一、为什么要集群
单台 Elasticsearch 服务器提供服务,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用,所以生产环境中,一般都是运行在指定服务器集群中。除了负载能力,单点服务器也存在其他问题:
配置服务器集群时,集群中节点数量没有限制,大于等于 2 个节点就可以看做是集群了。一般出于高性能及高可用方面来考虑集群中节点数量都是 3 个以上。
二、集群的概念
一个集群就是由一个或多个服务器节点组织在一起,共同持有整个的数据,并一起提供索引和搜索功能。
一个 Elasticsearch 集群有一个唯一的名字标识,这个名字默认就是”elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
三、(mac/windows)集群部署
注:本博客是mac系统的部署,但本人亲测windows依旧可以适用,mac和windows上唯一的区别在于windows的启动文件是bin/elasticsearch.bat
将ElasticSearch的解压文件复制三份,如下所示:

1.修改node-8001的config/elasticsearch.yml文件,如下
cluster.name: my-application
node.name: node-8001
node.master: true
node.data: true
network.host: localhost
http.port: 8001
transport.tcp.port: 9301
http.cors.enabled: true
http.cors.allow-origin: "*"
2.修改node-8002的config/elasticsearch.yml文件,如下
cluster.name: my-application
node.name: node-8002
node.master: true
node.data: true
network.host: localhost
http.port: 8002
transport.tcp.port:
9302
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
http.cors.enabled: true
http.cors.allow-origin: "*"
3.修改node-8003的config/elasticsearch.yml文件,如下
cluster.name: my-application
node.name: node-8003
node.master: true
node.data: true
network.host: localhost
http.port: 8003
transport.tcp.port: 9303
discovery.seed_hosts: ["localhost:9301","localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
http.cors.enabled: true
http.cors.allow-origin: "*"
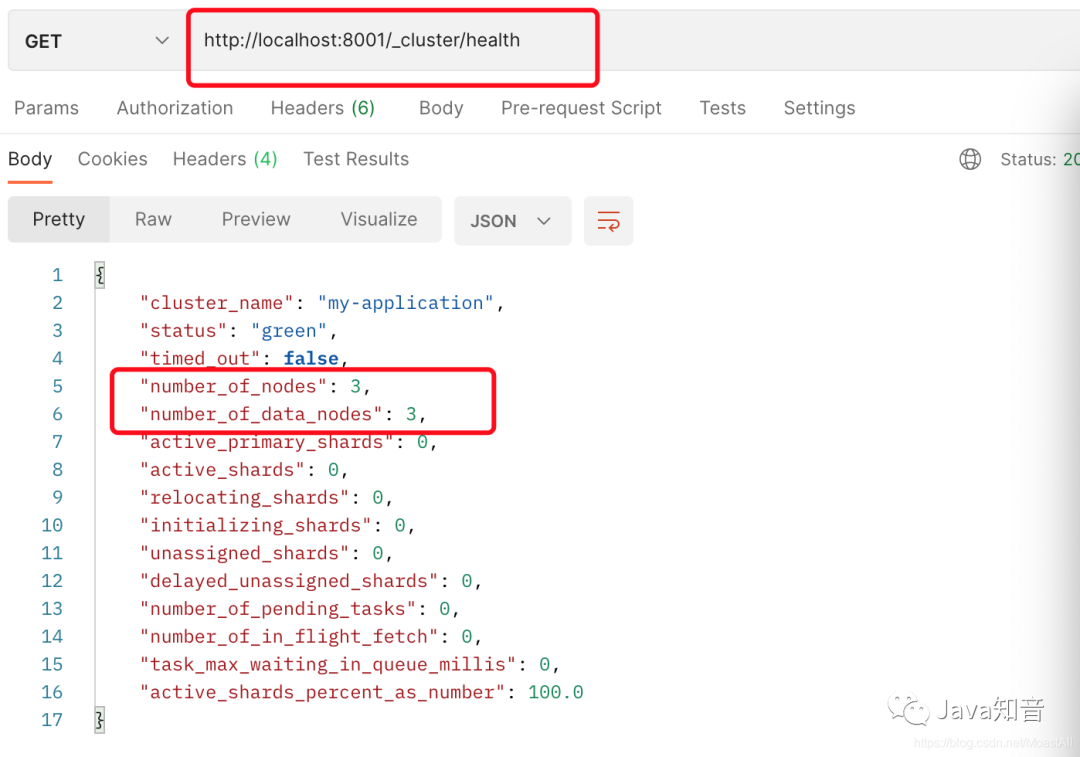
然后按照顺序执行bin/elatsicsearch文件,在postman中通过访问http://localhost:8001/_cluster/health可以看出集群部署成功!
