

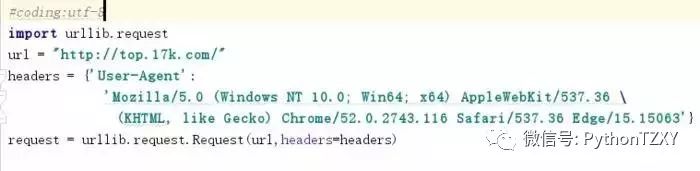
然后再将请求发送出去,定义变量response,用read()方法观察,注意将符号解码成utf-8的形式,省的乱码:
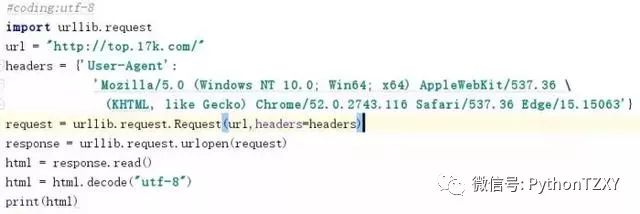
打印一下看结果:

看到这么一大条就对喽,对比一下网页源码,发现是一致的。


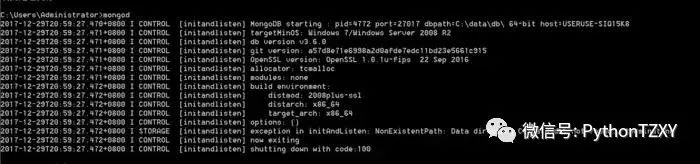
失败状态
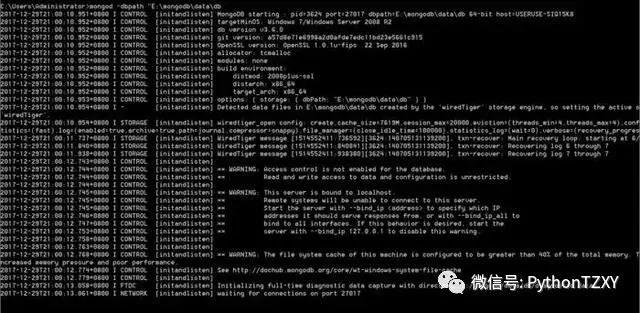
成功状态
添加路径后成功连接,出现waiting for connections on port 27017,则表示数据库连接成功,而后就不要关掉这个终端了,只有保持数据库是连接的,才可运行MongoDB数据库(不然报错你都不知道自己是怎么死的)
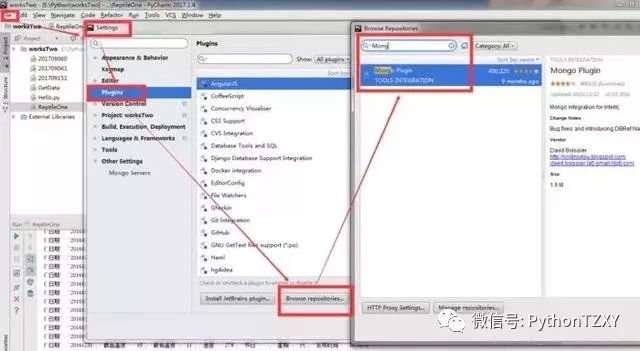
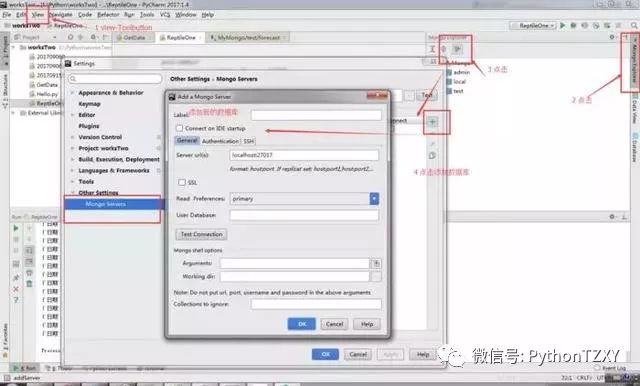
好了,连接好数据库后,我们将数据库与编辑器进行交互链接,位置很隐秘,在File>>Settings>>Plugins下添加组件Mongo Plugin,没有就下载一个:

