是你所使用的大部分软件的搜索功能背后的基础搜索技术 -- 包括其他搜索引擎,如 Elasticsearch。
与 Elasticsearch 不同的是,Solr 放弃了它的开源许可,不过它仍然是免费的。Solr 是可集群的、可在云端部署的,并且强大到足以建立云端级的搜索服务。它甚至包括 LTR 算法,以帮助自动调整和加权结果。
地址:https://github.com/apache/solr
11、MLflow

MLflow 由 Databricks 创建,并由 Linux 基金会托管,是一个 MLOps 平台,可以让人跟踪、管理和维护各种机器学习模型、实验及其部署。它为你提供了记录和查询实验(代码、数据、配置、结果)的工具,将数据科学代码打包成项目,并将这些项目链入工作流程。
地址:https://github.com/mlflow/mlflow
12、Orange

Orange 旨在使将数据挖掘 "富有成效且有趣"。Orange 允许用户创建一个数据分析工作流程,执行各种机器学习和分析功能以及可视化。
与 R Studio 和 Jupyter 等程序化或文本工具相比,Orange 是非常直观的。你可以将小部件拖到画布上以加载文件,用模型分析数据并将结果可视化。
地址:https://github.com/biolab/orange3
13、Flutter

Flutter 由 Google 的工程师团队打造,用于创建高性能、跨平台的移动应用。Flutter 针对当下以及未来的移动设备进行优化,专注于 Android and iOS 低延迟的输入和高帧率。
