如果你觉得机器学习入门难,那也许是姿势不对,意大利特伦托大学机器学习与智能优化实验室(LION lab)的巴老师,根据自己的项目写了一本书,带领大家爽快跳坑...
如果你还记得小时候是如何识字的,那么你就可以理解什么是从实例中学习,尤其是监督学习。父母和老师给你展示一些带有英文字母(a、b、c,等等)的实例,然后告诉你:这是a,这是 b,…
当然,他们并没有用数学公式或者精确的规律来描述这些字母的几何形状。他们只是展示了一些不同风格、不同形式、不同大小和不同颜色的已标记的实例。经过一些努力和失误之后,你的大脑就能够正确识别这些实例了。
然而这不是关键,因为仅凭记忆你其实就能够做到这一点。重要的是,通过这些实例的训练,你的大脑还能从中提取出与认字真正相关的模式和规律,过滤掉不相关的“噪声”(比如颜色),从而进行泛化(generalize),以识别在训练阶段从未见过的新实例。
这是很自然的结果,但确实是值得注意的成果。取得这一成果不需要什么先进的理论,也不需要博士学位。

人工智能领域先驱罗伯托·巴蒂蒂的《机器学习与优化》这本书,能像上面这样自然而又轻松地进行机器学习,还能用来分析和解决实实在在的商业问题,是不是很令人振奋呢?
我们先来实际感受一下:轻松学机器学习基本概念之“最近邻方法”。
本书作者生活的地方有很多山地和森林,因此采蘑菇是一项十分普及的消遣活动。虽然采蘑菇很受欢迎也很有趣,但是误食有毒的蘑菇将造成致命的危害(见图 1)。这里的小孩子在很小的时候就学会了如何区分可以食用的和有毒的蘑菇。到这里来的游客可以买到相关的书籍,书中有这两类蘑菇的图片和特征;他们也可以把采到的蘑菇带到当地的警察局,让专家帮他们免费检验这些蘑菇。

图 1 采蘑菇要区分可以食用的和有毒的
这里有一个被简化过的例子,如图 2 所示,假设我们用两个参数,比如高度和宽度,就能够区分这两种蘑菇。当然,一般来说,我们需要考虑更多的输入参数,像颜色、形状、气味等,甚至是更加令人困惑的正类(可以食用的)和负类实例的概率分布。
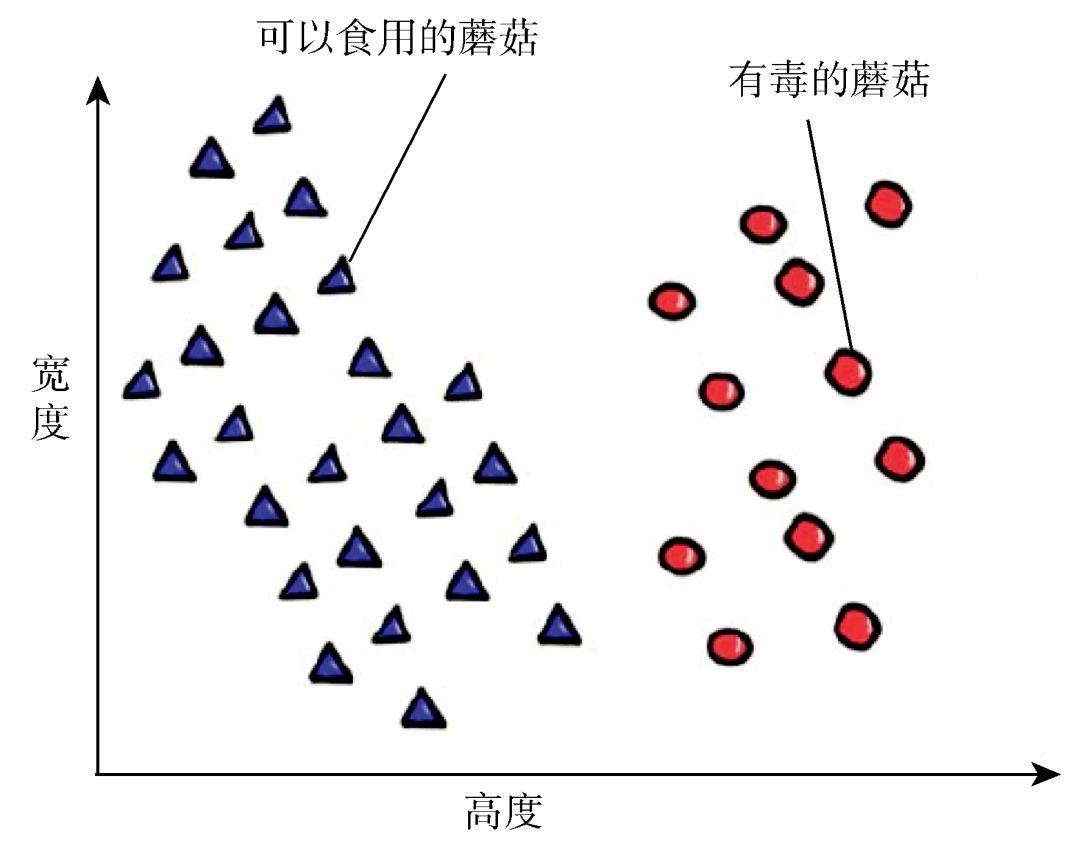
图 2 简化的例子:两个特征(宽度和高度)用以区分可以食用的和有毒的蘑菇
那些懒惰的初学者在采蘑菇的时候遵循简单的模式。通常他们在采摘蘑菇之前没有学习任何相关的知识,毕竟,他们到特伦蒂诺是来度假的,而不是来工作的。当发现一个蘑菇时,他们会在书中寻找相似的图片,然后仔细检查对照细节列表中的相似特征。这就是机器学习中懒惰的“最近邻”(nearest neighbor)算法在实际问题中的一次应用。
为什么这样一种简单的方法是有效的呢?我们可以用 Natura non facit saltus(“自然不允许跳跃”的拉丁文)原则来解释它。自然的事物与特征常常是逐渐改变,而不是突然改变的。如果你将书中的一个可食用的蘑菇作为原型,然后发现你自己采摘的蘑菇与这个原型蘑菇的各项特征非常相似,那么你也许会认为你的蘑菇是可以食用的。
