当前最先进的深度学习模型存在一些根本问题,而来自集体智能,特别是复杂系统的概念,往往可以提供有效解决方案。事实上,复杂系统领域的概念,如元胞自动机、自组织、涌现、集体行为,与人工神经网络有着悠久的联系。2021年12月arxiv上刊载的一篇综述文章,梳理了复杂系统与神经网络相互交织的发展历程,从图像处理、深度强化学习、多智能体学习、元学习等几个活跃领域,展示了结合集体智能原理对深度学习研究的推动作用。
研究领域:深度学习,集体智能,复杂系统,元胞自动机,自组织,涌现
David Ha, Yujin Tang | 作者
陈斯信 | 译者
梁金 | 审校
邓一雪 | 编辑

论文题目:
Collective Intelligence for Deep Learning: A Survey of Recent Developmentshttps://arxiv.org/abs/2111.14377
目录
摘要
一、引言
二、历史背景
三、深度学习中的集体智能
1、图像处理
2、深度强化学习
3、多智能体学习
4、元学习
四、将深度学习用于集体智能研究
五、结论
在过去十年里,我们见证了深度学习崛起并在人工智能领域占据主导地位的过程。人工神经网络的进步,以及相应的具有大内存容量的硬件加速器的发展,再加上大型数据集的可得性,使得研究人员和从业人员能够训练和部署复杂的神经网络模型,在计算机视觉、自然语言处理和强化学习等多个领域的任务上取得最佳性能。然而,随着这些神经网络变得更大、更复杂、应用更广泛,当前深度学习模型的根本问题变得更加明显。众所周知,当前最先进的深度学习模型也有一些问题,包括不够稳健,无法适应新的任务,配置需要严格和不灵活的假设等。来自集体智能的观念,特别是来自复杂系统的概念,如自组织、涌现行为、粒子群优化(swarm optimization)和元胞自动机,往往会产生稳健的、适应性的解决方案,并且对环境配置的假设没那么严格。因此,看到这些观念被纳入到新的深度学习方法中,并不奇怪。在这篇综述里,我们将提供一个涉及复杂系统的神经网络研究的历史脉络,并着重于现代深度学习研究中几个活跃的领域,这些领域结合了集体智能的原理来提升当前模型的能力。为了促进观念的双向流动,我们还讨论了那些利用现代深度学习模型来帮助推进复杂系统研究的研究。我们希望这篇综述可以成为复杂系统和深度学习社区之间的桥梁,促进观念的交叉传播,并促进跨学科的新合作。
深度学习
(deep learning, DL)是一类使用多层(“深度”)神经网络进行表征学习的机器学习方法。早在20世纪80年代,用反向传播算法训练的人工神经网络就出现了[57],但直到2012年,深度神经网络才受到广泛关注。当时,在一年一度的图像识别比赛中,基于在GPU上训练的深度人工神经网络的方法[35]以显著优势战胜了不基于深度学习的方法。这次成功表明,在有硬件加速方案以及大型数据集的情况下,深度学习能够在有意义的任务中取得比传统方法更好的结果。研究人员和从业人员很快就开始用深度学习来解决其它几个领域一些长期存在的问题,包括计算机视觉(computer vision, CV)[24,47,60],自然语言处理(natural language processing, NLP)[5,48,49],强化学习(reinforced learning, RL)[37,59,68]和计算生物学[32,58]等;在许多领域里,都取得了技术上的突破和最好的效果。图1. GPU硬件的近期发展使我们能对数以千计的机器人进行现实三维模拟,就像本图所展现的Rudin等人所做的一样[53]。这样的进步使我们能对大规模、可以进行互动并协同发展智能行为的的人工智能体进行三维模拟。
然而,深度学习并不是没有副作用的灵丹妙药。虽然我们见证了许多成功的案例,并且越来越多地在使用深度神经网络,但随着模型和训练算法变得越来越大,越来越复杂,深度学习的根本问题也越来越明显地暴露出来。深度学习模型在某些情况下并不稳健。比如,大家都知道,只要修改视频游戏屏幕上的几个像素(这种修改人类根本无法察觉),用未修改的屏幕训练出来的智能体(原本超过人类表现)就可能失败[46]。另外,在没有特殊处理情况下训练的计算机视觉模型,可能无法识别旋转或者经过相似变换的例子。换句话说,我们目前的模型和训练方法并不能自动泛化到新的任务。最后但同样重要的是,大多数深度学习模型并不能适应变化。它们假设了固定的输入,并需要固定的配置。比如,它们可能需要固定大小,固定顺序的输入。即使这些模型已经学会并巩固了完成任务所需要的技能,一旦这些假设和配置不成立,模型也不会有好的表现,除非我们手动训练它们,或者手动处理输入,使之与预期一致。来自集体智能(Collective Intelligence,CI)的概念倾向于产生稳健、自适应的解决方案,并且对环境配置的假设没那么严格。将这些概念应用到深度学习之中,有助于自然地解决一些问题。事实上,许多受集体智能启发的概念已经广为人知;最简单的将集体智能纳入深度学习的例子是:训练一个含有若干个模型的集合,并根据平均输出进行预测。这类似于我们在社会中会看到的投票机制。然而,个体之间的沟通或其它高层活动,通常不在“输出”层面考虑或实施。为了将这些活动也纳入考虑,深度学习和集体智能的其它组合采纳了复杂系统的一些概念,如自组织、涌现行为、粒子群优化和元胞自动机。由此产生的系统,已经被证明是上一段所述某些问题的潜在解决方案。例如,基于元胞自动机的神经网络可以抵抗噪音,甚至在损坏时“自我修复”[38]。另一个例子是,模块化、去中心化的自组织控制器,不仅展现了通用控制器的可能性,而且在部署在多个不同形态的机器人上时(在模拟中)也能保持性能[29]。通过将每个感觉神经元建模为一个单独的神经网络,并允许这些神经网络互相通信,拥有这个层的模型能够处理任意大小,任意顺序的输入[65]。最后,图1展现了在单个GPU上同时训练几千个强化学习智能体的结果[53]。随着硬件加速技术的不断进步,我们当然可以期待看到更多,将集体智能的概念融入基于群体的深度强化学习的研究。这篇综述的目的是对最近在深度学习范式中利用了“自组织”和“涌现行为”等概念的研究进行调研。反过来,用深度学习模型来分析传统的元胞自动机系统也很有用,虽然这不是本文的重点,但我们也会讨论。虽然人工智能领域的研究范式层出不穷,但事实证明,要进一步理解更重要的问题(例如不同时间尺度的全球气候变化模型),就更需要来自复杂系统领域的核心观念。我们将看到,不管我们目前的人工智能研究处于何种范式,总有一些观念是可以应用的。
