本文基于研究论文《DeepDPM: 未知聚类数的深度聚类》(DeepDPM: Deep Clustering With an Unknown Number of Clusters)。这份研究的全部贡献都归功于该论文的研究者。
聚类是一种在海量数据集中对相关数据点进行发现与分组的无监督机器学习技术。它把数据组织起来,使其更易于理解和可操作。
深度聚类框架将特征提取、降维和聚类结合到单个端到端模型中,使深度神经网络能够根据模型的假定和标准来学习适当的表示。
深度聚类是参数化的,也就是说,像其他聚类算法一样,需要事先定义好的聚类或类数。但是,由于 DNN 的设计比较复杂,所以要确定一个理想的聚类数量,需要很高的计算成本。
本文概要介绍一种名为 DeepDPM 的新方法,它是由坐落以色列贝尔谢巴的本·古里安大学(Ben-Gurion University of Negev)的研究小组在他们最近的论文中提出的,该论文题目为《未知聚类数的深度聚类》(Deep Clustering With an Unknown Number of Clusters)。DeepDPM 是一种强大的深度非参数技术,它消除了在聚类任务中预先定义聚类数量的要求,而是推断聚类数量。所提出的技术实现了 SOTA 的结果,同时与著名的参数化方法相似,并优于使用传统和深度方法的现有非参数化方法。
DeepDPM 是一种允许用户在训练期间推断和改变聚类数量的方法。它分为两个部分:
为了使 DeepDPM 更具弹性和效率,借鉴贝叶斯 - 高斯混合模型(EM-GMM)的期望最大化过程,它提出了一种新的损失函数。
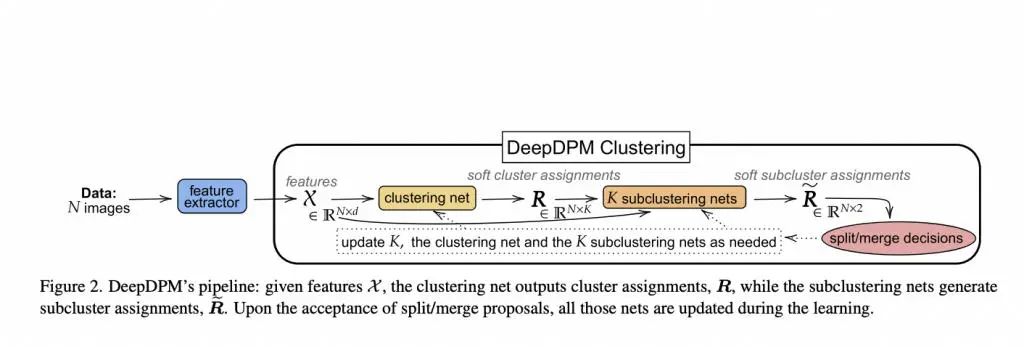
来源:https://arxiv.org/pdf/2203.14309.pdf
在不同规模的常用图像和文本数据集上,研究人员将 DeepDPM 与传统参数化、经典非参数化和深度非参数化方法等进行了对比。通过对这些方法的对比,结果显示,DeepDPM 在所有数据集上几乎都获得了最大的性能,接近 SOTA 水平。DeepDPM 对类不平衡和初始聚类值也有弹性。它可以大大降低资源利用率,消除了不断训读用于模型选择的深度参数技术的需要。
除了一些优势之外, DeepDPM 也像大部分的聚类算法那样,在输入特征很弱的情况下,将会无法恢复。另外,参数化的方法,比如 SCAN,在知晓参数的数字,并且数据集是平衡的,也可能是一个更好的选择。
研究人员表示,将 DeepDPM 应用到流数据或者分层情况的环境中,将会是一项很有意义的工作。另外,还会在更加复杂的框架内改进所获得的成果。
这个团队希望,他们的工作可以激发更多从事深度聚类的人们对非参数技术进行深入的研究。
论文:https://arxiv.org/pdf/2203.14309.pdf
Github: https://github.com/BGU-CS-VIL/DeepDPM
作者介绍:
Tanushree Shenwai,MarkTechPost 的咨询实习生。她目前正在布巴内斯瓦尔的印度理工学院攻读学士学位。她是一名数据科学爱好者,对人工智能在各个领域的应用范围有着浓厚的兴趣。她热衷于探索技术的新进展及其在现实生活中的应用。
原文链接:
https://www.marktechpost.com/2022/04/21/researchers-introduce-a-deep-learning-approach-deepdpm-that-supports-deep-clustering-without-knowing-the-number-of-clusters/
你也「在看」吗?👇









