原标题 | An Easy Introduction to Generative Adversarial Networks in Deep Learning本文转载自新机器视觉,文章仅用于学术分享。
生成对抗网络(GANs,https://en.wikipedia.org/wiki/Generative_adversarial_network)是一类具有基于网络本身即可以生成数据能力的神经网络结构。由于GANs的强大能力,在深度学习领域里对它们的研究是一个非常热门的话题。在过去很短的几年里,它们已经从产生模糊数字成长到创造如真实人像般逼真的图像。


1 GAN的工作方式
GANs属于生成模型的一类(https://en.wikipedia.org/wiki/Generative_model)。这意味着它们能够产生,或者说是生成完全新的“有效”数据。有效数据是指网络的输出结果应该是我们认为可以接受的目标。
举例说明,举一个我们希望为训练一个图像分类网络生成一些新图像的例子。当然对于这样的应用来说,我们希望训练图像越真实越好,可能在风格上与其他图像分类训练数据非常相似。
下面的图片展示的例子是GANs已经生成的一系列图片。它们看起来非常真实!如果没人告诉我们它们是计算机生成的,我们真可能认为它们是人工搜集的。

渐进式GAN生成的图像示例(图源:https://arxiv.org/pdf/1710.10196.pdf)
为了做到这些,GANs是以两个独立的对抗网络组成:生成器和判别器。当仅将嘈杂的图像阵列作为输入时,会对生成器进行训练以创建逼真的图像。判别器经过训练可以对图像是否真实进行分类。
GANs真正的能力来源于它们遵循的对抗训练模式。生成器的权重是基于判别器的损失所学习到的。因此,生成器被它生成的图像所推动着进行训练,很难知道生成的图像是真的还是假的。同时,生成的图像看起来越来越真实,判别器在分辨图像真实与否的能力变得越来越强,无论图像用肉眼看起来多么的相似。
从技术的角度来看,判别器的损失即是分类图像是真是假的错误值;我们正在测量它区分真假图像的能力。生成器的损失将取决于它在用假图像“愚弄”判别器的能力,即判别器仅对假图像的分类错误,因为生成器希望该值越高越好。
因此,GANs建立了一种反馈回路,其中生成器帮助训练判别器,而判别器又帮助训练生成器。它们同时变得更强。下面的图表有助于说明这一点。
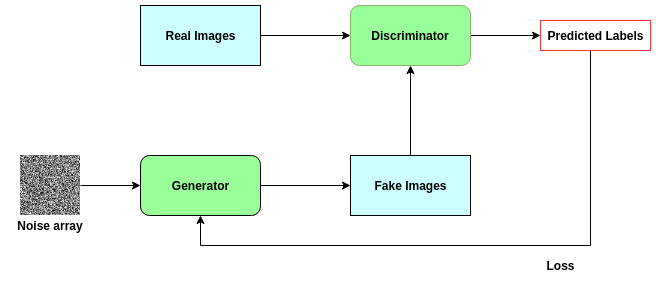
生成对抗网络的结构说明
2 在PyTorch中训练GAN来生成数字
现在我们将通过一个例子来展示如何使用PyTorch建立和训练我们自己的GAN!MNIST数据集包含60000个训练数据,数据是像素尺寸28x28的1-9的黑白数字图片。这个数据集非常适合我们的用例,同时也是非常普遍的用于机器学习的概念验证以及一个非常完备的集合。