来自复杂系统领域的概念和观念,如元胞自动机(cellular automata, CA)、自组织、涌现与集体行为,与人工神经网络有着悠久而有趣的历史关系。虽然连接主义和人工神经网络是在20世纪50年代,随着人工智能作为一个研究领域的诞生而出现的,但我们的故事开始于20世纪70年代。当时,先驱Leon Chua领导了一群电子工程师,开始发展非线性电路理论,并将其应用于计算。他因在20世纪70年代构思了忆阻器(Memristor,一种最近才实现的电子器件)以及蔡氏电路(Chua circuit,最早有混沌行为的电路之一)而闻名。在20世纪80年代,他的团队开发了元胞神经网络(Cellular Neural Network, CeNNs),这是一种类似于元胞自动机的计算系统,但使用神经网络来代替元胞自动机系统(如康威生命游戏[14]或Wolfram的初等元胞自动机[70])中典型的算法单元。元胞神经网络[11,12]是一种人工神经网络,里面的每个神经元或元胞只能和它们的近邻互动。在最基本的设置里,每个元胞的状态用一个基于其邻居状态和自身状态的非线性函数持续更新。与依赖数字化、离散化计算的现代深度学习方法不同,元胞神经网络是时间上连续的系统,可以用非线性电子元件实现高速模拟计算(尽管其时间离散版本后来已经用FPGA硬件实现[39])。元胞神经网络的动态演化依赖于独立、局部的信息处理,以及处理单元之间的互动。与元胞自动机一样,它们也表现出了涌现行为,并且可以被做成通用图灵机。然而,它们比离散的元胞自动机和数字计算机要通用得多。由于连续的状态空间,元胞神经网络表现出前所未有的涌现行为。[20]从1990年代到2000年代中期,元胞神经网络成为人工智能研究的一个子领域。由于其强大而高效的分布式计算能力,它被应用到图像处理和纹理分析中。由于其与生俱来的模拟计算能力,它也被应用于偏微分方程的求解,甚至是生物系统和器官的建模。关于元胞神经网络,有数以千计的同行评议论文、教科书,以及一个专门讨论的IEEE会议,还有许多扩大、堆叠它们,将它们与数字电路结合的提议,以及对不同训练方法的研究(就像我们目前在深度学习中看到的那样)。至少有两家硬件初创公司成立,来生产元胞神经网络的硬件与设备。然而,在2000年代后期,它们突然从舞台上消失了。2006年以后,人工智能界几乎不再提及元胞神经网络。而从2010年代开始,GPU成为神经网络研究的主要平台,神经网络也改头换面为深度学习。没有人真的知道元胞神经网络在人工智能研究中消亡的确切原因。也许是元胞神经网络领先于它的时代(就像忆阻器一样),也许是消费级GPU的崛起使GPU成为一个引人注目的深度学习平台。人们只能想像,在一个元胞神经网络的模拟计算机芯片赢得硬件彩票的平行宇宙里,人工智能的状态可能会非常不同。在那个宇宙里,世界和我们所有的设备,都嵌入了强大的分布式的元胞神经网络。
然而,元胞神经网络和深度学习的一个关键区别是前者使用不够方便,在我们看来,这是它没有流行起来的主要原因。在目前的深度学习范式中,有一个完整的工具生态系统,旨在简化神经网络的训练和部署。用深度学习框架来训练神经网络也是相对直接的,只要给它提供一个数据集[9]或者一个模拟的任务环境[26]。深度学习工具被设计成任何一个有基本编程背景的人都可以使用。相比之下,元胞神经网络是为电子工程师设计的,毕竟在那个年代,电子工程的学生对模拟电路的了解多于编程语言。为了说明这一困难,“训练”一个元胞神经网络需要解一个至少有9个常微分方程的系统,来决定支配模拟电路的系数,从而定义系统的行为。在实践中,许多从业者需要依赖一本包含已知问题的解决方案的手册[10],然后为新问题调整解决方案。后来,人们提出遗传算法(以及早期版本的反向传播)来训练元胞神经网络[34],但电路需要模拟软件来训练和测试,才能部署到实际的(高度定制的)元胞神经网络硬件上。我们也许可以从元胞神经网络中学到更多,毕竟它们是模拟和数字计算的强大混合体,真正地结合了元胞自动机和神经网络。不幸的是,在它们消亡之前,我们见证的可能只是其全部潜力的一小部分。后来,商品化的GPU,以及将神经网络抽象为简单的Python代码的工具,使深度学习能够接管。虽然元胞神经网络已经消失了,但来自复杂系统的概念和观念,如元胞自动机、自组织和涌现行为,并没有消失。我们正在见证集体智能的概念在深度学习的许多领域重现出现(尽管仅限于数字硬件),从图像生成、深度强化学习,到群体式和分布式学习算法。正如下文将呈现的,这些概念正在为传统人工神经网络的一些局限和限制提供解决方案,从而推进深度学习的研究。
集体智能从网络中自然产生,因此,看到自组织行为在人工神经网络中自然涌现,也就不奇怪了,尤其是当我们在全局范围采用有着相同权重的相同模块进行重复计算时。例如,Gilpin[19]观察到元胞自动机和卷积神经网络(convolutional neural networks, CNNs,一种常用于图像处理的神经网络,对所有的输入都采取相同的权重(或过滤器))之间的密切联系。事实上,他们表明,任何元胞自动机都可以用某种卷积神经网络来表示,并且用它优雅地演示了康威生命游戏[14],说明在某些情况下,卷积神经网络可以表现出有趣的自组织行为。近期的一些研究,例如Mordintsev等人的工作[38](我们将在后面讨论),利用卷积神经网络的自组织特性,并开发了基于神经网络的元胞自动机,应用于图像再生等。其它类型的神经网络架构,如图神经网络(Graph Neural Networks,GNNs)[54,71]明确地以自组织为中心特征,将图的每个节点(node)的行为,建模为相同的神经网络模块,该模块将信息传递给由图的边(edge)所定义的邻居。传统上,图神经网络被用来分析图,例如社会网络和分子结构。而近期的研究[21]也证明图神经网络有能力为既定的元胞自动机系统(例如维诺图或蜂群的成群行为)学习规则。正如我们将在后面讨论的那样,图神经网络的自组织特性最近被用于深度强化学习领域,创造出有更强泛化能力的智能体。我们已经识别出了深度学习的四个领域,这四个领域已经开始将集体智能相关的观念纳入考虑。(1)图像处理,(2)深度强化学习,(3)多智能体学习,以及(4)元学习。我们将在本节中详细探讨每个领域并提供例子。图2. Randazzo等人创建的用于识别MNIST数字的神经元胞自动机[50]还有一个在线的可互动的演示程序。每个元胞只允许看到一个像素的内容,并与它的邻居交流。随着时间推移,这些元胞将就哪个数字是最有可能的形成共识。但有趣的是,分歧还是会因为像素位置而产生,特别是在图像故意糅合了不同数字的时候。
