作者:CDA Level Ⅰ持证人
岗位:数据分析师
行业:大数据
背景
在前文(Python实现基于客观事实的RFM模型)中阐述了如何运用分箱的技巧讲客服进行分群,有兴趣的读者可以去回顾 一下。利用流行的编程语言---Python及分箱技巧进行RFM模型构建,结果发现,此方法有效了降低人工分群带来的主观性影响,然而,会出现类似偏态的现象。其原因是在于分箱的操作对R值、F值、M值都进行了一遍。因此,为解决这种类似偏态的问题,本文将利用机器学习中的K-Means聚类对客户进行分群。
如今新基建大数据、人工智能行业在迅速的发展,而机器学习是其中不可或缺的一环,机器学习强调的是利用人脑一般从历史的数据中学习到经验并运用与未来的判断中。而K-Means模型则是机器学习中聚类算法中的一块,本文结合Python实现K-Means聚类算法的编写,同时应用于客户分群中。
本文采用Anaconda进行Python编译,主要涉及的Python模块:
pandas
matplotlib
seaborn
numpy
scikit-learn
本章分为三部分讲解:
K-Means聚类原理与算法步骤
Python实现K-Means聚类算法
基于K-Means的RFM客户分群构建
对比与总结
"人以类聚,物以群分",这句话就是K-Means模型的思想点。其中,K代表类别数量(Tips:在机器学习中,自变量又叫预测变量,因变量又叫目标变量)。而Means代表每个类别中样本的均值,因此这个Means也即均值的意思(Tips:这里的样本通俗理解就是一个记录行)。
K-Means聚类是以距离作为样本间相似度的度量标准,将距离相近的样本分配至同一个类别。样本间的度量方式可以是欧氏距离,马氏距离,余弦相似度等,K-Means聚类通常采用欧氏距离来度量各样本间的距离。
欧式距离又称欧几里得度量,为常见的两点之间或多点之间的距离表示法,如类别$x=(x{1},x{1},...,x{n})$与类别$y=(y{1},y{2},...,y{n})$间的距离如下式:
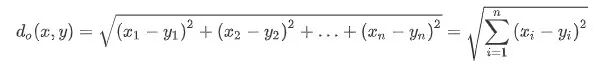
马氏距离同样也是一种距离的度量,是由马哈拉诺比斯(P. C. Mahalanobis)提出的,表示样本间的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。这可以看作是欧式距离的修正,修正了欧式距离中各个维度尺度不一致且相关的问题。