MNIST 数据部分集,图源:https://www.researchgate.net/figure/A-subset-of-the-MNIST-database-of-handwritten-digits_fig4_232650721
我们将从 import 开始,所需的仅仅是PyTorch中的东西。
import torch from torch import nn, optim from torch.autograd.variable import Variable
import torchvision import torchvision.transforms as transforms
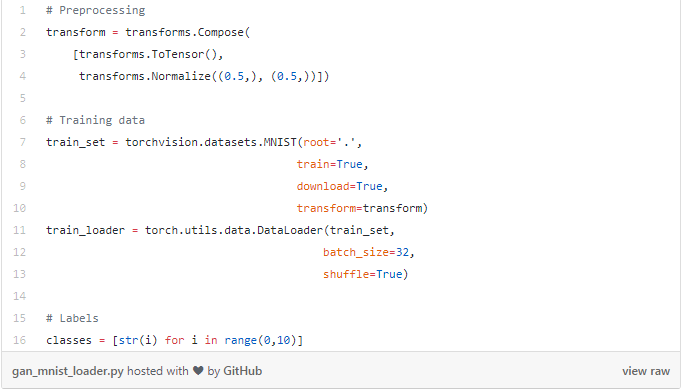
接下来,我们为训练数据准备DataLoader。请记住,我们想要的是为MNIST生成随机数字,即从0到9。因此,我也将需要为这10个数字建立标签。
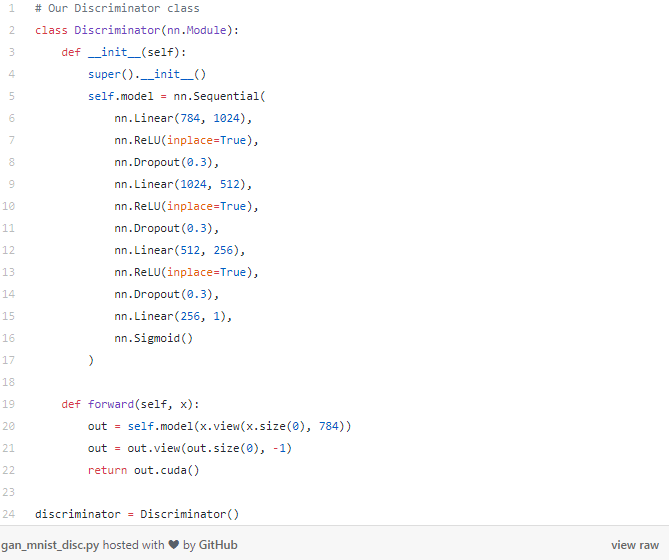
现在我们可以开始建立网络了,从下面的Discriminator(判别器)网络开始,回想一下,判别器网络是对图像真实与否进行分类——它是一个图像分类网络。因此,我们的输入是符合标准MNIST大小的图像:28x28像素。我们把这张图像展平成一个长度为784的向量。输出是一个单独的值,表示图像是否是实际的MNIST数字。
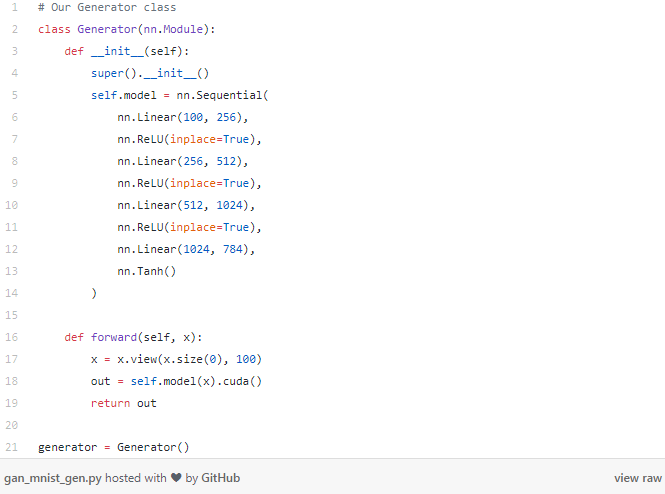
接下来到了生成器部分。生成器网络负责创建实际的图像——它可以从一个纯噪声的输入做到这一点!在这个例子中,我们要让生成器从一个长度为100的向量开始——注意:这只是纯随机噪声。从这个向量,我们的生成器将输出一个长度为784的向量,稍后我们可以将其重塑为标准MNIST的28x28像素。
如果我们希望网络在GPU上执行,PyTorch要求我们必须明确地把模型移动到GPU上。这部分所有的代码如下所示。现在开始训练循环。PyTorch中的训练循环通常由一个遍历各个训练周期的外部循环和一个遍历batch数据的内部循环组成。训练GAN的关键是我们需要在一个循环中更新生成器和判别器。查看下面的代码来训练GAN和PyTorch。这些步骤在代码下面有更详细的描述。(1)我们首先为判别器准备 *real* 图像数据。输入的是一批真实的MNIST图像。输出全为1的向量,因为1表示图像是真实的。(2)接下来,我们将为生成器准备输入向量以便生成假图像。回想一下,我们的生成器网络采用长度为100的输入向量,这就是我们在这里所创建的向量。images.size(0)用于批处理大小。
(3)通过从步骤(2)中创建的随机噪声数据向量,我们可以绕过这个向量到生成器来生成假的图像数据。这将结合我们从步骤1的实际数据来训练判别器。请注意,这次我们的标签向量全为0,因为0代表假图像的类标签。
(4)通过假的和真的图像以及它们的标签,我们可以训练我们的判别器进行分类。总损失将是假图像的损失+真图像的损失。
(5)现在我们的判别器已经更新,我们可以用它来进行预测。这些预测的损失将通过生成器反向传播,这样生成器的权重将根据它欺骗判别器的程度进行具体更新
(5a)生成一些假图像进行预测
(5b)使用判别器对假图像进行分批次预测并保存输出。
(6)使用判别器的预测训练生成器。注意,我们使用全为1的 _real_labels_ 作为目标,因为我们的生成器的目标是创建看起来真实的图像并且预测为1!因此,生成器的损失为0将意味着判别器预测全为1.
瞧,这就是我们训练GAN生成MNIST图像的全部代码!只需要安装PyTorch即可运行。下面的gif就是经过超过40个训练周期生成的图像。