它可以给开发者提供简单、高效的方式来构建和部署跨平台、高性能移动应用;给用户提供漂亮、快速、jitter-free 的 app 体验。
地址:https://github.com/flutter
14、Apache Superset
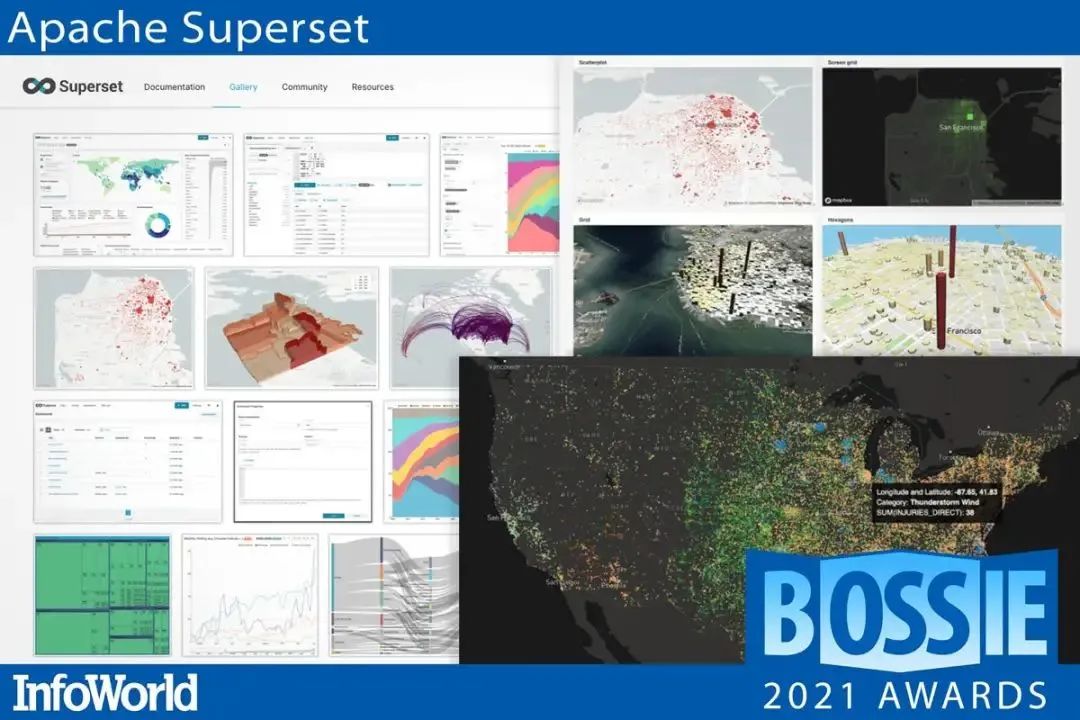
Apache Superset 是 Airbnb (知名在线房屋短租公司)开源的数据探查与可视化平台(曾用名 Panoramix、Caravel ),该工具在可视化、易用性和交互性上非常有特色,用户可以轻松对数据进行可视化分析。Apache Superset 也是一款企业级商业智能 Web 应用程序。
地址:https://github.com/apache/superset
15、Presto

Presto 是一个开源的分布式 SQL 引擎,用于在线分析处理,在集群中运行。
Presto 可以查询各种各样的数据源,从文件到数据库,并将结果返回到许多商业智能和分析环境。更重要的是,Presto 允许查询数据所在的地方,包括 Hive、Cassandra、关系型数据库和专有数据存储。
一个 Presto 查询可以结合多个来源的数据。Facebook 使用 Presto 对几个内部数据存储进行互动查询,包括他们的 300PB 数据仓库。
地址:https://github.com/prestodb/presto
16、Apache Arrow

Apache Arrow 为平面和分层数据定义了一种独立于语言的柱状内存格式,为现代 CPU 和 GPU 上的高效分析操作而组织。