对于一个均值为$\mu=(\mu{1},\mu{2},...,\mu_{p})^{T}$,协方差矩阵的S的多变量$x=(x^{1},x^{2},...,x^{p})^{T}$,其马氏距离为下式
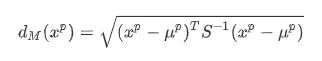
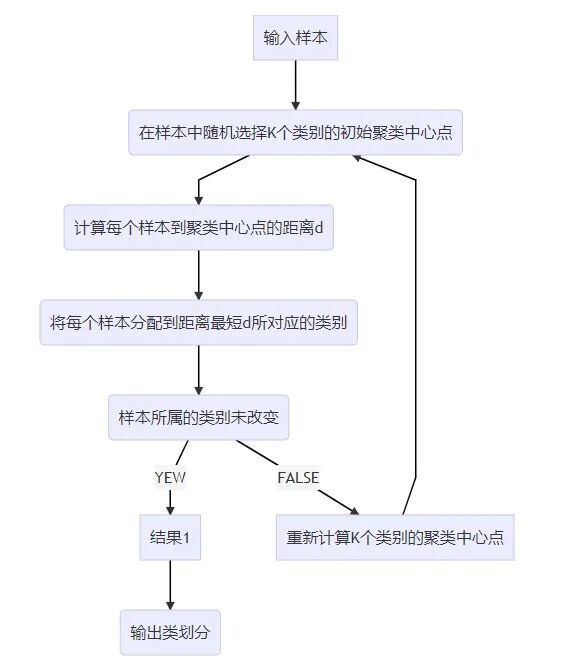
输入:样本集D,设定类别数目K
输出:类划分(K个类)
以流程图展现算法步骤,
在上述原理和算法步骤可能有读者不是很清楚,那么接下来将以例子的形式更加具体的展现K-Means是如何进行聚类的。首先利用scikit-learn库中的datasets接口生成随机样本点作为我们的聚类输入值,以可视化形式展现,如下图:
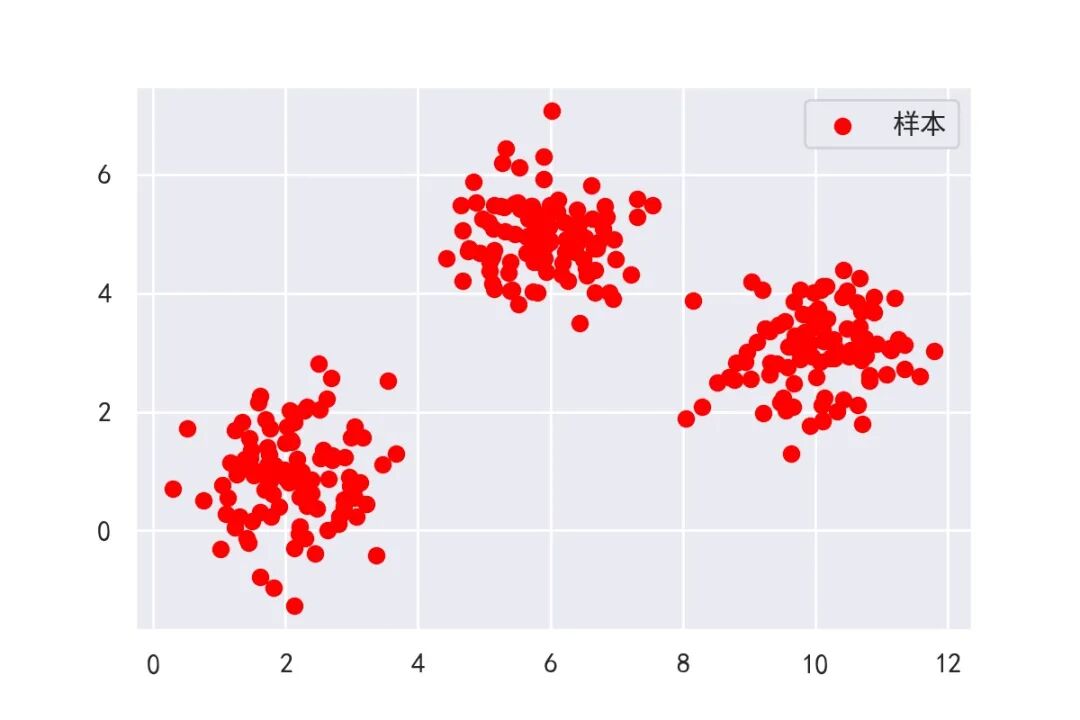
从上图可以看出输入的样本点肉眼可见可以分成3类,那么怎么用K-Means将此样本集识别出3类呢。这里用到scikit-learn库中的KMeans接口,该接口的训练算法与上述算法是大同小异的。其中稍有差别的是,初始的类中心点的选择并不是随机的,而是选择k-means++的初始化方案,将类中心化为彼此原理的点。具体而言将在代码体现。其次不同的是,结束条件,上述算法步骤的结束条件时判断各类别中的样本是否发生改变,而KMeans接口中的结束条件是类似于利用损失函数:$||Means{old}-Means{new}||$,该式子的意思是计算旧类中心点于新类中心点的距离,如果该距离小于给定的值$\epsilon$,则结束,输出类别。
上述样本点的构建及可视化的代码如下
import numpy as np import matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.datasets import make_blobssns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ["SimHei"]plt.rcParams["axes.unicode_minus"] = False