采用元胞自动机的方法来学习图像的替代表示,有助于学到自然媒介中的隐含关系和重复出现的模式。Mordvintsev等人提出的神经元胞自动机(neural CA)模型[38],和元胞神经网络一样,将图像的每个像素视为一个单独的神经网络元胞。这些网络被训练成根据其近邻的状态来预测其颜色,从而形成了一个图像生成的形态发生模型。他们证明了通过这种方式训练神经网络来重建整个图像是可能的,即使每个元胞并没有关于其位置的信息,只依赖来自其邻居的局部信息。这种方法使得生成算法能够抵抗噪音,并允许图像在受损时再生。神经元胞自动机的一个拓展版本[50]使单个元胞能够执行图像分类任务(如MNIST数字分类),只通过检查单个像素的内容,并将信息传递给该元胞的近邻(见图2)。随着时间的推移,这些元胞将形成共识,即哪个数字是最有可能的。但有趣的是,分歧还是会因为像素位置而产生,特别是在图像故意糅合了不同数字的时候。利用神经元胞自动机进行图像再生并不局限在二维图像。在后来的研究中,Zhang等人[73]采用了一种类似的方法来生成三维体素。这对高分辨率的三维扫描特别有用,在这种情况下,三维形状的数据往往用稀疏和不完整的点来描述。使用生成式元胞自动机,他们可以从部分点的集合中恢复完整的三维形状。这种方法不仅局限于纯生成领域,也可以应用于活跃环境(如Minecraft)中人工智能体的构件。Sudhakaran等人[64]训练神经元胞自动机,来在Minecraft中生长复杂的实体,如城堡、公寓和树,有些实体由成千上万的块构成。除了再生,它们的系统还可以修复简单功能机器(如游戏中的虚拟生物)的部件。他们演示了一个形态发生学的生物,在虚拟世界中被切成两半,还可以生长成两个分离的生物(见图3)
。元胞自动机也天然地适用于为图像提供视觉解释。Qin等人[45]研究了分层元胞自动机在视觉显著性方面的应用,即识别图像中突出的部分。通过让元胞自动机对从深度神经网络中提取的视觉特征进行操作,他们能够迭代地建构图像的多尺度显著性图,从而使最后的图像接近目标。Sandler等人[56]后来研究了元胞自动机在图像分割任务上的应用,这是一个深度学习已经取得了巨大成功的任务。他们证明,使用规则相对简单的元胞自动机(神经网络参数只有一万)执行复杂的分割任务是可行的。该方法的优点是能够扩展到令人难以置信的大尺寸上,这种拓展对受GPU内存限制的传统方法是一个挑战。图3. 神经元胞自动机也被用于Minecraft游戏中实体的再生。Sudhakaran等人的构造不仅使Minecraft建筑、树木能够再生,而且使得游戏中的简单功能机器,如蠕虫状生物在被切断时,能够再生成两个分离的生物。使用深度学习技术进行强化学习,即深度强化学习(deep reinforcement learning, Deep RL),与深度学习的兴起是同步的。深度学习为强化学习智能体配备了现代神经网络架构,可以解决更复杂的问题,如高维连续控制或基于像素级观测的视觉任务。虽然深度强化学习与深度学习有同样的优点,即计算资源足够,一般就能发现目标任务的解决方案,但前者有着与后者一样的局限性。当任务稍有改变时,为执行某一特定任务而训练的智能体往往会失败。此外,神经网络的解决方案一般只在有明确的输入-输出映射、针对特定的形态时适用。例如,为四条腿的蚂蚁训练的运动策略,可能对六条腿的蚂蚁不起作用。如果一个智能体被设计成接受10个输入,而你给它输入了5个或者20个,它就无法工作。演化计算界很早就开始处理上述的一些挑战,将模块化(modularity)纳入决定了人工智能体设计的演化过程中。智能体由相同但独立的模块组成。模块之间的局部互动促进自组织,使系统对形态学的变化具有稳健性。对演化而来的系统来说,拥有这种性质是一个基本要求。这些观念已经出现在关于软体机器人的文献里[8],文中报告的机器人由网格化的体素细胞组成,每个细胞由独立的神经网络控制,具有局部感知功能,可以产生局部的行动。通过信息传递,组成这一机器人的细胞群能够自组织,并执行一系列的运动任务(见图4)。后来的研究[31]甚至提出,可以在细胞布置的演化中加入变形,以产生在一系列环境中都能稳健的配置。最近,软体机器人甚至结合了前面讨论的神经元胞自动机,使这些机器人能够自我再生[28]。深度强化学习界里常用纯策略优化,而软体机器人文献里常见关于“软体-策略协同进化”的研究,为了连接这两者,Bhatia等人[3]最近开发了一个类似于OpenAI Gym的环境,称为Evolution Gym。这是一个基准平台,能开发和比较一些能对设计与控制进行协同优化的算法。它提供了一个用C++编写的高效的软体机器人模拟器,并带有Python接口。图4. 在二维和三维空间里模拟软体机器人的例子。每个细胞代表一个独立的神经网络,具有局部感知功能,能产生局部的动作,包括与相邻细胞进行交流。训练这些系统来完成各种任务,不仅涉及到训练神经网络,还涉及到对形成智能体形态的软体细胞的设计和布置。图片来自Horibe等人的研究[28]。
模块化的、分散的自组织控制器,在深度强化学习界也有人在探索。Wang等人[69]和Huang等人[29]探索了使用模块神经网络来控制一个模拟机器人的各个传动器来实现连续控制。他们将全局运动策略视为模块神经网络(在Huang等人的例子[29]里是相同的神经网络)的集合,对应智能体的各个传动器,并使用强化学习来训练系统。像软体机器人一样,每个模块只负责控制其相应的传动器,并且只从局部传感器接受信息(见图5)。消息在相邻模块之间传递,逐渐传播到遥远的模块。他们表明,一个单一的模块策略可以为几种不同形态的机器人产生运动行为,而且这些策略可以泛化到训练中未见的形态,比如有额外的腿的生物。与软体机器人的情况一样,这些结果也证明,分散模块之间的信息传递中可以涌现出中心化的协作,协同地优化一个共享的奖励。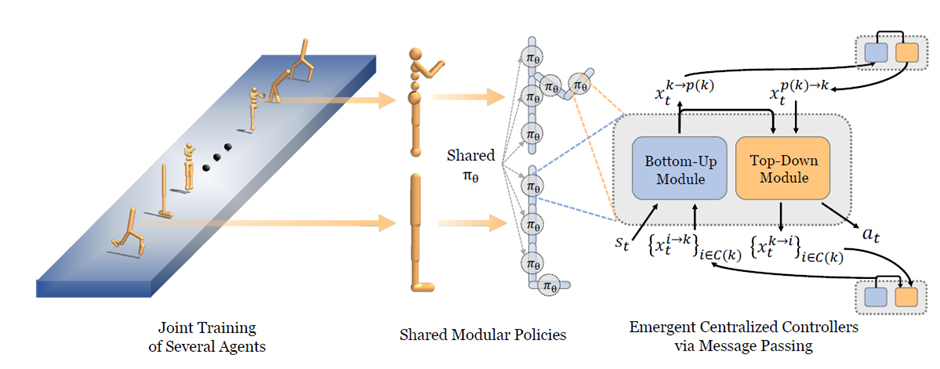