Arrow 内存格式还支持零拷贝读取,以便在没有序列化开销的情况下进行闪电式的数据访问。Arrow 库可用于 C、C++、C#、Go、Java、JavaScript、Julia、MATLAB、Python、R、Ruby 和 Rust。
地址:https://github.com/apache/arrow
17、InterpretML
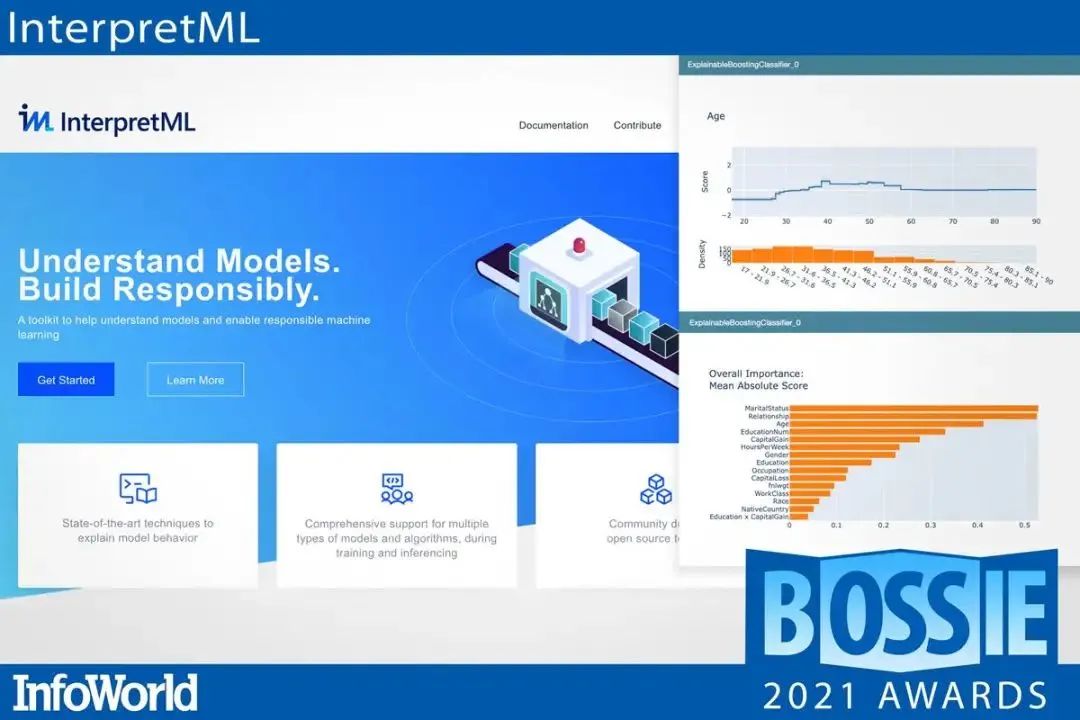
InterpretML 是一个开源的 Explainable AI(XAI)包,其中包含了几个最先进的机器学习可解释性技术。
InterpretML 让你训练可解释的 glassbox 模型并解释黑盒系统。InterpretML 可帮助你了解模型的全局行为,或了解个别预测背后的原因。
在它的许多功能中,InterpretML 有一个来自 Microsoft Research 的 "glass box" 模型,称为 Explainable Boosting Machine,它支持用黑盒模型的近似值进行 post-hoc 解释的 Lime。
地址:https://github.com/interpretml/interpret
18、Lime
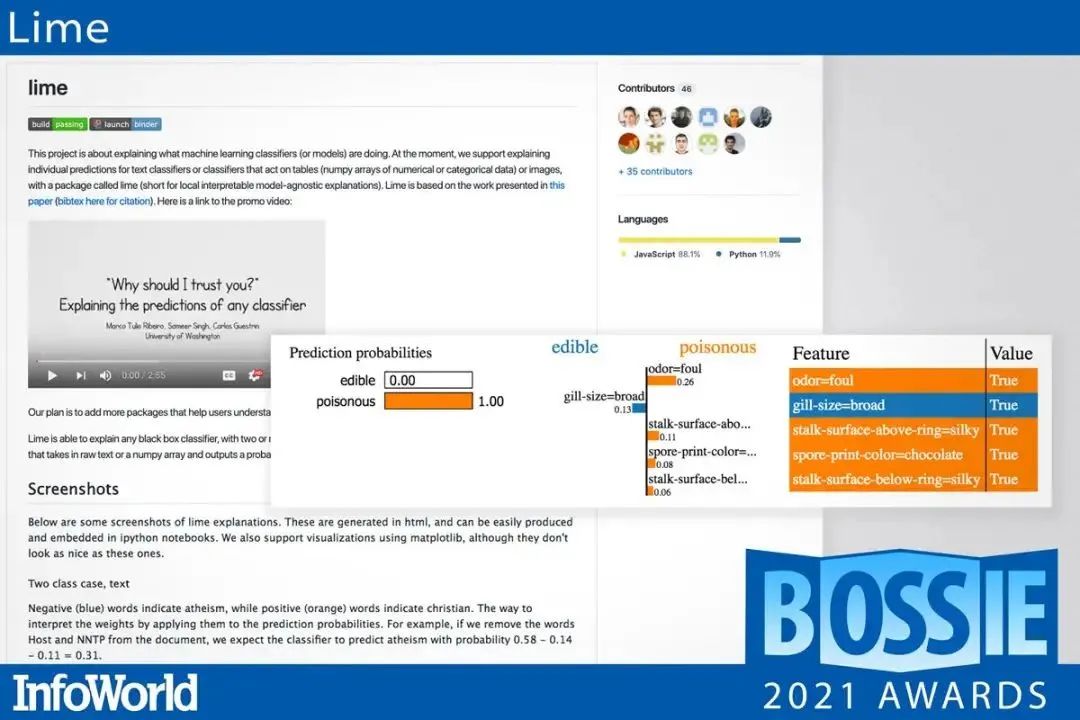
Lime(local interpretable model-agnostic explanations 的简称)是一种 post-hoc 技术,通过扰动输入的特征并检查预测结果来解释任何机器学习分类器的预测。