声明:不要使用这个简单的例子来区分真正的蘑菇,因为每一种分类器都有一定的概率出错,另外蘑菇分类中的假正类(把有毒的蘑菇当成可食用的)将会对你的健康造成极大的损害。
最近邻方法
在机器学习领域,最近邻方法的基本形式与基于实例的学习、基于案例的学习和基于记忆的学习有关。它的工作原理如下:我们把已标记的实例(包括输入及相应的输出的标记)储存起来,不进行任何操作,直到一个新输入模式需要一个输出。这种系统被称为懒惰的学习者:它们只是将这些实例储存起来,其他的什么也不做,直到用户询问它们。当一个新输入模式到达时,我们在存储器中查找到与这个新模式相近的那些实例,输出则由这些相近模式的输出所决定,见图 3。一百多年来,这种数据挖掘的形式仍然被统计学家和机器学习专家广泛地用于分类问题和回归问题。

图 3 最近邻分类:一个清晰的情形(左),一个不太清晰的情形(右)。在第二种情形中,标有问号的查询点的最近的邻居属于负类,但它的更多近邻属于正类
简单点说,一个新输入对应的输出就是存储器里相距最近的那个实例的输出。如果要判断一个新遇见的蘑菇是否可以食用,我们就把它归到记忆中与之最相似的蘑菇的那一类。
虽然十分简单,但很多情况下这种技术都出奇地有效。然而它毕竟是一种偷懒的方法,要为懒惰付出代价!不幸的是,为识别一个新实例所花费的时间可能与存储器中的实例数量成正比,除非用不那么偷懒的方法。这就好比有一个学生,虽然平常买了不少书,但是只在遇到问题时才去读这些书。
梗概
KNN(K 近邻)是一种原始的懒惰的机器学习方式:它只是把所有的训练实例存在存储器中(输入和对应的输出标记)。
当有一个新输入并需要计算其对应的输出时,在存储器中查找 k 个最接近的实例。读取它们的输出,并根据它们的大多数或平均值推导出新实例的输出。当存储了非常多的实例时,训练阶段的懒惰会让预测阶段的响应时间变得很长。
相似的输入经常对应着相似的输出,这是机器学习领域的一个基本假设,因此 KNN 方法在很多实际案例中都有效。它与人类的某些“基于案例”的推理具有相似性。虽然这个方法简单粗暴,但它在很多现实案例中的效果都令人惊奇。
《机器学习与优化》是机器学习实战领域的一本佳作,从机器学习的基本概念讲起,旨在将初学者引入机器学习的大门,并走上实践的道路。
本书通过讲解机器学习中的监督学习和无监督学习,并结合特征选择和排序、聚类方法、文本和网页挖掘等热点问题,论证了“优化是力量之源”这一观点,为机器学习在企业中的应用提供了切实可行的操作建议。

The LION Way: Machine Learning plus Intelligent Optimization
机器学习与优化
作者:罗伯托·巴蒂蒂,毛罗·布鲁纳托
译者:王彧弋
定价:89.00元
因为这是一本可以从实例中进行(机器)学习的书,所以在学习这本书时也要遵从这一点。本书大多数的内容都是按照从实例中学习和从实践中学习的原则来安排的。当介绍不同的技术时,我们会讨论这些技术的基础理论,然后会总结出一些你“应该了解的梗概”。