图5. 对特定具有固定形态的机器人,传统强化学习方法训练的是一个特定的策略。但最近的工作,比如本图展现的Huang等人的研究[29],试图训练一个单一的模块神经网络,负责控制机器人的一个部分。因此,每个机器人的全局策略是这些相同的模块化神经网络协调的结果。他们表明,这样的系统可以在各种不同的骨架结构中通用,从跳虫到四足步行类,甚至是一些未见过的形态。
上述研究暗示了具身认知的力量。具身认知强调了智能体的身体在产生行为过程中的作用。虽然深度强化学习的大部分研究重点,是为具有固定设计的智能体(如双足机器人、人形机器人或机械臂)设计神经网络策略,但具身智能在该领域里也在逐渐吸引兴趣[22,44]。受以前自配置模块化机器人的研究[61]的启发,Pathak等人[44]研究了一个原始智能体的集合,这些智能体学着自组装一个复杂的身体,并学习在没有明确的中心化控制单元的情况下,利用局部策略来控制身体(见图6)。每个原始智能体(由一个肢体和一个马达组成)可以连接附近的智能体,这样一来,复杂的形态就可能涌现。他们的研究结果表明,这些动态、模块化的智能体,对条件的变化是稳健的。策略不仅可以泛化到未见过的环境,还可以泛化到由更多模块组成的、未见过的形态。除了适应不断变化的形态与环境,自组织系统还能适应其感官输入的变化。感官替代指的是大脑使用一种感官模态(如触觉)来提供通常由另一种模态(如视觉)收集的环境信息的能力。然而,大多数神经网络并不能适应感官替代。例如,大多数强化学习智能体要求输入必须符合精确的、实现指定的固定格式,否则就会失效。在最近的一项研究中,Tang和Ha[65]探讨了可以不受输入打乱影响的神经网络智能体,要求每个感觉神经元(从环境中接受感官输入的受体)推断其输入信号的意义和背景,而不是明确地假设一个固定的意义(见图7)。他们证明,这些感觉网络可以被训练,来整合局部收到的信息,并且可以通过神经元之间使用注意力机制的交流,来协同产生一个全局一致的策略。此外,即使在一段时间里,该系统的输入顺序被随机改变几次,它仍然可以执行任务。他们的实验表明,这种智能体对包含许多冗余信息或噪声的观测,或者对损坏或不完整的观测,都具有稳健性。图6. 自组织也使得强化学习训练环境中的系统能够在给定任务时进行自配置(自设计)。Pathak等人[44]探讨了这种动态和模块化的智能体,并标明它们不仅可以泛化到未见过的环境,还可以泛化到由额外模块组成的未见过的形态。
图7. Tang和Ha[65]探讨了利用了自组织和注意力特性的强化学习智能体,这种智能体将它们的观测视为一个包含了感官输入的,任意排序的、长度可变的列表。他们将视觉任务(如CarRacing何Atari Pong[4,66])中的输入划分为一个二维网格,并打乱了顺序(左图)。他们还在连续控制任务[18]中,以乱序增加了许多额外的噪音输入通道(右图);智能体必须学会识别哪些输入是有用的。系统中的每个感觉神经元都收到各自的输入流,并通过协调来完成手头的任务。
集体智能可以从几个不同的尺度来看待。动物个体可以被看成是协同工作的器官的集合,而每个器官(包括大脑)可以被看成是协同运作的细胞的集合。在上一节中,我们讨论了几项研究,它们利用集体智慧的力量,将一个单一的强化学习智能体从根本上分解成较小的强化学习智能体的一个集合,协同为一个群体目标工作。但进一步放大时,我们也可以超越生物学来看待人类的智慧,把人类文明当做是解决超过单个人能力的集体智慧。因此,我们可以将多智能体问题视为社会层面的集体智能模型。虽然多智能体强化学习(multi-agent reinforcement learning, MARL)是深度强化学习一个成熟的分支,但提出的大部分学习算法和环境,针对的都是相对较少的智能体[17,41]——通常少于几十个[1,30,52,67]。在竞争性、自博弈的研究中,2个智能体和4个智能体的环境格外常见[2,23,36]。然而,在自然界中观察到的集体智慧(涉及数千到数百万的族群规模),依赖的个体数量远远大于多智能体强化学习通常会研究的。深度强化学习的最新进展已经证明,在复杂的3D模拟环境中,仅用一个GPU,就能模拟成千上万的智能体[25,53]。一个重要的挑战是:如何利用并行计算硬件和分布式计算方面的进展,在更大规模上处理多智能体学习,来达到训练数百万智能体的目的。在本节中,我们将举例说明近期学术界在训练大量在群体环境中互动的智能体方面所做的尝试。Zhang等人[74]开发了一个名为MAgent的平台,这是一个简单的网格世界环境,可以允许数百万的神经网络智能体。他们的重点是可拓展性,而不是关注物理的逼真度或者环境的真实性。他们证明,MAgent可以在一个GPU上承载多达一百万的智能体(2017年)。他们的平台支持智能体群体内部的互动,这不仅有利于研究策略优化的学习算法,更关键的是,能够研究人工智能社会中数百万智能体涌现的社会现象,包括通信语言和社会等级结构。环境可以通过脚本建立,他们已经提供了一些模拟的例子,如捕食者-猎物、战场、对抗性追击,支持能够表现出不同物理行为的、不同种类的神经网络智能体。最近,开发工作已经迁移到PettingZoo[67]多智能体强化学习项目上。图8. MAgent[74]是一套环境,在网格世界中,大量的像素级智能体在战斗或其他竞争场景中互动。与大多数专注于单一智能体或只有少数智能体的强化学习研究平台不同,MAgent旨在为扩展到数百万智能体的强化学习研究提供支持。这个平台的环境现在作为PettingZoo[67]开源库的一部分进行维护,用于多智能体强化学习的研究。