Lime 能够解释任何具有两个或更多类的黑盒分类器,其同时适用于文本和图像领域。Lime 也被包含在 InterpretML 中。
地址:https://github.com/marcotcr/lime
19、Dask

Dask 是一个用于并行计算的开源库,可以将 Python 包扩展到多台机器上。Dask 可以将数据和计算分布在多个 GPU 上,无论是在同一个系统中还是在一个多节点集群中。
Dask 与 Rapids cuDF、XGBoost 和 Rapids cuML 集成,用于 GPU 加速的数据分析和机器学习。它还与 NumPy、Pandas 和 Scikit-learn 集成,以并行化其工作流程
地址:https://github.com/dask/dask
20、BlazingSQL
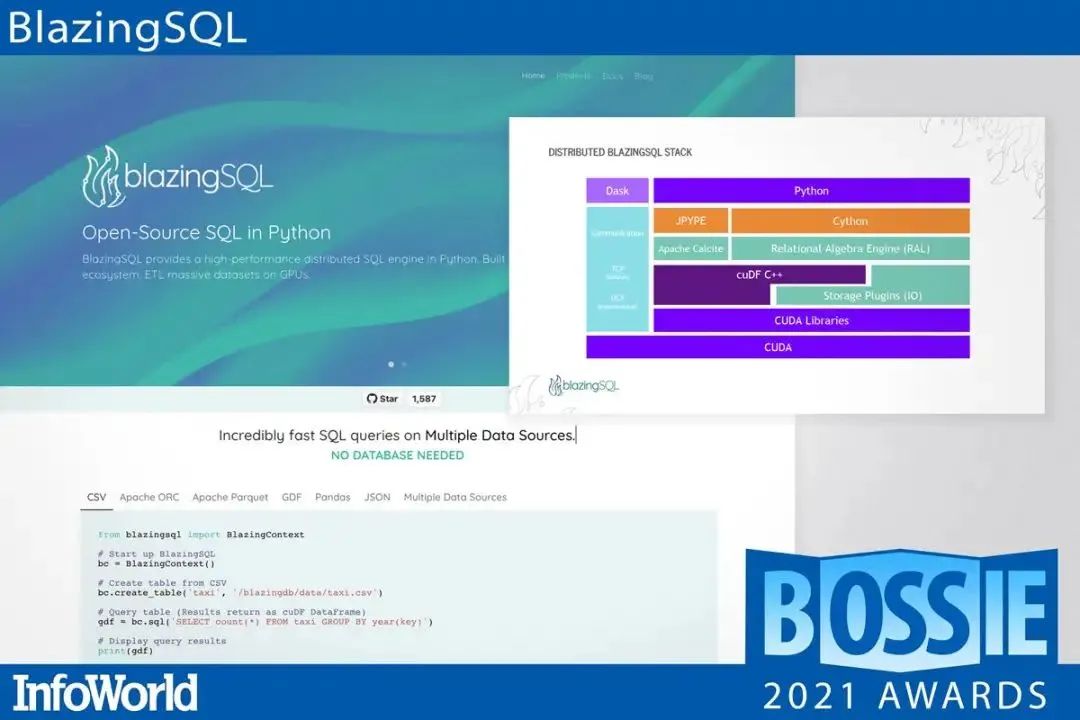
BlazingSQL 是一个基于 RAPIDS 生态系统构建的 GPU 加速 SQL 引擎。RAPIDS 基于 Apache Arrow 柱状内存格式,cuDF 是一个 GPU DataFrame 库,用于加载、连接、聚合、过滤和操作数据。它是 cuDF 的 SQL 接口,具有支持大规模数据科学工作流和企业数据集的各种功能。
地址:https://github.com/BlazingDB/blazingsql
21、Rapids
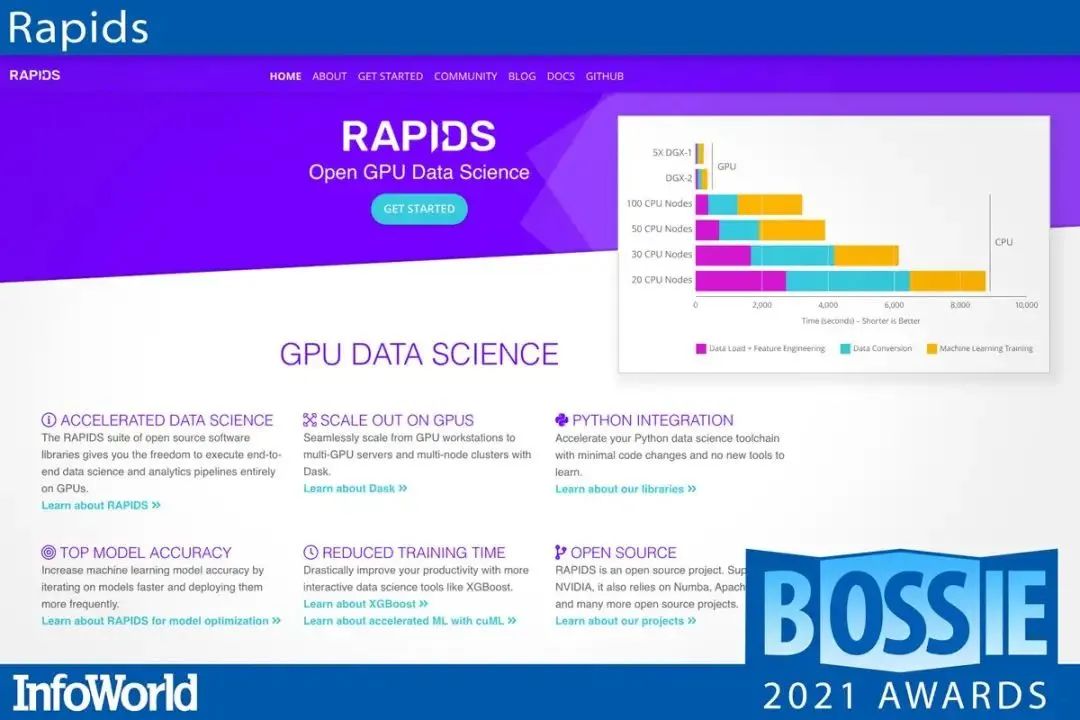
Nvidia 的 Rapids 开源软件库和 API 套件让你有能力完全在 GPU 上执行端到端的数据科学和分析管道。