四、操作演示
1.单点集群
我们只启动上面的node-8001的ES(node-8002和node-8003都没启动),为了演示目的,我们将分配3个主分片和一份副本(每个主分片拥有一个副本分片)
通过chrome浏览器的Elastic Head插件,我们可以看出 3 个副本分片都是 Unassigned —— 它们都没有被分配到任何节点。在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。
2.故障转移
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。幸运的是,我们只需再启动一个节点即可防止数据丢失。当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的 cluster.name 配置,它就会自动发现集群并加入到其中。
但是在不同机器上启动节点的时候,为了加入到同一集群,你需要配置一个可连接到的单播主机列表。之所以配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。
这里我们直接启动node-8002和node-8003:
通过chrome浏览器的Elastic Head插件,我们可以看出一切正常!node-8001前面有星号,说明是主节点。并且有加粗边框的分片(例如node-8003都)是主分片,没有加粗的分片(例如node-8002都)是副本。

3.水平扩容
主分片的数目在索引创建时就已经确定了下来。实际上,这个数目定义了这个索引能够存储的最大数据量。(实际大小取决于你的数据、硬件和使用场景。) 但是,读操作——搜索和返回数据——可以同时被主分片 或 副本分片所处理,所以当你拥有越多的副本分片时,也将拥有越高的吞吐量。
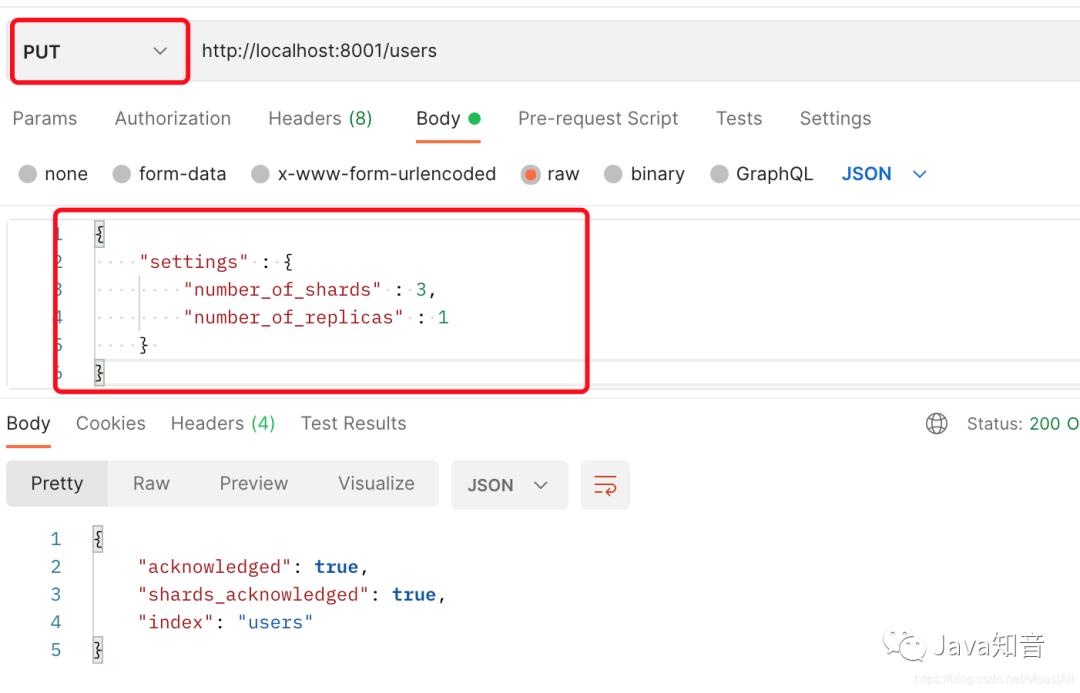
下面就是在索引创建后,修改副本的数量(案例中是把副本数量修改为2),只需要如下的操作:
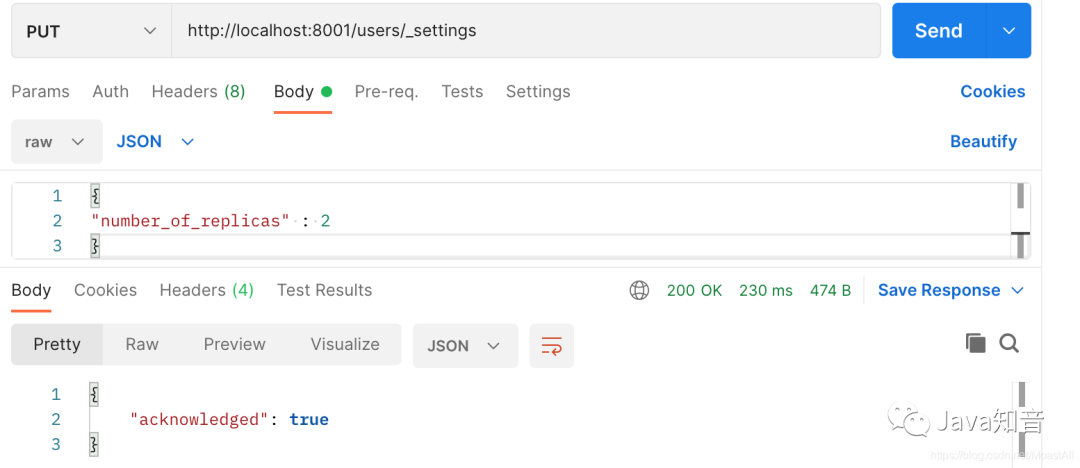
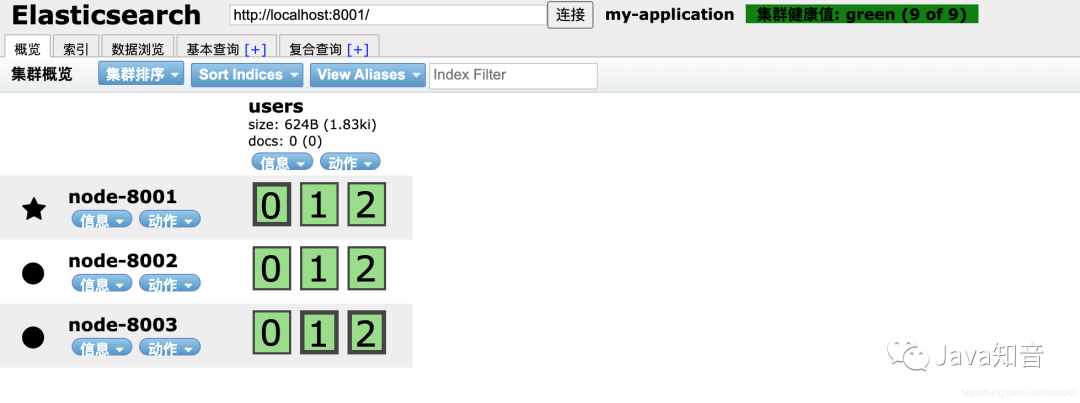
我们再看看elasticsearch head 的监控页面,发现每个节点上已经有三个分片了
4.应对故障
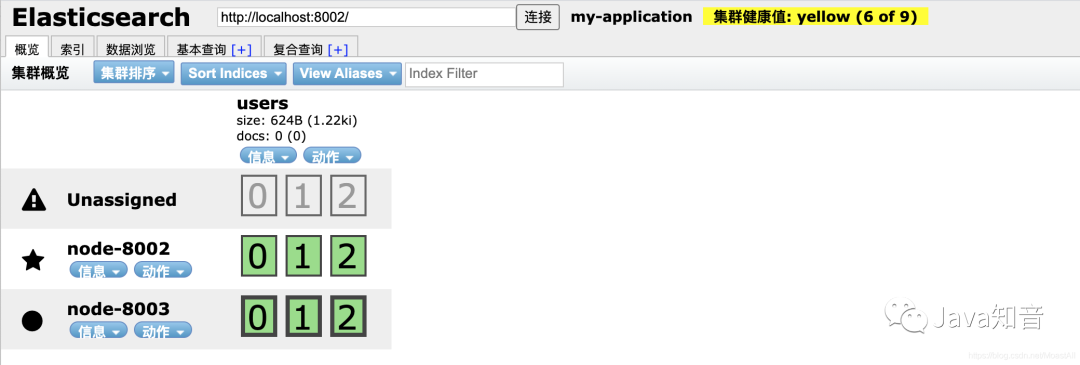
比如node-8001这个主节点某一刻挂掉了(我们直接把node-8001的黑窗口关掉来模拟这种情况)。所以下图很好理解:8001关掉了,自然是未连接!