受到大型多人在线角色扮演游戏(Massively Multiplayer Online Role-Playing Games, MMORPGs, 又称MMOs)的启发,Neural MMO[63]出现了,它是一个支持大量人工智能体的人工智能研究环境。这些智能体为了生存,必须竞争有限的资源。因此,该环境能够大规模地模拟多智能体的互动,要求智能体与群体内的其它(同样旨在争夺资源的)智能体一起学习战斗和导航的策略。与大多数多智能体强化学习环境不同的是,该环境允许每个智能体有自己独特的神经网络权重集,这在内存消耗方面是一个技术挑战。该平台早期版本的初步实验结果[62]表明,具有不同神经网络权重的智能体发展了填补不同壁龛的技能,来避免在大量智能体群体中的竞争。截至发稿时,这个项目正在NeurIPS机器学习社区[63]中被积极开发,致力于大规模智能体群体、长时间跨度、开放式任务和模块化游戏系统等方面的研究。为实现这一大规模、多智能体的研究路径,开发者提供了积极的支持、充足的文档,还开发了额外的训练、记录和可视化工具。图9. Neural MMO[63]是一个在程序化生成的虚拟世界中模拟智能体群体的平台,旨在为多智能体研究提供支持,并将其对计算资源的要求限制在一定范围内。用户可以从一组平台提供的游戏系统中选择,为他们具体的研究问题创造环境——平台支持多达一千种智能体、一平方公里的地图以及几千个时间步长。该项目正在积极开发中,有大量的文档和工具,为研究人员提供记录和可视化工具。在发稿时,这个平台即将在2021年的NeurIPS会议上进行演示。
在前面的章节中,我们描述了一些研究,它们给出了解决方案——让独立的神经网络智能体的集合协同工作,来实现共同目标。这些神经网络模型的参数,针对群体的集体表现进行了优化。虽然这些系统已经被证明是稳健的,而且能适应环境的变化,但归根结底,它们还是被强行规定要执行某个特定任务,不能改变。例如,一个被训练成向前移动的系统,在不重新训练的情况下,不能突然执行另一个完全不同的任务,如向上跳跃。为了执行另一个任务,系统必须能够在部署过程中不断地从经验中学习。虽然人们可以简单地时不时暂停系统,手动地通过最新数据重新训练它,但另一种方法是让系统能够自己学习。元学习是深度学习中一个活跃的研究领域,其目标是训练系统的学习能力。传统上,神经网络是通过梯度下降算法或者进化策略来优化其权重参数,以完成一项特定任务。而元学习的目标是训练一个元学习者,或者学习一种学习算法。在这一节中,我们将讨论集体智能体,它们被连接起来学习,而不是连接起来执行一项特定的任务。来自自组织的概念,可以通过扩展构成人工神经网络的基本构建,很自然地应用到训练神经网络的过程中,让它进行元学习。正如我们所知道的,人工神经网络由相同的神经元组成,这些神经元被建模成非线性的激活函数,在网络中通过突触(权重参数)连接,通常用梯度下降等学习算法训练。但人们不难想象,神经元和突触的抽象也可以拓展到静态激活函数和浮点参数之外。事实上,最近的研究[40,42]已经试图将神经网络的每个神经元建模为一个单独的强化学习智能体。用强化学习的术语来说,每个神经元的“观测”是它自己的当前状态,该状态随着信息在网络中的传递而变化,而每个神经元的“动作”,使得每个神经元能够修改它与系统中其它神经元的连接。因此,学习如何学习的问题,被视为一个多智能体的强化学习问题,每个智能体是神经网络中神经元集合的一部分。虽然这种方法很优雅,但上述研究只能够解决玩具问题,不能与现有的学习算法竞争。最近的方法已经不再简单地使用标量权重在神经元之间传输标量信号了。Sandler等人[55]引入了一种新型的广义人工神经网络,其神经元和突触都有多种状态。传统的人工神经网络可以被看做是该框架的一个特例,有两个状态,一个用于激活,另一个用于反向传播规则产生的梯度。在通用的框架中,它们不需要反向传播程序来计算任何梯度,而是依靠一个共享的局部学习规则来更新突触和神经元的状态。这种Hebbian式的双向局部更新规则只需要每个神经元与突触从它们的相邻神经元与突触获取信息,类似元胞自动机。该规则被参数化为一个低维的基因组向量,而且在整个系统中是一致的。他们采用了演化策略或传统的优化技术来元学习这个基因组向量。他们主要的结果是:在训练任务上元学习的更新规则,可以泛化到新的未见过的测试任务。此外,在一些标准的分类任务中,更新规则比基于梯度下降的学习算法更快。Kirsch等人也采取了类似的做法[33],将神经网络的神经元和突触泛化为更高维度的信息传递系统。但在他们的案例里,每个突触被一个具有相同共享参数的循环神经网络(recurrent neural network, RNN)所取代。这些循环神经网络突触是双向的,支配着整个网络的信息流。与Sandler等人的研究[55]一样,这种双向性使得网络既能推理和学习,又能在前向传播模式下运行。这个系统的权重基本上存储于循环神经网络的隐藏状态中,所以通过简单的运行,该系统可以使用错误信号作为反馈来训练自己。由于循环神经网络是通用计算器,他们能够证明,该系统可以编码基于梯度的反向传播算法,通过被训练来简单地模拟反向传播,而不是通过手动设计明确地计算梯度。当然,他们的系统比反向传播要通用得多,因此能够学习比反向传播更有效的新学习算法(见图10)。
图10. Sandler等人[55]和Kirsch等人[33]的最近研究工作,试图泛化人工神经网络的公认概念,使每个神经元可以有多个状态,而不是一个标量值,也使每个突触的功能是双向的,来促进学习和推理。如本图所示,Kirsch等人[33]提出用一个简单的循环神经网络(具有不同的内部隐藏状态)来模拟每个突触,并标明网络可以通过简单地运行循环神经网络单元来训练,而不是使用反向传播。
前述两项工作,在本文写作时才刚刚发表。我们相信,这些分散的局部元学习方法,有可能在未来彻底改变神经网络的使用方式,挑战目前模型训练与模型部署分离的范式。不过,要证明这些方法可以扩展到更大的数据集,我们还有许多工作要做,毕竟这些方法有更大的内存需求(因为系统有大得多的内部状态)。此外,虽然这些算法能够产生比梯度下降更为有效的学习算法,但这种有效性只在学习的早期阶段明显,网络性能也很快就收敛了。而梯度下降虽然效率较低,但在小样本学习时偏差较小,而且可以继续运行更多轮,来完善权重参数,最终产生的网络将取得更高的性能。