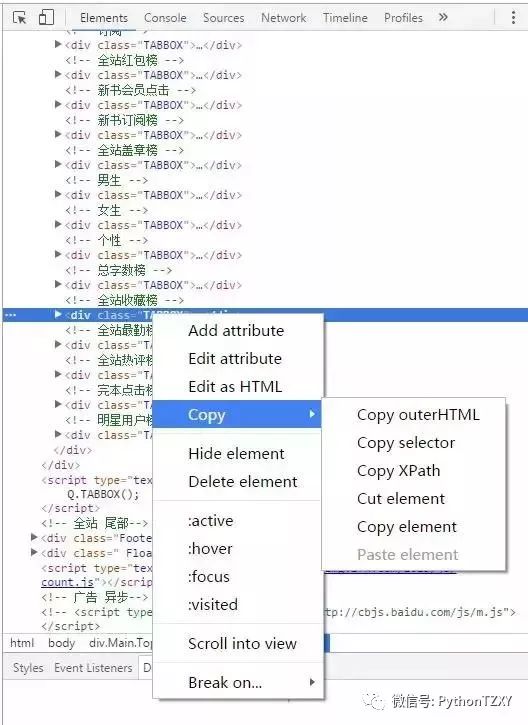
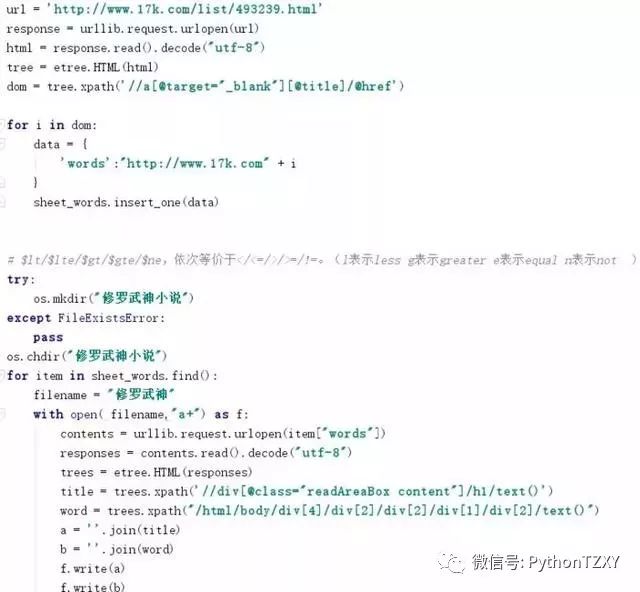
如果你决定使用xpath之后,我们需要从lxml中引入etree模块,然后就可以用etree中的HTML()方法来解析网页了,从网页>检察元素(F12)中复制下来我们所需数据的路径,我选择的是小说每章的标题和内容,上图,上图:
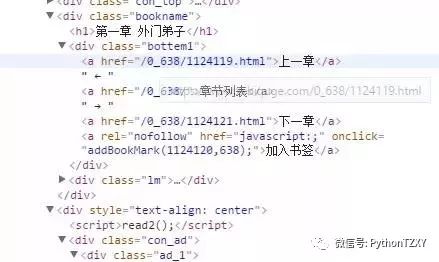
路径//div[@class="readAreaBox content"]/h1/text()
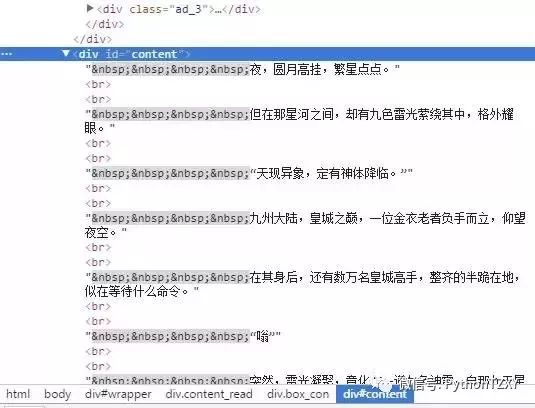
路径/html/body/div[4]/div[2]/div[2]/div[1]/div[2]/text()
注意注意,又来一个坑,当你复制xpath时得到的是这个东东:
//div[@class="readAreaBox content"]/h1
和这个东东;
/html/body/div[4]/div[2]/div[2]/div[1]/div[2]
但你需要的是这个路径里的文本text,故我们需要另外添加具体文本:/text(),然后就像上面那样啦。上代码,查数据:
完整代码见百度网盘:私信小编02即可获取云盘地址
小说有点大,一共是三千五百章,等个大约4-7分钟吧,打开文件夹《修罗武神小说》,就可以看到我们下载好的无需翻页的一整部小说,数据库内页备份好了每章的链接,它自动从零开始排的,就是说你要看第30章就得打开序号为29的链接,这个调一下下载时的顺序就好了,作者很懒,想要尝试下的读者可以自行更改。

