爬虫俱乐部之前推出的线下培训,得到了各位老师的一致好评。为了更加方便大家学习,满足更多Stata用户的学习需求,爬虫俱乐部已隆重推出在线直播课程,请大家奔走相告!课程报名链接:https://ke.qq.com/course/286526#tuin=9735fd2d,详情见推文《爬虫俱乐部隆重推出网上直播课程第一季》
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
喜大普奔~爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io,粉丝们可以通过该网站访问过去的推文哟~
好消息:爬虫俱乐部即将推出研究助理供需平台,如果您需要招聘研究助理(Research Assistant or Research Associate),可以将您的需求通过我们的公众号发布;如果您想成为一个RA,可以将您的简历发给我们,进入我们的研究助理数据库。帮我们写优质的推文可以提升您被知名教授雇用的胜算呀!
编者按:不积跬步无以至千里,复杂的程序总是从简单的细枝末节做起,对学习python更是这样,爬虫俱乐部将甄选一批有吸引力,有启发性的小项目,通过案例的方式介绍知识,制作成推文分享给大家,同时更欢迎大家针对python标准库、第三方库的有趣案例向我们投稿。今天我们推送的是一个爬取豆瓣电影评论并生成词云图的项目,它涉及了比较多的著名第三方库,文中也进行了简单介绍,在随后的推文中我们会更加详细地涉及。
项目目标:给出豆瓣电影的某一电影的ID,即可爬取电影的评论内容,并以此生成词云图。
一、 分析页面,获取单页评论
二、 获取多页评论
三、 进行分词
四、 生成词云图
我们大体上分为三个功能块:
1.获取单页评论(onepage()函数)
2.获取多页评论(parsepage()函数)
3.生成图片(main()函数)
在本篇推文中,我们将介绍到获取单页评论部分,熟悉相关第三方库的简单方法。
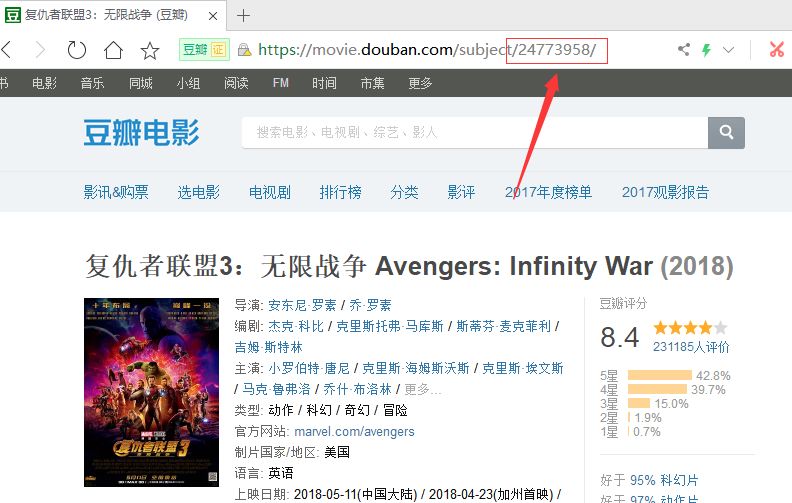
我们打开豆瓣电影的网站,选择一部电影,这里以复仇者联盟3为例。
点击进入影片详细页面,我们可以发现如下部分:
URL地址后面的那串数字就是电影的id号。如图:
继续向下滑动页面,我们可以发现如下部分:
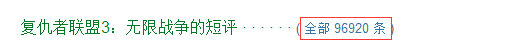
点击查看全部评论。这样我们就进入到评论页面。
默认评论页每页显示20条评论,多翻几页,可以发现一个规律
第一页:https://movie.douban.com/subject/24773958/comments
第二页:https://movie.douban.com/subject/24773958/comments?start=20&limit=20&sort=new_score&status=P&percent_type=