Rapids 使用 Nvidia CUDA 基元进行底层计算优化,并通过用户友好的 Python 接口暴露了 GPU 的并行性和高带宽内存速度。Rapids 依赖于 Apache Arrow 柱状内存格式,包括 cuDF,一个类似 Pandas 的 DataFrame 库;cuML,一个机器学习库集合,提供 Scikit-learn 中大多数算法的 GPU 版本;以及 cuGraph,一个类似 NetworkX 的加速图分析库
地址:https://github.com/rapidsai/cudf
22、PostHog
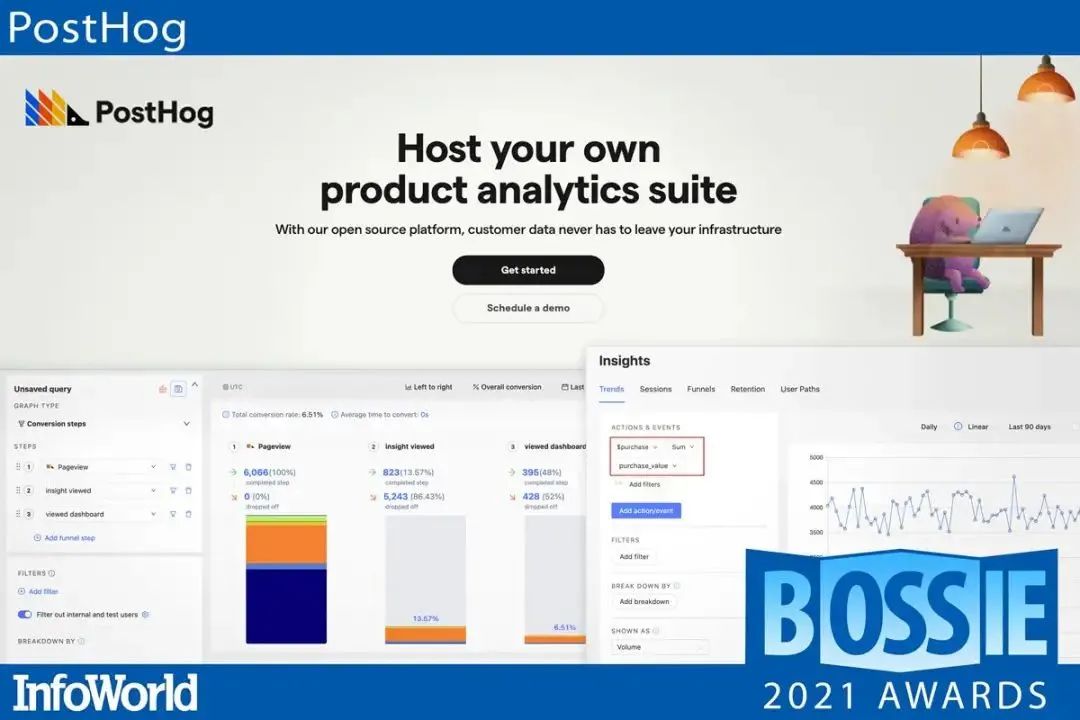
PostHog 是一个为开发人员构建的开源产品分析平台。自动收集你网站或应用程序上的每个事件,无需向第三方发送数据。它在用户级别提供基于事件的分析,捕获你产品的使用数据以查看哪些用户在你的应用程序中执行了哪些操作。它会自动捕获点击次数和综合浏览量,以分析你的用户在做什么,而无需手动推送事件。
地址:https://github.com/PostHog/posthog
23、LakeFS
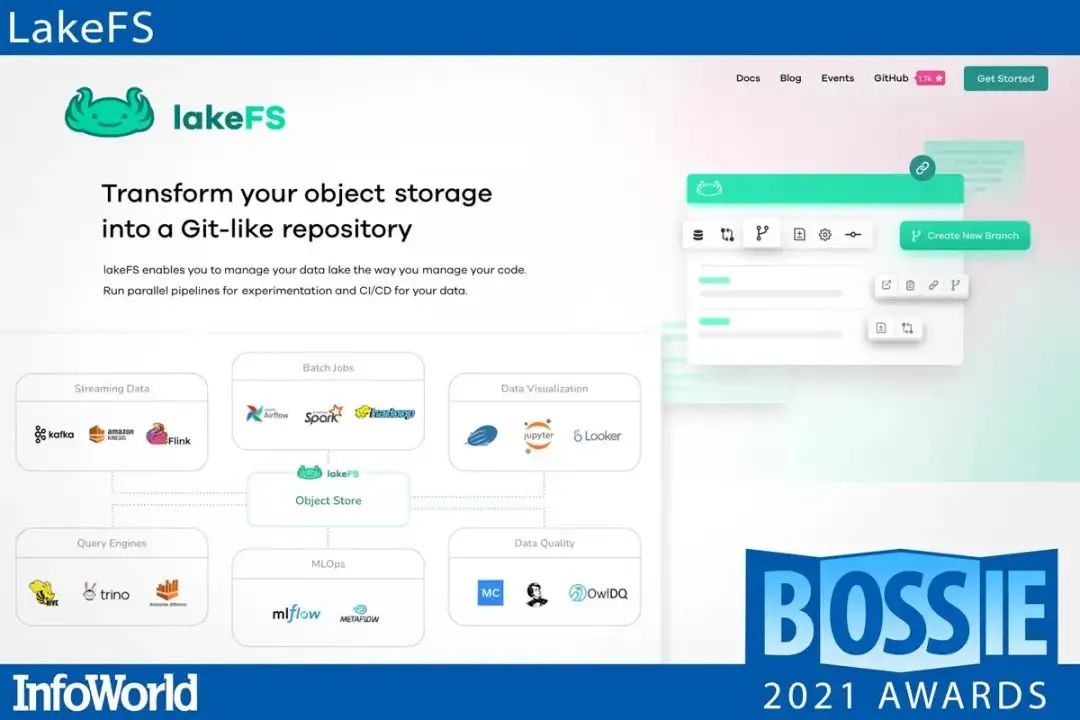
LakeFS 提供了一种 "以管理代码的方式管理你的数据湖" 的方法,为对象存储增加了一层类似于 Git 的版本控制。