np.random.seed(123)centers = [[2, 1], [6, 5], [10, 3]]n_clusters = len(centers)X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.7)plt.scatter(X[:,0],X[:,1],c='red',marker='o', label='样本')plt.legend()
plt.savefig('example.jpg',dpi=200)plt.show()
首先设置可视化的主题为seaborn下的黑格子状态,其次选择围绕(2,1),(6,5),(10,3)这三个点(类中心点)构造样本集。运用make_blobs()函数即可构建样本集,该函数中可以设定样本集的数量n_samples和方差cluster_std。最后以散点图形式展现。最后调用KMeans接口,将该样本集进行聚类,用可视化的方式对聚类后结果进行展现,结果如下图
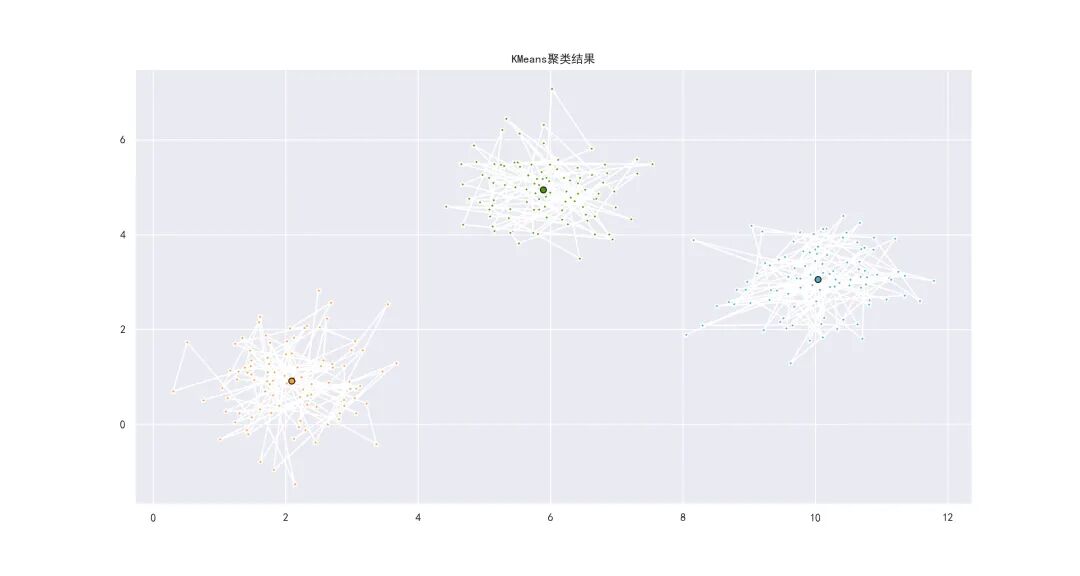
可以明确看到,聚类结果为3类,和我们预期的是一致的,接下来看类别中心点于原设计的中心点对比,如下表。
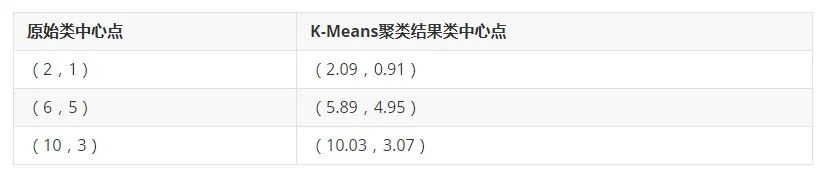
从上表可以看出,聚类中心点是存在微小差异的,这也说明KMeans接口时利用损失函数进行迭代的。相关代码如下
from sklearn.cluster import KMeanssns.set_style('darkgrid')plt.rcParams['font.sans-serif'] = ["SimHei"]plt.rcParams["axes.unicode_minus"] = False
k_means = KMeans(init="k-means++", n_clusters=3)k_means.fit(X)
fig = plt.figure(figsize=(15,8))colors = ["#4EACC5", "#FF9C34", "#4E9A06"]k_means_cluster_centers = k_means.cluster_centers_k_means_labels = k_means.labels_ax = fig.add_subplot()for k, col in zip(range(n_clusters), colors): my_members = k_means_labels == k cluster_center = k_means_cluster_centers[k] ax.plot(X[my_members, 