本书鼓励用现实中的情况来做实验,你可以在本书的网站上找到相关的例子和软件。第一次阅读本书时你可以跳过某些理论部分。
但掌握一些基础的、未被稀释的理论,就像在陌生国度旅行时手中有地图指引。如果你是一艘不知要驶向何处的船,那么风往哪边吹都是无意义的。
本书是第 2 版,英文版第 3 版已出,大家可以在上面给出的网址,下载免费的 PDF。与第 2 版相比,第 3 版扩充了更多内容,但第 2 版不涉及版本过时问题,因此小伙伴们可放心阅读~~
罗伯托·巴蒂蒂(Roberto Battiti)
人工智能领域先驱,IEEE会士。因在无功搜索优化(RSO)方向做出了开创性的工作而名震学界。 目前为意大利特伦托大学教授,同时担任特伦托大学机器学习与智能优化实验室(LION lab)主任。
毛罗·布鲁纳托(Mauro Brunato)
意大利特伦托大学助理教授,LION研究团队成员。
王彧弋
博士,现于瑞士苏黎世联邦理工学院从事研究工作,主要研究方向为理论计算机科学与机器学习。
目录
第 1 章 引言
1.1 学习与智能优化:燎原之火
1.2 寻找黄金和寻找伴侣
1.3 需要的只是数据
1.4 超越传统的商业智能
1.5 LION 方法的实施
1.6 “动手”的方法
第 2 章 懒惰学习:最近邻方法
第 3 章 学习需要方法
3.1 从已标记的案例中学习:最小化和泛化
3.2 学习、验证、测试
3.3 不同类型的误差
第一部分 监督学习
第 4 章 线性模型
4.1 线性回归
4.2 处理非线性函数关系的技巧
4.3 用于分类的线性模型
4.4 大脑是如何工作的
4.5 线性模型为何普遍,为何成功
4.6 最小化平方误差和
4.7 数值不稳定性和岭回归
第 5 章 广义线性最小二乘法
5.1 拟合的优劣和卡方分布
5.2 最小二乘法与最大似然估计
5.3 置信度的自助法
第 6 章 规则、决策树和森林
6.1 构造决策树
6.2 民主与决策森林
第 7 章 特征排序及选择
7.1 特征选择:情境
7.2 相关系数
7.3 相关比
7.4 卡方检验拒绝统计独立性
7.5 熵和互信息
第 8 章 特定非线性模型
8.1 logistic 回归
8.2 局部加权回归
8.3 用 LASSO 来缩小系数和选择输入值
第 9 章 神经网络:多层感知器
9.1 多层感知器
9.2 通过反向传播法学习
第 10 章 深度和卷积网络
10.1 深度神经网络
10.2 局部感受野和卷积网络
第 11 章 统计学习理论和支持向量机
11.1 经验风险最小化
第 12 章 最小二乘法和健壮内核机器
12.1 最小二乘支持向量机分类器
12.2 健壮加权最小二乘支持向量机
12.3 通过修剪恢复稀疏
12.4 算法改进:调谐 QP、原始版本、无补偿
第 13 章 机器学习中的民主
13.1 堆叠和融合