小说文本

数据库连接
看看,感觉还不错吧,好的小例子讲完了,接下来我们准备进入正题。

Scrapy插件安装成功
然后还是老规矩,不想每次终端运行都一点一点找路径的话,就将根目录添加到环境变量,然后打开终端,我们测试一下是否安装成功:
Scrapy安装成功
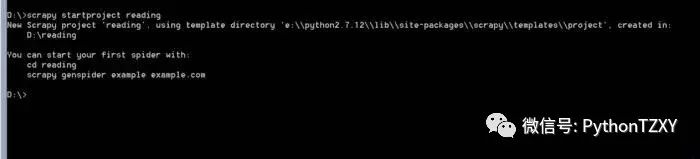
好,安装完毕后,打开终端,新建一个Scrapy工程,这里你可以根据索引,选择使用Scrapy的各种功能,这里不一一详解了,D盘内已经出现了我们建立好的Scrapy工程文件夹:
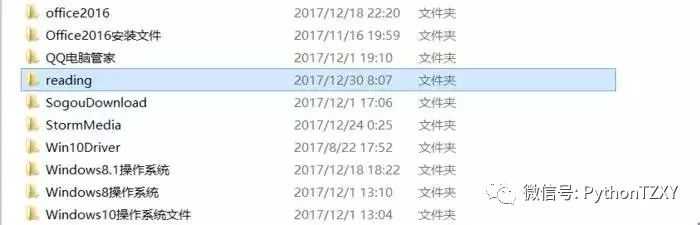
打开文件夹,我们会看到Scrapy框架已经自动在reading文件夹中放置了我们所需的一切原材料:

打开内部reading文件夹,就可以在spiders文件夹中添加爬虫py代码文件了:
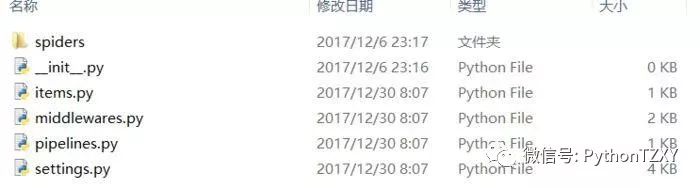
我们这里定向爬小说排行榜,除了我们写的spider文件,还要在items.py中定义我们要爬取的内容集,有点像词典一样,名字可以随便取,但已有的继承类scrapy.Item可不能改,这是Scrapy内部自定义的类,改了它可找不到,spider就用我们上面抓取单本再加一个for循环就OK了,十分简单,一言不合就上图:

爬虫文件截图

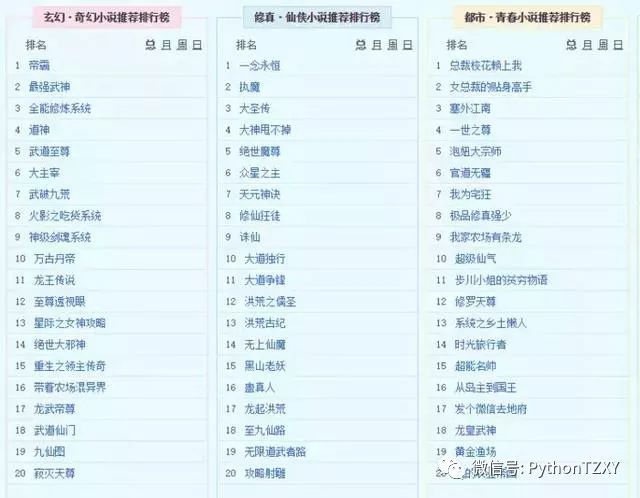
爬取的小说排行榜
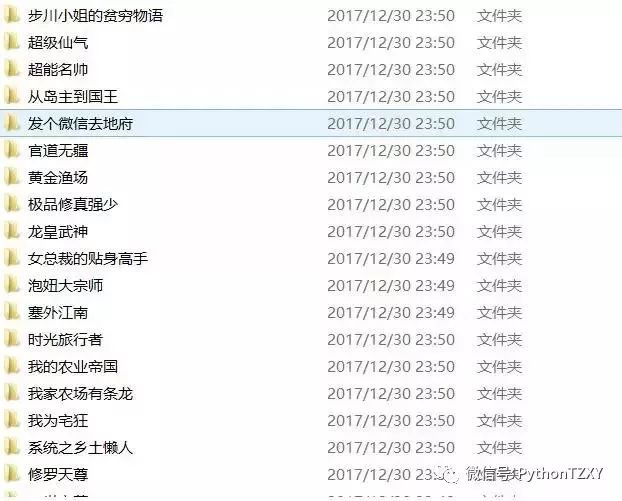
每个排行榜上大约20本小说
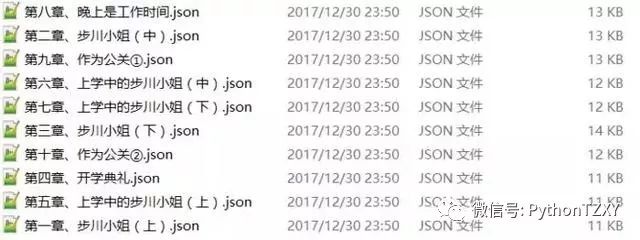
每部小说的爬取情况(用的是.json格式)

私信小编02即可获取源码哦!