这种对 Git 语义的应用让用户可以创建自己的隔离的、零拷贝的数据分支,在上面工作、实验和建模分析,而没有破坏共享对象的风险。LakeFS 为你的数据带来了有用的 commit notes、元数据字段和 rollback 选项,同时也带来了维护数据完整性和质量的验证 hooks-- 在一个未提交的分支被意外地合并回生产中之前,运行格式和模式检查。
通过 LakeFS,管理和保护代码库的熟悉技术可以扩展到现代数据库,如 Amazon S3 和 Azure Blob 存储。
地址:https://github.com/treeverse/lakeFS
24、Meltano

Meltano 是今年从 GitLab 中分离出来的,一个免费的开源 DataOps 替代传统 ELT(提取、加载、转换)的工具链。Meltano 的数据仓库框架使得为你的项目建模、提取和转换数据变得容易,并通过内置的分析工具和简化报告的仪表盘来补充集成和转换管道。
Meltano 提供了一个可靠的提取器和加载器库,以及对 Singer 标准的 data extracting taps 和 data loading targets 的支持,Meltano 已经是一个数据编排的动力源。
25、Trino

Trino(原名 PrestoSQL)是一个分布式 SQL 分析引擎,能够对大型分布式数据源运行极快的查询。
Trino 允许你同时对数据湖、关系型存储或多个不同来源执行查询,而不需要复制或移动数据进行处理。而且 Trino 与你的数据科学家可能使用的任何商业智能和分析工具配合得很好,无论是交互式的还是临时性的,最大限度地减少了学习曲线。
随着数据工程师努力支持越来越多的数据源的复杂分析,Trino 提供了一种优化查询执行和加速不同来源的结果的方法。