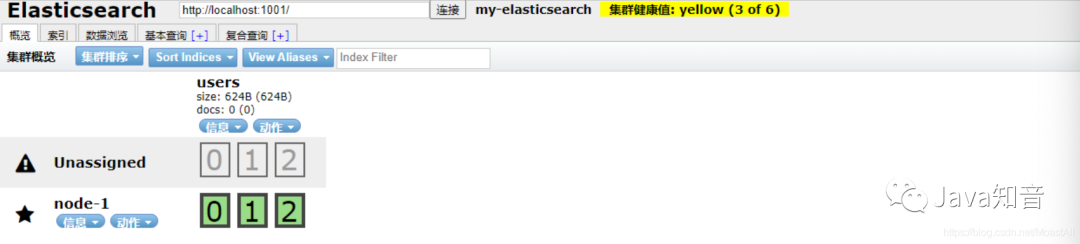
我们来查看8002端口的情况,发现有有三个副本无法分配,虽然健康状态是黄色的,但依旧不会影响使用,依旧可以提供服务!
假设经过抢修,现在8001点故障已经解决了,那我们该如何将其重新加入集群中呢?其实我们只需要下面的操作:
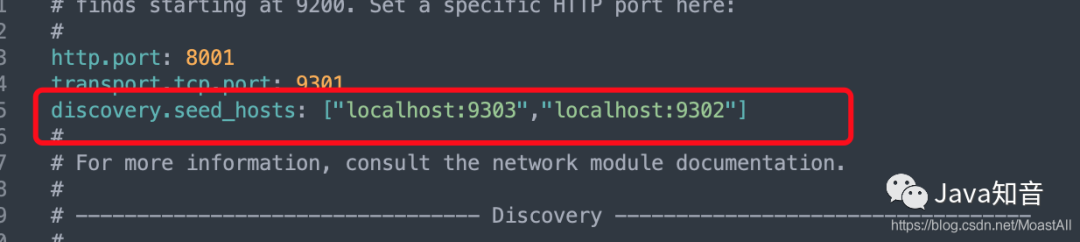
第一步:再次修改config/elasticsearch.yml文件,添加下面的一行
第二步:启动node-8001,发现node-8001已经纳入集群,而且分片正常,但主节点变成了node-8002也不影响使用!
五、路由计算&分片控制
1.路由计算
经过上面的操作,我们会有这样的疑问——当索引一个文档的时候,文档会被存储到一个主分片中。Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片1 还是分片 2 中呢?