13.2 实例操作带来的多样性:装袋法和提升法
13.3 特征操作带来的多样性
13.4 输出值操作带来的多样性:纠错码
13.5 训练阶段随机性带来的多样性
13.6 加性 logistic 回归
13.7 民主有助于准确率–拒绝的折中
第 14 章 递归神经网络和储备池计算
14.1 递归神经网络
14.2 能量极小化霍普菲尔德网络
14.3 递归神经网络和时序反向传播
14.4 递归神经网络储备池学习
14.5 超限学习机
第二部分 无监督学习和聚类
第 15 章 自顶向下的聚类:K 均值
15.1 无监督学习的方法
15.2 聚类:表示与度量
15.3 硬聚类或软聚类的 K 均值方法
第 16 章 自底向上(凝聚)聚类
16.1 合并标准以及树状图
16.2 适应点的分布距离:马氏距离
16.3 附录:聚类的可视化
第 17 章 自组织映射
17.1 将实体映射到原型的人工皮层
17.2 使用成熟的自组织映射进行分类
第 18 章 通过线性变换降维(投影)
18.1 线性投影
18.2 主成分分析
18.3 加权主成分分析:结合坐标和关系
18.4 通过比值优化进行线性判别
18.5 费希尔线性判别分析
第 19 章 通过非线性映射可视化图与网络
19.1 最小应力可视化
19.2 一维情况:谱图绘制
19.3 复杂图形分布标准
第 20 章 半监督学习
20.1 用部分无监督数据进行学习
第三部分 优化:力量之源
第 21 章 自动改进的局部方法
21.1 优化和学习
21.2 基于导数技术的一维情况
21.3 求解高维模型(二次正定型)
21.4 高维中的非线性优化
21.5 不涉及导数的技术:反馈仿射振荡器
第 22 章 局部搜索和反馈搜索优化
22.1 基于扰动的局部搜索
22.2 反馈搜索优化:搜索时学习
22.3 基于禁忌的反馈搜索优化
第 23 章 合作反馈搜索优化
23.1 局部搜索过程的智能协作
23.2 CoRSO:一个政治上的类比
23.3 CoRSO 的例子:RSO 与 RAS合作
第 24 章 多目标反馈搜索优化
24.1 多目标优化和帕累托最优
24.2 脑–计算机优化:循环中的用户
第四部分 应用精选
第 25 章 文本和网页挖掘
25.1 网页信息检索与组织
25.2 信息检索与排名
25.3 使用超链接来进行网页排名
25.4 确定中心和权威:HITS
25.5 聚类
第 26 章 协同过滤和推荐
26.1 通过相似用户结合评分
26.2 基于矩阵分解的模型
之前发过一篇“程序员如何挑选图书?以图灵机器学习图书为例”,感兴趣的小伙伴可直接点击链接查看。
看完这篇文章,是不是觉得机器学习也不算特别难?跟其他小伙伴分享一下你是否已经入了机器学习的坑,你觉得机器学习中难度最大的部分是?
精选评论中随机挑选 3 位小伙伴送《机器学习与优化》,截止 6 月20日 14:00。
☟ 点击【阅读原文】京东购买《机器学习与优化》