地址:https://github.com/trinodb/trino
26、StreamNative
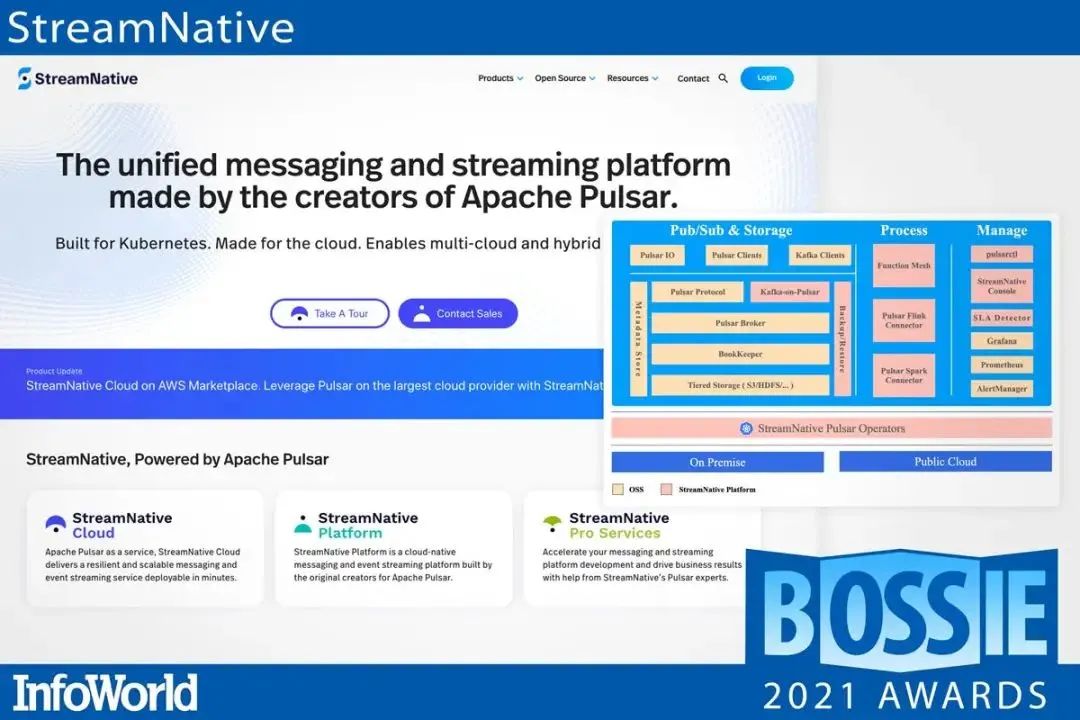
StreamNative 是一个高度可扩展的消息和事件流平台,大大简化了实时报告和分析工具以及企业应用流的数据管道铺设。
StreamNative 将 Apache Pulsar 强大的分布式流处理架构与 Kubernetes 和混合云支持等企业额外功能、大型数据连接器库、简易认证和授权以及用于健康和性能监控的专用工具相结合,既简化了基于 Pulsar 的实时应用程序的开发,又简化了大规模消息传递背板的部署和管理。
地址:https://github.com/streamnative
27、Hugging Face
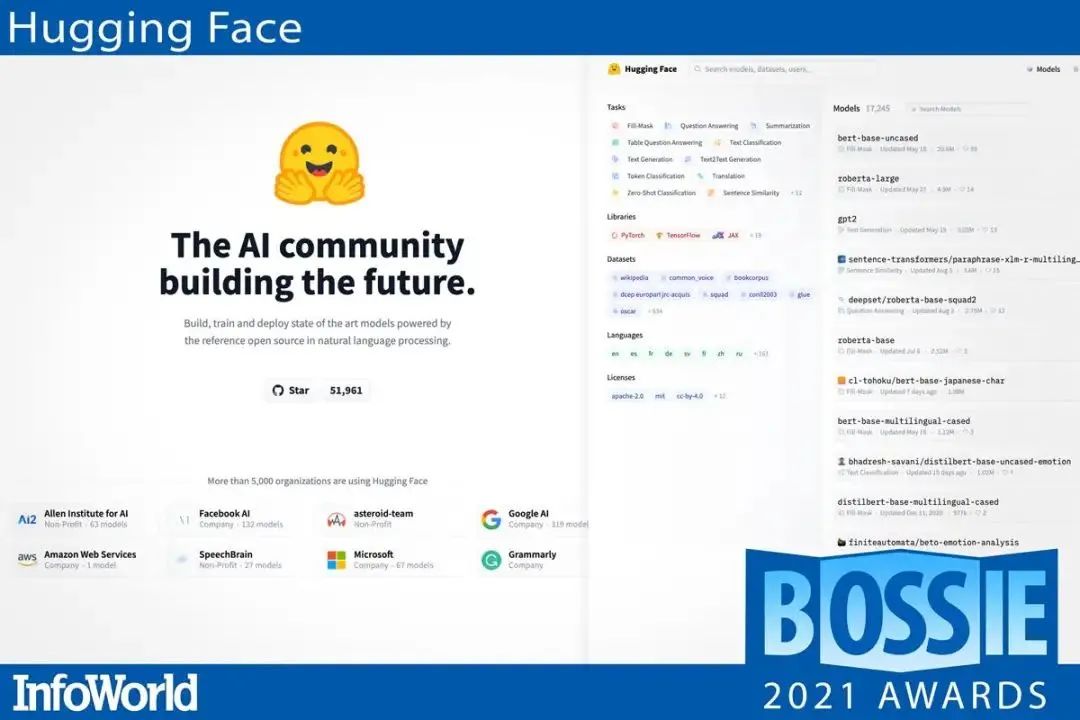
Hugging Face 提供了最重要的开源深度学习资源库,它本身并不是一个深度学习框架。Hugging Face 的目标是扩展到文本之外,支持图像、音频、视频、物体检测等。Infoworld 指出,深度学习从业者应在未来几年内密切关注这个 repo。
地址:https://github.com/huggingface/transformers
28、EleutherAI

EleutherAI 是一个由机器学习研究人员组成的分布式小组,旨在将 GPT-3 带给所有人。