0], X[my_members, 1], "w", markerfacecolor=col, marker="*") ax.plot( cluster_center[0], cluster_center[1], "o", markerfacecolor=col, markeredgecolor="k", markersize=6, )ax.set_title("KMeans聚类结果")plt.savefig('例子结果.jpg',dpi=200)
KMeans(init="k-means++", n_clusters=3)这段代码即将估计器拟合上述的样本集。其中,init参数即为上述所讲KMeans++的初始化选择方式。而后的参数为设定分成多少类。拟合后的KMeans估计器是可以进行调用的,这里我们调用类中心点(k_means.cluster_centers_)和样本所属类别(k_means.labels_)。最后一段代码是结合类中心点和样本所属类别进行可视化展示,可以非常明确的看到聚类后的结果。(TIps:最后保存图片的dpi是调整像素的,在Python编译器里面默认保存的图像像素普遍都不高,读者可以适当的设置。)
K-Means模型构建(代码)
有了数据和scikit-learn库中的KMmeans接口的了解,那么接下来先上完整代码和解释,模型构建的代码如下
import pandas as pdimport seaborn as snssns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ["SimHei"]plt.rcParams["axes.unicode_minus"] = False
data = pd.read_excel('rfm.xlsx')X = data.drop(columns = 'user_id')
k_means = KMeans(init="k-means++", n_clusters=8,random_state=123)k_means.fit(X)
data['categories'] = k_means.labels_
k_means.cluster_centers_k_means.verbose
