
许多的安全事件到最后都被追溯到一个最原始的警告信息,而这些信息一般都会被安全运营中心(Security Operations Center,SOC)和应急响应(Incident Response ,IR)团队漏掉或忽视。虽然大多数的分析人员和SOC都很警觉,但事实是告警消息太多了。如果SOC不能去检查产生的这些告警消息,那么早晚会有一些入侵的消息被漏洞。
这里的核心问题是规模的问题。产生告警远比产生分析结果要容易得多,而且与提出解决方案相比,安全行业更擅长生成告警消息。SOC可以通过增加取证任务的自动化、使用聚类过滤器将告警消息分组等方式来管理如此多的告警消息。
有一些有效的措施可以帮助减少SOC分析师所必须的行为的数量。但SOC的决策仍然是一个瓶颈。下面是分析-决策的块图。

图1: 基本的SOC分流阶段
本文中,研究人员提出一种基于机器学习方法的策略来帮助解决该瓶颈问题。研究人员在FireEye Managed Defense SOC中实施了该策略,分析师也在告警消息处理流中使用了该方法。下面会详细解释数据收集、获取告警分析、创建模型、建立效能工作流等。
 逆向分析
逆向分析
每个告警消息都会含有一些信息来供分析师判断是否是恶意行为。研究人员就想提取分析的路径、训练机器学习模型来遍历这些路径,并最终发现新的恶意行为。
如果把SOC看作是一个自包含的机器,不含标记的告警就是机器的输入,标记后的告警就是该机器的输出。亟需解决的一个问题就是如何训练一个机器来进行大规模的分析、决策和标记。
基本的有监督模型过程
有监督分类模型(Supervised Classification Model)是指从已经标记过的数据中去学习,那么经过该分类器训练出的结果就是标记后的离散数据。本例中,要标记是就是恶意malicious和非恶意benign的输入。
要创建这样的模型,首先需要收集数据集。数据集就是模型的经验来源,也是用来训练模型然后来做决策。为了监督模型,数据的每个单元必须被标记为善意的或者恶意的,所以该模型要能够评估每个观察,并找出哪些会被标记为善意的,哪些会被标记为恶意的。
但收集一个干净的、标记过的数据集是有监督模型管道,在SOC的例子中,分析师每周会持续标记上千个告警消息,所以我们有标准化的、标记的告警消息。
定义好标记过的数据集后,下一步是定义可以用来描述告警消息的特征。特征可以看作是信息本身的一部分。比如信息是字符串的话,那么字符串的长度就可以作为特征。构建告警消息分类模型特征的关键思想是找出能够表示和记录分析师做决策时的思想。
构建该模型还需要选择模型结构,在数据子集上训练模型。数据集越大、种类越多,模型的效果就越好。剩下的数据可以作为测试集来检验训练模型的效果。
最后,需要确保随着时间的进行能够评估模型的有效性,以及确定错误率并对模型进行一些调整。没有评估的方案和管道,模型的性能就会有所减弱。
特征工程