第三页:https://movie.douban.com/subject/24773958/comments?start=40&limit=20&sort=new_score&status=P&percent_type=
我们发现,每一页评论的url地址只有一个地方在变动,就是start=后面的数字,而且是以20的倍数增加,如果我们仔细数一下,就知道这个20代表的是每一页评论的开始是所有评论中的第几条,也就是评论的序号,后面的limit=20是代表每一页显示20条评论。
第一页没有后面的参数,我们可以为了方便自己加上(也就是start=0):
为了整齐,limit=20后面的部分可以不要,最终我们的url地址就变成这样:
https://movie.douban.com/subject/24773958/comments?start=0&limit=20
红色0是我们需要作出改变的地方(每次加上20)。
我们先来看如何获取我们需要的网页:
在这里我们一定要先介绍一个Python第三方库:requests库。简单来说requests库就是为了能够从网络中获取网页内容的工具。
这里是官方网站:http://cn.python-requests.org/zh_CN/latest/
你可以在这里学习到requests更多的方法。有中文哦。
我们看一个例子:
get方法返回的就是包含了网页所有信息的对象,我们可以通过r.text将网页内容取出来。
import requests r =requests.get("https://movie.douban.com/subject/24773958/comments?start=0&limit=20") html = r.text
print(html)
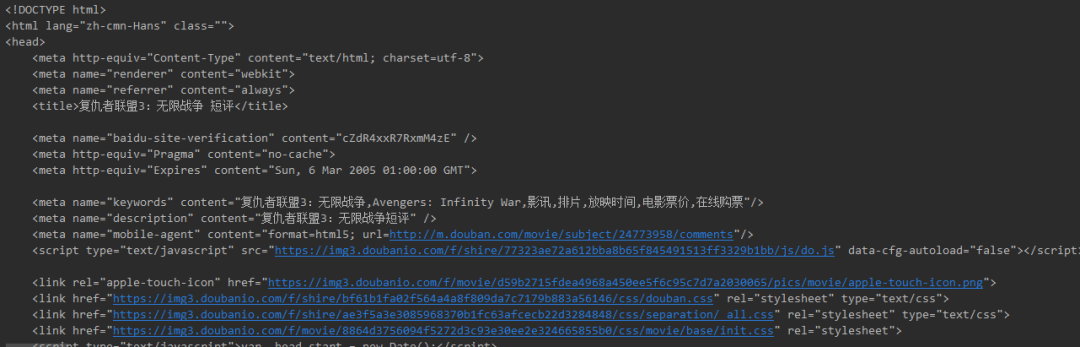
执行上面这几行代码,我们就得到了网页的源代码:如下图
接下来我们需要分析如何在网页中找到我们需要的评论内容。
这里再介绍一个Python第三方库:BeautifulSoup库。
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够将网页代码解析成一个由html标签构筑的标签树对象,并提供了丰富的方法让使用者从这个标签树中获取需要的信息。
这里是官方网站:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
你可以通过这里的手册快速对BeautifulSoup库有个基本的了解。
我们可以通过pip方式进行安装:
在cmd命令行输入:pip install BeautifulSoup4
安装好之后就可以导入直接使用了。
我们使用from关键字进行导入:from bs4 import BeautifulSoup
每一个网页都是由不同的html标签构成的,比如段落就是p标签,他们成对出现,比如:
这里就是段落内容
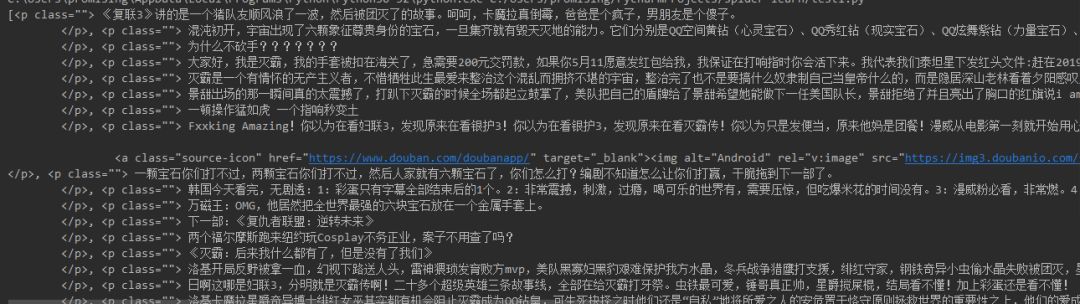