result = k_means.cluster_centers_reuslt = pd.DataFrame(result)reuslt['R_label'] = pd.qcut(reuslt[2],2,labels = range(1,3)).astype('int')reuslt['F_label'] = pd.qcut(reuslt[0],2,labels = range(1,3)).astype('int')reuslt['M_label'] = pd.qcut(reuslt[1],2,labels = range(1,3)).astype('int')
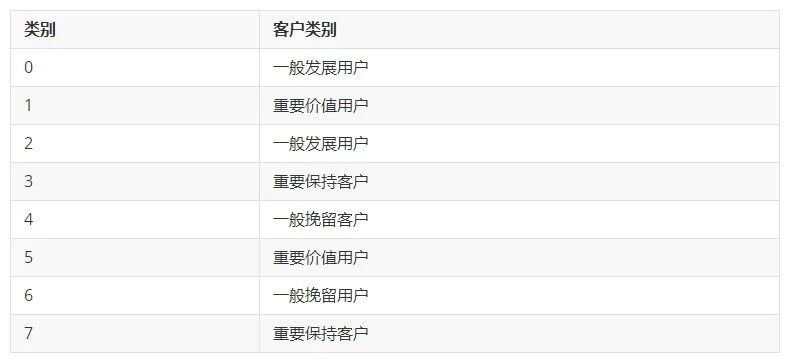
for i,j in data.iterrows(): if j['categories'] == 0 or j['categories'] == 2: data.loc[i,'客户类别'] = '一般发展用户' if j['categories'] == 1 or j['categories'] == 5: data.loc[i,'客户类别'] = '重要价值用户' if j['categories'] == 3 or j['categories'] == 7: data.loc[i,'客户类别'] = '重要保持客户' if j['categories'] == 4 or j['categories'] == 6: data.loc[i,'客户类别'] = '一般挽留客户'
cate_sta = data['客户类别'].value_counts()cate_sta = pd.DataFrame(cate_sta)sns.barplot(y='客户类别', x=cate_sta.index, data=cate_sta)plt.title('用户类别统计')plt.show()
代码解释:
首先,明确我们的模型构建目标。对于一份客户行为价值数据而言,我们是不知道这其中到底包括几种类别的客户的,有可能包含了8类,也有可能包含3类等。而这个类别的确定就需要通过KMeans模型自动的去识别。因此,首先我们设定聚类的簇(类别数目)为RFM中的总类别数量8种,初始化的类中心点依旧使用KMeans++的方式。这段内容在上面注释为KMeans模型构建部分。
有了拟合后的模型后,我们就需要查看拟合后的相关属性结果,k_means.cluster_centers_,k_means.labels_这两个函数分别查看8个类中心点和对于每个id所属的类别。