到目前为止,我们讨论了已经被纳入深度学习方法中的来自集体智能的方法。它们为基于神经网络的系统打开了许多耐人寻味的大门。但是,正如生物神经网络只是在最初启发了人工神经网络一样,变成一个人工大脑也并不是深度学习的最后结果,至少现在还不是。不过,深度学习为生成性建模和统计分析开发了令人难以置信的强大工具。在生物学中,我们已经看到神经科学家开始采用深度学习的工具,反过来用人工神经网络分析生物神经网络[43]。同样的道理,我们也观察到有些研究开始运用深度学习方法,使我们更好地理解复杂系统。我们偶尔可以发现复杂动力系统的局部规则中因自组织而出现的有趣模式。但对于研究人员和业余爱好者来说,要找到这些模式是一个耗时的过程,这个过程依赖于启发式的方法和对局部规则的初始状态和参数的手动调节。在本节中,我们将讨论一些研究,使用深度学习来分析元胞自动机的丰富涌现行为的复杂模式。Zenil等人的早期研究[72],提出使用压缩来量化一个元胞自动机相变的可预测性。他们表明,基于压缩的方法,可以将Wolfram的规则[70]归入与Wolfram以前研究的启发式行为相对应的群组。这项早期研究表明,如果预测元胞自动机行为的难度被量化,这些数值可以作为研究元胞自动机和其它复杂系统动态特性的更广泛框架的一部分。在最近的一项研究中,Cisneros等人[13]研究了几个衡量复杂系统(如元胞自动机)中涌现模式复杂度增长的指标。他们认为,衡量这种增长的指标,对于设计能展现出开放式演化的系统是很有用的。除了基于压缩的度量,他们还提出使用经过训练的神经网络来预测元胞自动机的行为。在一维和二维网格上,使用基于神经的度量,他们能够自动构建计算模型,有着康威生命游戏中发现的涌现属性[14]。他们的方法可以应用于广泛的复杂系统,不局限于元胞自动机。历史上,元胞自动机受限于只能在离散时间和离散空间中运行的规则。最近,Chan开发了一个名为Lenia的新的人工生命系统[6,7]。这是一个具有连续时空状态的二维元胞自动机,包含可以在连续时空中运行的通用局部更新规则。与离散时间的元胞自动机相比,Lenia的涌现模式更多样,更复杂。作者展现了与现实世界的微观生物相似的、有着复杂多样性的复杂自主模式,并确认了18个科的400多个物种,其中许多是通过一个有人类参与的互动演化计算界面发现的。Lenia在人工生命届很受欢迎,而我们也开始看到一些研究采用机器学习来帮助分析Lenia所能产生的人工生命形式。为了在Lenia中发现更多的生命形式,Reinke等人[51]将内在动机深度学习算法(最初为机器人学中为逆向模型学习而开发)用于自动发现Leniaz等高维复杂动力系统中的各种自组织模式,并将其作为实验和评估的框架。他们在该方法中,把内在动机的目标探索与对目标空间(感兴趣的模式特征空间)的无监督学习结合起来。这里的无监督学习,是使用深度自动编码器进行的。他们的结果表明,使用内在动机算法,在从Lenia学习的无监督表征中搜索新奇的模式,搜索的效率和已经拥有人类专家识别的有趣模式数据库的系统相差不多。后来,Etcheverry等人[16]指出,不依靠用户反馈的自动的多样性驱动的发现系统,有着根本的局限性——因为没有一个“什么是有趣的多样性”的真相(ground truth),它强烈地依赖于最终观察者的主观意见。但与此同时,让用户参与其中就违背了自动发现的目的。为了解决这个问题,他们引入了一个模块化架构,可以对多样性表征的层次进行无监督学习,理论上能够捕捉到各种不同的人类主观偏好,同时仍然采用内在动机的目标探索算法,如Etcheverry等人提出的算法。在Lenia上测试这个方法,得到的是一个类似于助手的系统,只用很少的反馈就能有效地使其多样性搜索适应用户的偏好。图11. 深度学习方法已经被用来在连续的元胞自动机系统(如Lenia[6])中自动发现人工生命体[16,51]。最近的研究[16]不仅能自动发现有趣的模式,而且还能将用户对特定类型的有趣性的偏好纳入其搜索过程。这样,它就可以在Lenia中寻找局部空间里的模式,或类图灵的生命形式。
在这篇综述中,我们首先简要介绍了历史背景,描述了神经网络和集体智能研究相互交织的发展。这两个研究领域的诞生时间大致相同,在历史上的兴衰也存在着一些正相关的关系。这并不是巧合,因为这两个领域中一个的进步和突破,通常可以产生新想法,或为另一个领域补充解决方案。例如,将深度神经网络和相关训练算法引入元胞自动机,我们能够开发出抗噪音和具有“自我修复”特性的图像生成算法。这篇综述探讨了深度学习领域中的几项工作,这几项工作也受到了集体智能领域中一些概念的启发。在宏观层面上,多智能体深度强化学习中的集体智能带来了可以通过集体自对弈来超越人类表现的有趣模型,也带来了去中心化的自组织的机器人控制器;在微观层面上,一些先进的方法也嵌入了集体智能,用深度模型在更细的颗粒度上模拟各个神经元、突触或其它对象。纵观它们各自的发展轨迹,深度学习在开发新型架构和训练算法方面取得了显著的成就,从而实现了高效的学习和更好的性能,而集体智能则更注重问题的表述和机制,以此促进新颖的表现或比简单地聚集各个结果更好的结果。因此,我们有理由认为,这两个领域处于不同的抽象层次,可以互相补充。我们相信,这种携手并进的共同发展将继续下去。有希望的未来发展方向可能包括:将每个单独的神经元或者突触模拟为整个深度神经网络,以及开发能学习群体之间相互作用的算法,来复现真实大脑的行为。此外,集体智能和深度学习的这种结合,也许能使模拟的人工文明反映出我们人类文明的某些方面,蕴含着造就我们集体智能的所有复杂性。
- Baker B, Kanitscheider I, Markov T, Wu Y, Powell G, McGrew B and Mordatch I (2019) Emergent tool use from multi-agent autocurricula. arXiv preprint arXiv:1909.07528 .
- Bansal T, Pachocki J, Sidor S, Sutskever I and Mordatch I (2017) Emergent complexity via multi-agent competition. arXiv preprint arXiv:1710.03748 .
- Bhatia J, Jackson H, Tian Y, Xu J and Matusik W (2021) Evolution gym: A large-scale benchmark for evolving soft robots. In: Advances in Neural Information Processing Systems. Curran Associates, Inc. URL https://sites.google.com/corp/view/evolution-gym-benchmark/.