。而标签和标签之间是可以嵌套的,也就是说可以一层包含一层的。所以,想得到里面的内容就需要先找到这个标签。通过查看网页源代码可以发现,每个页面中的评论列表都在一个class=”mod-bd”,id=”comments”的div标签里,而每个评论者的评论内容都在该标签下的class=”” 的p标签内,如下所示
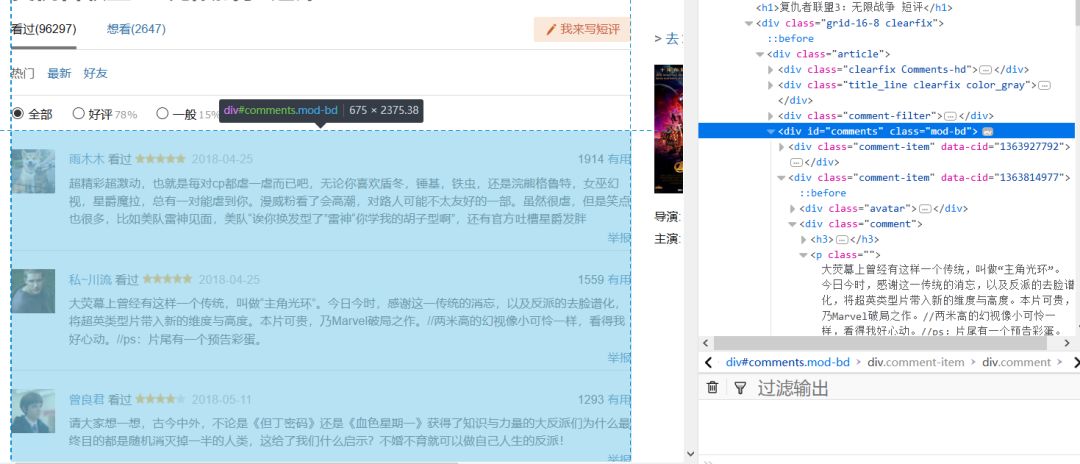
因此我们先要找到class=”mod-bd”的div标签
我们通过BeautifulSoup库可以很方便的找到这部分:
首先我们要通过BeautifulSoup将我们获取的网页内容转化成对象,并通过html.parser进行解析:
soup = BeautifulSoup(html, "html.parser")
comments_sec = soup.find("div", "mod-bd")
这样我们就取到了div标签。
然后通过find_all()方法找到div内所有的class=“”的p标签,
comments_list = comments_sec.find_all("p", "")
print(comments_list)
我们可以将其打印出来,是一个列表,里面包含的就是每个评论的p标签
列表是Python中的一种数据类型,里面可以存储多个数据,可以是数字、字符串以及其他类型。
那么我们如何将文本内容取出来呢?
那就是for循环。
通过循环将每个单独的评论内容写入comments列表。
先声明一个空列表lst用于存储评论内容,然后通过for循环将每个评论写入到lst里面。
Text属性取得纯文本而不包括标签,再通过strip方法将空格换行等字符去除。
lst = []
for i in range(len(comments_list)):
lst.append(comments_list[i].text.strip())
print(lst)
得到的就是一个列表,包含了所有评论。

以上就返回了一页评论,将其封装成一个函数onepage(),传入参数是url,这样就有利于重复使用。
def onepage(url):
r = requests.get(url)
r.encoding = "utf-8"
html = r.text
soup = BeautifulSoup(html, "html.parser")
comments_sec = soup.find("div", "mod-bd")
comments_list = comments_sec.find_all("p", "")
lst = []
for i in range(len(comments_list)):
lst.append(comments_list[i].text.strip())
return lst
在这篇推文中,我们提到了如何获取单页评论,并熟悉了相关库的使用方法,在后面的推文《Python 爬取豆瓣电影评论并生成词云图(二)》中,我们将介绍获取多页评论、分词以及生成词云图,敬请期待!