2021 年伊始,EleutherAI 发布了 The Pile,是一个 825 GB 的用于训练的多样化文本数据集;并在 6 月公布了 GPT-J,一个 60 亿参数的模型,大致相当于 OpenAI 的 GPT-3 的 Curie variant。
随着 GPT-NeoX 的出现,EleutherAI 计划将参数一直提高到 1750 亿,以与目前最广泛的 GPT-3 模型竞争。
地址:https://github.com/EleutherAI/gpt-neo
29、Colab notebooks for generative art

首先是 OpenAI 的 CLIP(对比语言 - 图像预训练)模型,一个用于生成文本和图像矢量嵌入的多模态模型。虽然 CLIP 是完全开源的,但 OpenAI 的生成性神经网络 DALL-E 却不是。
为了填补这一空白,Ryan Murdoch 和 Katherine Crowson 开发了 Colab notebooks, CLIP 与其他开源模型(如 BigGAN 和 VQGAN)结合起来,制作 prompt-based 生成性艺术作品。
这些 notebooks 基于 MIT 许可,于过去几十年间在互联网上进行了广泛传播,被重新混合、改变、翻译,并被用来生成了惊人的艺术作品。
地址:https://github.com/openai/CLIP
如果你今年有看过一些比较酷炫或实用的开源项目,也欢迎在评论区分享。
重磅!
AI有道年度技术文章电子版PDF来啦!

扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
感谢你的分享,点赞,在看三连 