- Brockman G, Cheung V, Pettersson L, Schneider J, Schulman J, Tang J and Zaremba W (2016) Openai gym. arXiv preprint arXiv:1606.01540 .
- Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A et al. (2020) Language models are few-shot learners. arXiv preprint arXiv:2005.14165 .
- Chan BWC (2019) Lenia: Biology of artificial life. Complex Systems 28(3): 251–286. DOI:10.25088/ complexsystems.28.3.251. URL http://dx.doi.org/10.25088/complexsystems.28.3.251.
- Chan BWC (2020) Lenia and expanded universe. In: Proceedings of the ALIFE 2020: The 2020 Conference on Artificial Life. pp. 221–229. DOI:10.1162/isal a 00297. URL https://doi.org/10.1162/isal_ a_00297.
- Cheney N, MacCurdy R, Clune J and Lipson H (2014) Unshackling evolution: evolving soft robots with multiple materials and a powerful generative encoding. ACM SIGEVOlution 7(1): 11–23.
- Chollet F et al. (2015) keras.
- Chua LO and Roska T (2002) Cellular neural networks and visual computing: foundations and applications. Cambridge university press.
- Chua LO and Yang L (1988) Cellular neural networks: Applications. IEEE Transactions on circuits and systems 35(10): 1273–1290.
- Chua LO and Yang L (1988) Cellular neural networks: Theory. IEEE Transactions on circuits and systems 35(10): 1257–1272.
- Cisneros H, Sivic J and Mikolov T (2019) Evolving structures in complex systems. arXiv preprint arXiv:1911.01086 .
- Conway J et al. (1970) The game of life. Scientific American 223(4): 4.
- Daigavane A, Ravindran B and Aggarwal G (2021) Understanding convolutions on graphs. Distill DOI: 10.23915/distill.00032. Https://distill.pub/2021/understanding-gnns.
- Deng J, Dong W, Socher R, Li LJ, Li K and Fei-Fei L (2009) Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. Ieee, pp. 248–255.
- Etcheverry M, Moulin-Frier C and Oudeyer PY (2020) Hierarchically organized latent modules for exploratory search in morphogenetic systems. In: Advances in Neural Information Processing Systems, volume 33. Curran Associates, Inc., pp. 4846–4859. URL https://proceedings.neurips.cc/paper/2020/file/ 33a5435d4f945aa6154b31a73bab3b73-Paper.pdf.
- Foerster JN, Assael YM, De Freitas N and Whiteson S (2016) Learning to communicate with deep multi-agent reinforcement learning. arXiv preprint arXiv:1605.06676 .
- Freeman CD, Metz L and Ha D (2019) Learning to predict without looking ahead: World models without forward prediction URL https://learningtopredict.github.io.
- Gilpin W (2019) Cellular automata as convolutional neural networks. Physical Review E 100(3): 032402.
- GoraS L, Chua LO and Leenaerts D (1995) Turing patterns in cnns. i. once over lightly. IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications 42(10): 602–611.
- Grattarola D, Livi L and Alippi C (2021) Learning graph cellular automata.
- Ha D (2018) Reinforcement learning for improving agent design URL https://designrl.github.io.
-
Ha D (2020) Slime volleyball gym environment. https://github.com/hardmaru/ slimevolleygym.
- Hamann H (2018) Swarm robotics: A formal approach. Springer.
- He K, Zhang X, Ren S and Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778.
- Heiden E, Millard D, Coumans E, Sheng Y and Sukhatme GS (2021) NeuralSim: Augmenting differentiable simulators with neural networks. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). URL https://github.com/google-research/ tiny-differentiable-simulator.
- Hill A, Raffin A, Ernestus M, Gleave A, Kanervisto A, Traore R, Dhariwal P, Hesse C, Klimov O, Nichol A et al. (2018) Stable baselines.
- Hooker S (2020) The hardware lottery. arXiv preprint arXiv:2009.06489 URL https:// hardwarelottery.github.io/.
- Horibe K, Walker K and Risi S (2021) Regenerating soft robots through neural cellular automata. In: EuroGP. pp. 36–50.
- Huang W, Mordatch I and Pathak D (2020) One policy to control them all: Shared modular policies for agentagnostic control. In: International Conference on Machine Learning. PMLR, pp. 4455–4464.
- Jaderberg M, Czarnecki WM, Dunning I, Marris L, Lever G, Castaneda AG, Beattie C, Rabinowitz NC, Morcos AS, Ruderman A et al. (2019) Human-level performance in 3d multiplayer games with populationbased reinforcement learning. Science 364(6443): 859–865.
- Joachimczak M, Suzuki R and Arita T (2016) Artificial metamorphosis: Evolutionary design of transforming, soft-bodied robots. Artificial life 22(3): 271–298.
- Jumper J, Evans R, Pritzel A, Green T, Figurnov M, Ronneberger O, Tunyasuvunakool K, Bates R, Zˇ´ıdek A, Potapenko A et al. (2021) Highly accurate protein structure prediction with alphafold. Nature 596(7873): 583– 589.
- Kirsch L and Schmidhuber J (2020) Meta learning backpropagation and improving it. arXiv preprint arXiv:2012.14905 .
- Kozek T, Roska T and Chua LO (1993) Genetic algorithm for cnn template learning. IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications 40(6): 392–402.
- Krizhevsky A, Sutskever I and Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 25: 1097–1105.
- Liu S, Lever G, Merel J, Tunyasuvunakool S, Heess N and Graepel T (2019) Emergent coordination through competition. arXiv preprint arXiv:1902.07151 .
- Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G et al. (2015) Human-level control through deep reinforcement learning. nature 518(7540): 529–533.
- Mordvintsev A, Randazzo E, Niklasson E and Levin M (2020) Growing neural cellular automata. Distill DOI: 10.23915/distill.00023. URL https://distill.pub/2020/growing-ca.
- Nagy Z, Voroshazi Z and Szolgay P (2006) A real-time mammalian retina model implementation on fpga. In: 2006 10th International Workshop on Cellular Neural Networks and Their Applications. IEEE, pp. 1–1.
- Ohsawa S, Akuzawa K, Matsushima T, Bezerra G, Iwasawa Y, Kajino H, Takenaka S and Matsuo Y (2018) Neuron as an agent. URL https://openreview.net/forum?id=BkfEzz-0-.
- OroojlooyJadid A and Hajinezhad D (2019) A review of cooperative multi-agent deep reinforcement learning. arXiv preprint arXiv:1908.03963 .
- Ott J (2020) Giving up control: Neurons as reinforcement learning agents. arXiv preprint arXiv:2003.11642 .