* via https://towardsdatascience.com/an-easy-introduction-to-generative-adversarial-networks-6f8498dc4bcd
* 封面图来源:https://pixabay.com/images/id-3357642/
独家重磅课程官网:cvlife.net
1、SLAM社区:一个人啃SLAM,难受到自闭,硬顶还是放弃?
2、C++实战:为啥SLAM代码都用C++不用Python?
3、多传感器融合SLAM 激光雷达-视觉-IMU多传感器融合方案!
4、VIO灭霸:VIO天花板ORB-SLAM3第2期上线!(单/双目/RGBD+鱼眼+IMU+多地图+闭环)
5、视觉SLAM基础:刚看完《视觉SLAM十四讲》,下一步该硬扛哪个SLAM框架 ?
6、机器人导航运动规划: 机器人核心技术运动规划:让机器人想去哪就去哪!
7、详解Cartographer:谷歌开源的激光SLAM算法Cartographer为什么这么牛X?
8、深度学习三维重建 总共60讲全部上线!详解深度学习三维重建网络
9、三维视觉基础 详解视觉深度估计算法(单/双目/RGB-D+特征匹配+极线矫正+代码实战)
10、 VINS:Mono+Fusion SLAM面试官:看你简历上写精通VINS,麻烦现场手推一下预积分!
11、图像三维重建课程:
视觉几何三维重建教程(第2期):稠密重建,曲面重建,点云融合,纹理贴图
12、系统全面的相机标定课程:单目/鱼眼/双目/阵列 相机标定:原理与实战

全国最棒的SLAM、三维视觉学习社区↓

技术交流微信群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群,请添加微信号 chichui502 或扫描下方加群,备注:”名字/昵称+学校/公司+研究方向“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

— 版权声明 —
本公众号原创内容版权属计算机视觉life所有;从公开渠道收集、整理及授权转载的非原创文字、图片和音视频资料,版权属原作者。如果侵权,请联系我们,会及时删除。