在创建模型前,研究人员与有经验的分析师进行了面谈,并记录了他们对告警消息进行评估的依据。这是特征提取的基础,也是对分析和决策过程的逆向分析。
比如,对于一个进程执行事件,恶意进程执行可能含有下面的域:
· Process Path进程路径
· Process MD5进程md5
· Parent Process父进程
· Process Command Arguments进程命令参数
虽然这看起来有一些局限,但可以从这些域中提取一些有用的信息。
进程路径是C:\windows\temp\m.exe。有经验的分析师很快就可以判断出下面的特征:
· 进程位于临时文件夹C:\windows\temp\
· 进程在文件系统中是两级目录
· 进程执行名师一个字母长
· 进程有.exe扩展
· 进程名不是常见的进程名
这些看起来很简单的知识,在大量数据集的基础上,提取出的信息可以帮助模型去区分不同的事件。模型还需要提取最基本的信息来教会模型如何去观察进程。
这些特征可以以一种更离散的方式去编码:

进程执行事件中另一个需要考虑到重要特征是将父进程和子进程的结合。与期望结果的偏差就意味着恶意活动。
前述的例子中的父进程就是powershell.exe。一些潜在的新特征可以从父进程和进程本身的相关事物联系中提取出:powershell.exe_m.exe。该功能是父子关系的身份证明,并可以作为另外一个重要的分析方式。
最丰富的域可能是进程参数。进程参数是对自己的语言的分类,语言分析师预测分析的一个重要因素。
可以寻找的因素包括:
· 网络连接字符串(‘http://’, ‘https://’, ‘ftp://’)
· Base64编码的命令
· 注册表引用(‘HKLM’, ‘HKCU’)
· 混淆证明(ticks, $, semicolons)
这些特征和值在训练集中出现的方式会定义模型学习的方式。基于告警消息的特征分布,特征和标记的关系就会逐渐显现。之后这些关系会被模型所记录,最终影响新告警消息的预测。根据训练数据集中特征的分布我们可以看出一些可能的关系来。
比如,图2就是进程命令长度的分布和善意(蓝)、恶意(红)分组的关系
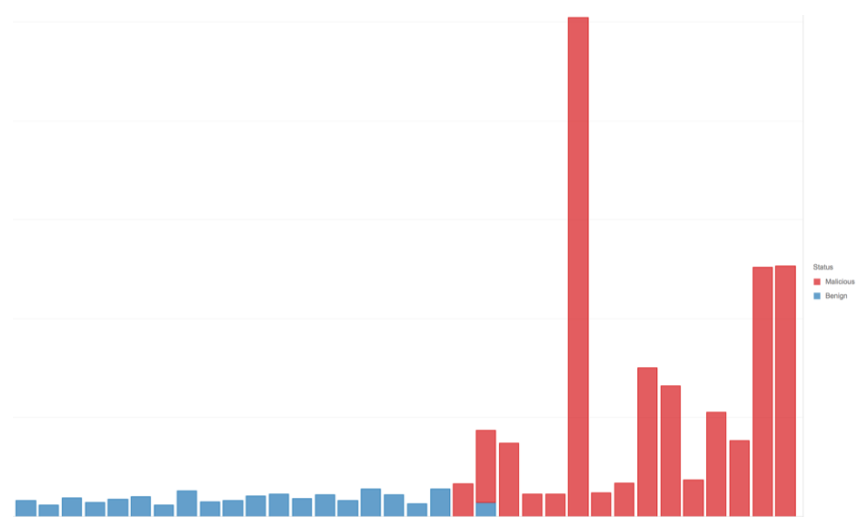
图2 根据进程命令长度对进程事件告警分布进行分组
上图只是样本的一个子集,命令长度越长,命令就越可能是恶意的。但命令长度并不是唯一的决定因素。
作为特征集的一部分,还可以对每个命令的复杂度进行估计。研究人员采用了香农定理(hannon entropy)来测算字符串中字母的随机度。
图3是命令熵的一个分布,也是分为善意的和恶意的。虽然分类不完全是独立的,从样本数据中可以得出结果:样本的熵值越高,是恶意样本的可能性就越大。
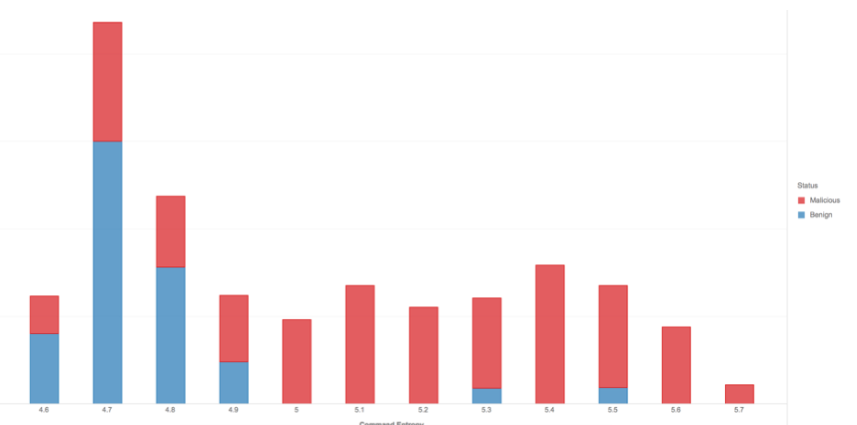
图3: 根据命令熵对进程事件告警分布进行分组
我将在下一部分讲述模型的选择和SOC如何使用该模型。