- Pandarinath C, O’Shea DJ, Collins J, Jozefowicz R, Stavisky SD, Kao JC, Trautmann EM, Kaufman MT, Ryu SI, Hochberg LR et al. (2018) Inferring single-trial neural population dynamics using sequential auto-encoders. Nature methods 15(10): 805–815.
- Pathak D, Lu C, Darrell T, Isola P and Efros AA (2019) Learning to control self-assembling morphologies: a study of generalization via modularity. arXiv preprint arXiv:1902.05546 .
- Peng Z, Hui KM, Liu C, Zhou B et al. (2021) Learning to simulate self-driven particles system with coordinated policy optimization. Advances in Neural Information Processing Systems 34.
- Qin Y, Feng M, Lu H and Cottrell GW (2018) Hierarchical cellular automata for visual saliency. International Journal of Computer Vision 126(7): 751–770.
- Qu X, Sun Z, Ong YS, Gupta A and Wei P (2020) Minimalistic attacks: How little it takes to fool deep reinforcement learning policies. IEEE Transactions on Cognitive and Developmental Systems .
- Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J et al. (2021) Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020 .
- Radford A, Narasimhan K, Salimans T and Sutskever I (2018) Improving language understanding by generative pre-training .
- Radford A, Wu J, Child R, Luan D, Amodei D, Sutskever I et al. (2019) Language models are unsupervised multitask learners. OpenAI blog 1(8): 9.
- Randazzo E, Mordvintsev A, Niklasson E, Levin M and Greydanus S (2020) Self-classifying mnist digits. Distill DOI:10.23915/distill.00027.002. URL https://distill.pub/2020/selforg/mnist.
- Reinke C, Etcheverry M and Oudeyer PY (2020) Intrinsically motivated discovery of diverse patterns in self-organizing systems. In: International Conference on Learning Representations. URL https:// openreview.net/forum?id=rkg6sJHYDr.
- Resnick C, Eldridge W, Ha D, Britz D, Foerster J, Togelius J, Cho K and Bruna J (2018) Pommerman: A multi-agent playground. arXiv preprint arXiv:1809.07124 .
-
Rolnick D, Donti PL, Kaack LH, Kochanski K, Lacoste A, Sankaran K, Ross AS, Milojevic-Dupont N, Jaques N, Waldman-Brown A et al. (2019) Tackling climate change with machine learning. arXiv preprint arXiv:1906.05433 .
- Rubenstein M, Cornejo A and Nagpal R (2014) Programmable self-assembly in a thousand-robot swarm. Science 345(6198): 795–799.
- Rudin N, Hoeller D, Reist P and Hutter M (2021) Learning to walk in minutes using massively parallel deep reinforcement learning. arXiv preprint arXiv:2109.11978 .
- Sanchez-Lengeling B, Reif E, Pearce A and Wiltschko AB (2021) A gentle introduction to graph neural networks. Distill 6(9): e33.
- Sandler M, Vladymyrov M, Zhmoginov A, Miller N, Madams T, Jackson A and Arcas BAY (2021) Metalearning bidirectional update rules. In: International Conference on Machine Learning. PMLR, pp. 9288–9300
- Sandler M, Zhmoginov A, Luo L, Mordvintsev A, Randazzo E et al. (2020) Image segmentation via cellular automata. arXiv preprint arXiv:2008.04965 .
- Schmidhuber J (2014) Who invented backpropagation? More[DL2] .
- Schoenholz S and Cubuk ED (2020) Jax md: a framework for differentiable physics. Advances in Neural Information Processing Systems 33.
- Senior AW, Evans R, Jumper J, Kirkpatrick J, Sifre L, Green T, Qin C, Zˇ´ıdek A, Nelson AW, Bridgland A et al. (2020) Improved protein structure prediction using potentials from deep learning. Nature 577(7792): 706–710.
- Silver D, Huang A, Maddison CJ, Guez A, Sifre L, Van Den Driessche G, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M et al. (2016) Mastering the game of go with deep neural networks and tree search. nature 529(7587): 484–489.
- Simonyan K and Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 .
- Stoy K, Brandt D, Christensen DJ and Brandt D (2010) Self-reconfigurable robots: an introduction .
- Suarez J, Du Y, Isola P and Mordatch I (2019) Neural mmo: A massively multiagent game environment for training and evaluating intelligent agents. arXiv preprint arXiv:1903.00784 .
- Suarez J, Du Y, Zhu C, Mordatch I and Isola P (2021) The neural mmo platform for massively multiagent research. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track. URL https://openreview.net/forum?id=J0d-I8yFtP.
- Sudhakaran S, Grbic D, Li S, Katona A, Najarro E, Glanois C and Risi S (2021) Growing 3d artefacts and functional machines with neural cellular automata. arXiv preprint arXiv:2103.08737 .
- Tang Y and Ha D (2021) The sensory neuron as a transformer: Permutation-invariant neural networks for reinforcement learning. In: Thirty-Fifth Conference on Neural Information Processing Systems. URL https: //openreview.net/forum?id=wtLW-Amuds. https://attentionneuron.github.io.
- Tang Y, Nguyen D and Ha D (2020) Neuroevolution of self-interpretable agents. In: Proceedings of the Genetic and Evolutionary Computation Conference. URL https://attentionagent.github.io.
- Terry JK, Black B, Jayakumar M, Hari A, Sullivan R, Santos L, Dieffendahl C, Williams NL, Lokesh Y, Horsch C et al. (2020) Pettingzoo: Gym for multi-agent reinforcement learning. arXiv preprint arXiv:2009.14471 .
- Vinyals O, Babuschkin I, Czarnecki WM, Mathieu M, Dudzik A, Chung J, Choi DH, Powell R, Ewalds T, Georgiev P et al. (2019) Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature 575(7782): 350–354.
- Wang T, Liao R, Ba J and Fidler S (2018) Nervenet: Learning structured policy with graph neural networks. In: International Conference on Learning Representations.
- Wolfram S (2002) A new kind of science, volume 5. Wolfram media Champaign, IL.
- Wu Z, Pan S, Chen F, Long G, Zhang C and Philip SY (2020) A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems 32(1): 4–24.
- Zenil H (2009) Compression-based investigation of the dynamical properties of cellular automata and other systems. arXiv preprint arXiv:0910.4042 .
- Zhang D, Choi C, Kim J and Kim YM (2021) Learning to generate 3d shapes with generative cellular automata. In: International Conference on Learning Representations. URL https://openreview.net/forum? id=rABUmU3ulQh.
- Zheng L, Yang J, Cai H, Zhou M, Zhang W, Wang J and Yu Y (2018) Magent: A many-agent reinforcement learning platform for artificial collective intelligence. In: Proceedings of the AAAI Conference on Artificial Intelligence, volume 32
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

点击“阅读原文”,追踪复杂科学顶刊论文