接着,有了类中心点之后,我们就需要对类中心点进行等深分箱。
最后赋予每个用户相应的客户类别并进行可视化直观展示,下面将详细对结果进行阐述。
K-Means模型结果计息
利用在第二部分所学知识,即可对这份数据进行一个KMeans聚类,得到的结果如下表:
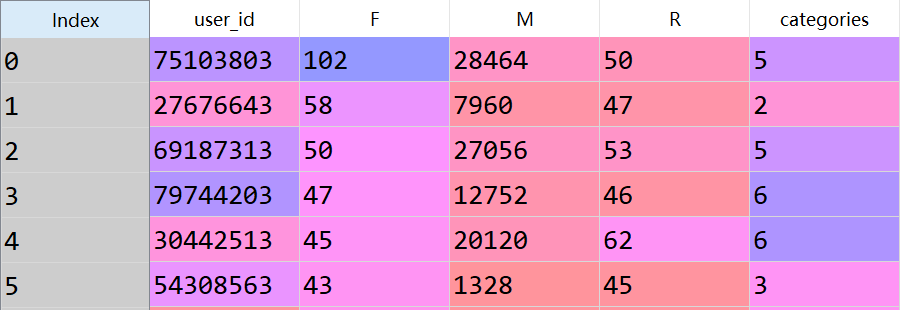
从上图可以看到,利用KMeans的估计器,我们已经得到了每个id所属的类别,那么现在的问题是,该怎么判断用户是哪种客户类别呢(Tips:用户类别分为8种,不清楚的读者可以回顾前文),这时候就需要用到类中心点,通过判断类中心点来给每种分类一个判断,下表为每个类别对应的类中心点。
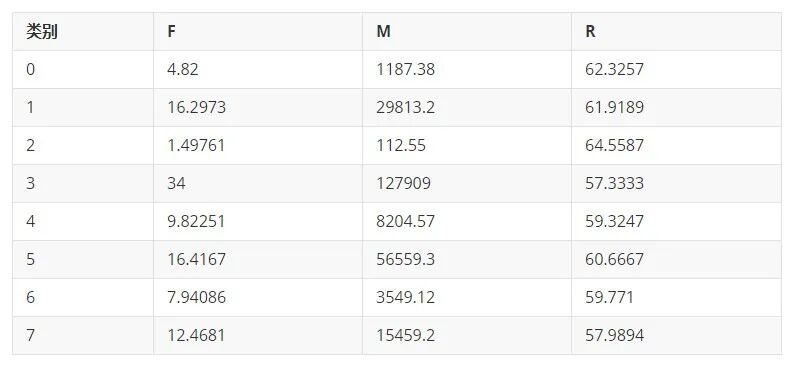
有了每个类别的类中心点,我们就需要对每个类赋予RFM模型中的客户类别,本文在这方面选择分箱的技巧进行分类。
对类中心点实现等深分箱,与前文运用等距分箱不同,这里采取的是指定每个类别种的个数是一致的,这也符合RFM模型中的每个值都有4个高,4个低。在Python中利用pd.qcut()函数进行分箱,其参数与等距分箱大同小异,有兴趣的读者可以研究。最后以"2"代表高,"1"代表低。并按照RFM的规则将每种类别赋予一个客户类别,结果如下表:
最后,以柱状图的形式展示该份数据集中的客户类别总数
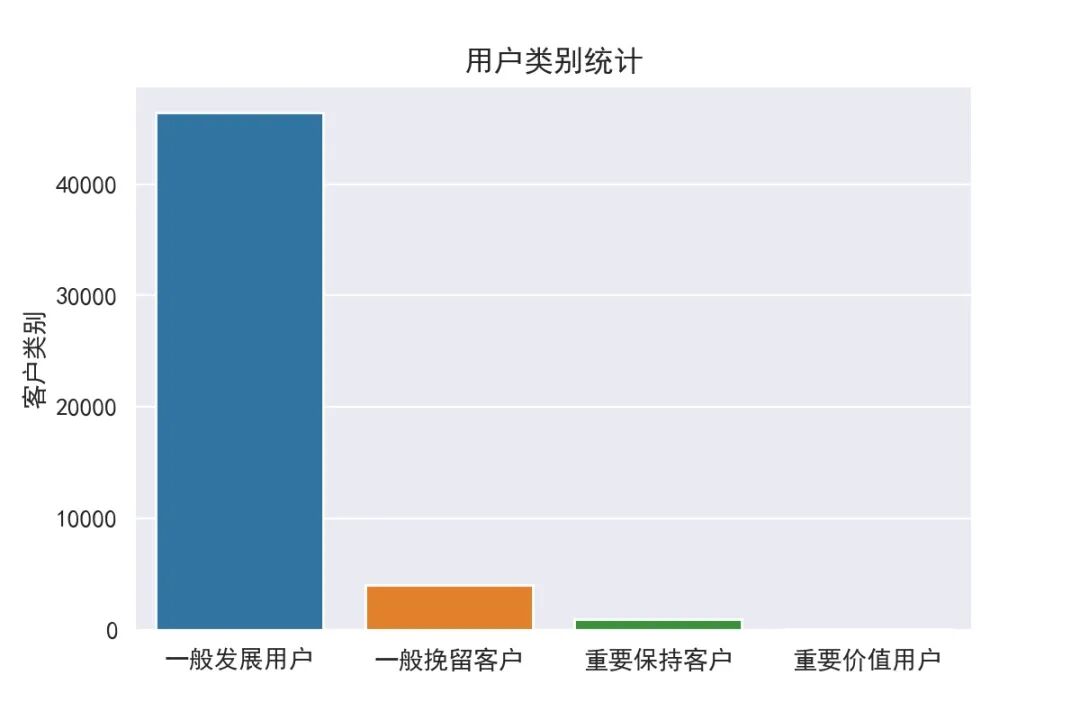
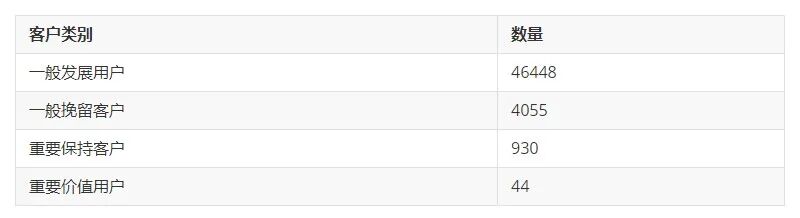
与前文(Python实现基于客观事实的RFM模型)对比,本文将该份数据集中的用户分为4类(一般发展用户、重要保持客户、一般挽留客户、重要价值用户),而前文将用户分为5类(一般发展用户、一般挽留用户、重要挽留客户、一般保持用户、重要发展用户)。可以看出,两者都识别出了一般发展用户的信息,且其所占比例也是最多的。不同之处在于,基于KMeans聚类模型的RFM模型可以挖掘出重要保持客户、重要价值用户的信息,而基于客观事实的RFM模型对一般挽留用户较为敏感。
因此,对于决策者而言,每个模型得到的RFM模型是不一致的,而决策者应该从模型结果的相同点入手,如该份数据,两个模型都发现了一般发展用户所占比例是最大的,代表其解释性强。而对于模型间的不同点,则需要更深入的探讨如何取舍的问题。

点这里👇关注我,记得标星哦~