这就引出了下面的路由算法,这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。

routing是一个可变值,默认是文档的_id,也可以设置成一个自定义的值。
routing通过hash 函数生成一个数字,然后这个数字再除以number_of_primary_shards(主分片的数量)后得到余数 。
这个分布在0到number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。

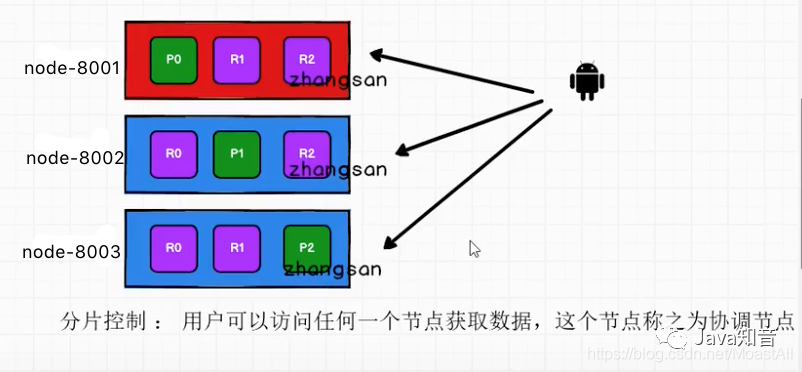
2.分片控制
比如上图,zhangsan文档经过路由计算找到了2号分片,但2号分片在三个节点中都存在(node-8001和node-8002保存的是分片的副本)。我们可以发送请求到集群中的任一节点。每个节点都有能力处理任意请求。
每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点。
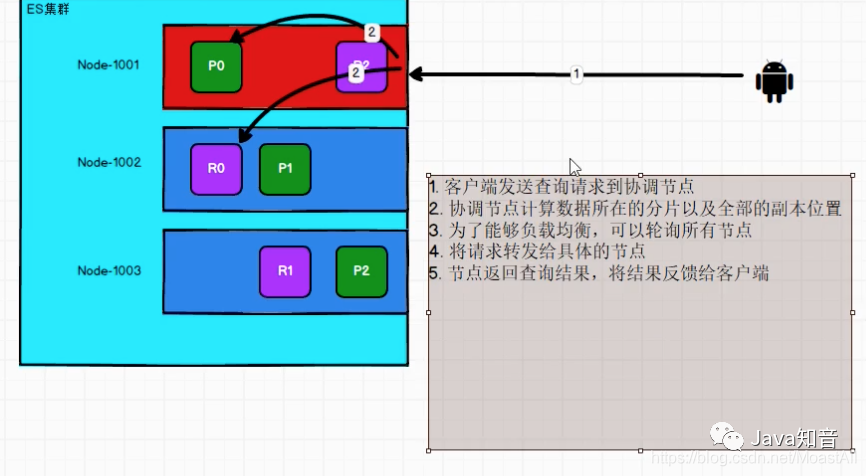
六、集群中的读写操作流程
1.写操作
新建、索引和删除 请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片
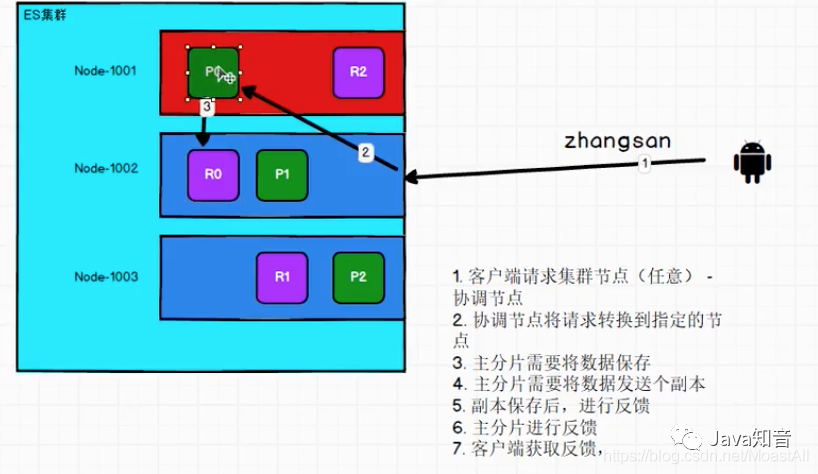
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。有一些可选的请求参数允许您影响这个过程,可能以数据安全为代价提升性能。这些选项很少使用,因为 Elasticsearch 已经很快,但为了知识的完整性请看下方:
- consistency 参数的值可以设为 one (只要主分片状态 ok 就允许执行_写_操作),all(必须要主分片和所有副本分片的状态没问题才允许执行_写_操作), 或quorum 。默认值为 quorum , 即大多数的分片副本状态没问题就允许执行_写_操作。
- 如果没有足够的副本分片会发生什么?Elasticsearch 会等待,希望更多的分片出现。默认情况下,它最多等待 1 分钟。如果你需要,你可以使用 timeout 参数使它更早终止:100 100 毫秒,30s 是 30 秒。
2.读操作
我们可以从主分片或者从其它任意副本分片检索文档