文:Conor Dewey 译:欧剃
每个人都会遇到这个问题。
学习数据科学的过程,从来就不是一帆风顺的。在写代码的时候,你是否也经常不得不反复搜索同一个问题,同一个概念,甚至同一个语法结构的特性呢?对,你不是一个人在战斗。
我也一直在同样的情况里挣扎着。
虽然遇到问题上 StackOverflow 搜一搜是相当正常的,但比起切实掌握理解语言特性的情况,不断重复的遇到问题+搜来搜去,会严重拖慢你的速度。
如今,无穷无尽的免费资源时时刻刻充斥着互联网,一搜即得。然而,对初学者,这既是一种祝福,也是一个诅咒。如果不经过有效管理,过度依赖网络资源会让你养成糟糕的习惯,从长远上影响了你的成长。

欧剃汉化,优达学城出品
拿我自己来说,我常常从许多内容差不多的帖子里复制代码下来使用,而不愿意花时间和精力去学习巩固其中所需的技术概念,以便下次能自己写出需要的代码。
这是个懒办法,虽然短期内看起来它能简单快速地搞定问题,但从长远上看,这个做法会严重影响你的成长,破坏你的创造性,并从根本上动摇你回想某些语法特性的能力(这在技术面试的时候可是致命的)。

欧剃汉化,优达学城出品
为了进一步巩固我自己对这些概念的理解,也为了帮大家节省一下每次上网搜索的时间,我在这里整理了一下自己使用 Python、NumPy 和 Pandas 时遇到的一些常见的小问题,希望对你有帮助。
只要一行代码的列表生成器
假如每次你想要生成个列表,都要写个循环,是不是很烦呢?好在 Python 已经有一个内建方法,只要一行代码就能搞定这个问题。如果你不熟悉这个语法,可能理解起来会有点难度,不过一旦你习惯这个技术之后,你一定会爱不释手的!

动图:如何将一个循环改成列表生成式(来源:Trey Hunner )
上面这个动图就是一个很好的例子,原来的代码就是采用 for 循环生成列表的方法,而图上一步一步将它改造成了一个只有一行代码的列表生成式,再也不用循环啦。是不是很简洁?
下面是另外一个对比范例:
使用循环:

输出的结果是 [1, 4, 9, 16]
使用生成式:
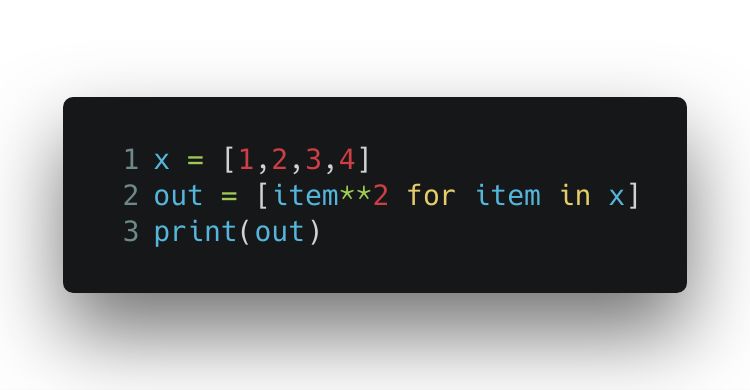
输出的结果也是 [1, 4, 9, 16]
Lambda 表达式
明明这个函数用不了几次,每次都要写一大串函数构建代码,是不是很累?别怕,Lambda 表达式来救你!Lambda 表达式能方便地创造简单、一次使用而且匿名的函数对象。基本上,它们让你无需费心构造一个函数,而是直接使用这个函数。
Lambda 表达式的基本语法是:

要记住,Lambda 表达式创造的函数和普通的 def 构建的函数没什么不同,只不过函数体只有单独一个表达式而已。看看下面这个例子:

输出的结果是 10
Map 和 Filter 函数
一旦你掌握了 Lambda 表达式,将它们与 map 或 filter 函数一起使用,可谓是威力无比。
具体来说, map() 函数接收一个列表,和一个函数,它对列表里的每个元素调用一个函数进行处理,再将结果放进一个新列表里。下面这个例子中,map() 函数遍历 seq 中的每个元素,把它乘2,再把结果放入一个新列表,最后返回这个列表。最外面一层 list() 函数是把 map() 返回的对象转换成列表格式。
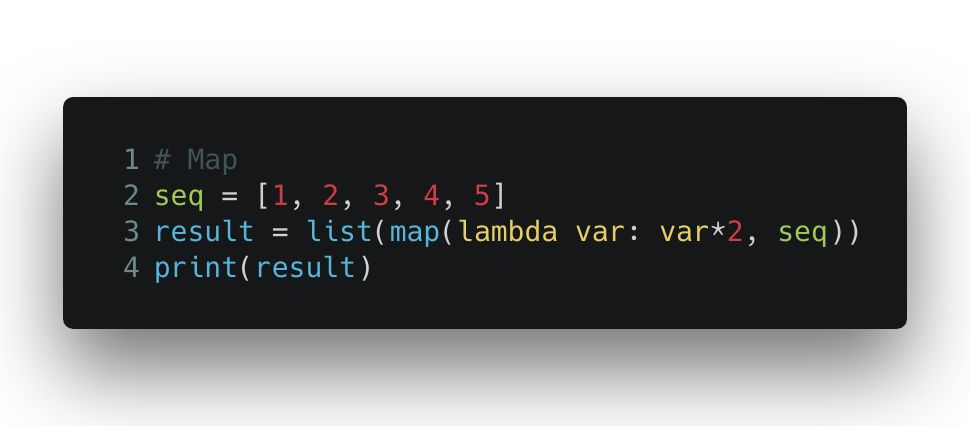
输出的结果是 [2, 4, 6, 8, 10]
而 filter() 函数略有不同,它接收一个列表,和一个规则函数,在对列表里的每个元素调用这个规则函数之后,它把所有返回值为假的元素从列表中剔除,然后返回这个过滤后的子列表。
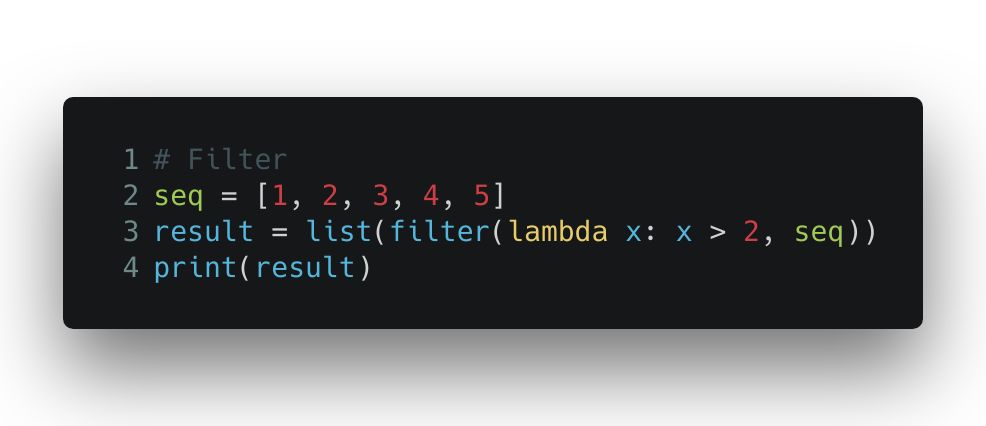
输出的结果是 [3, 4, 5]
Arange 和 Linspace 函数
为了快速方便地生成 numpy 的数组,你一定得熟悉 arange() 和 linspace() 这两个函数。这两个函数分别有自己的特定用法,不过对我们来说,它们都能很好地生成 numpy 数组(而不是用 range() ),这在数据科学的分析工作上可是相当好用的。
arange() 函数按照指定的步长返回一个等差数列。除开始和结束值之外,你还可以自定义步长和数据类型。请注意,给定的结束值参数是不会被包含在结果内的。
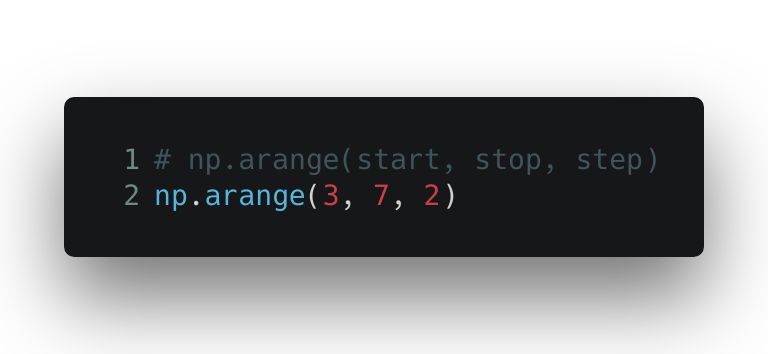
输出的是一个数组对象: array([3, 5])
linspace() 函数的用法也很类似,不过有一点小小的不同。 linspace() 返回的是将给定区间进行若干等分以后的等分点组成的数列。所以你传入的参数包括开始值、结束值,以及具体多少等分。linspace() 将这个区间进行等分后,把开始值、结束值和每个等分点都放进一个 NumPy 数组里。这在做数据可视化以及绘制坐标轴的时候都很有用。
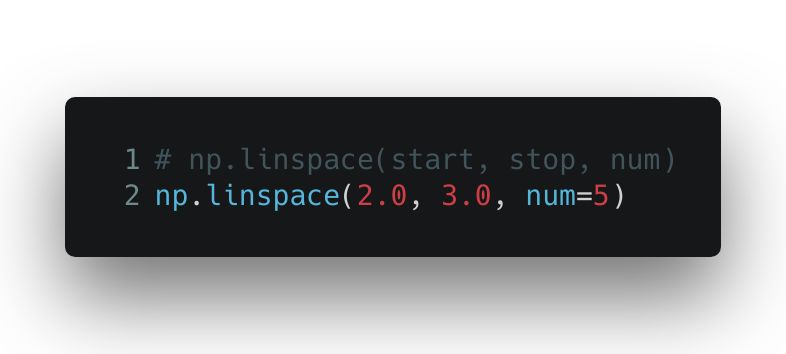
输出的是一个数组对象: array([ 2.0, 2.25, 2.5, 2.75, 3.0])
Pandas 中坐标轴(axis 参数)的意义
在 Pandas 里要筛掉某一列,或是在 NumPy 矩阵里要对数据求和的时候,你可能已经遇到过这个 axis 参数的问题。如果你还没见过,那提前了解一下也无妨。比如,对某个 Pandas 表这样处理:

在我真正理解之前,我基本上每次要用到 drop 的时候,都得去重新查询一下哪个 axis 的值对应的是哪个,多到我自己都数不清了。正如上面这个示例,你大概已经看出,如果要处理列,axis 要设成 1,如果处理行,axis 要设成 0,对吧。但这是为什么呢?我最喜欢的一个解释(或者是我如何记住这一点的)是这样的:

获取 Pandas 数据表对象的 shape 属性,你将获得一个元组,元组的第一个元素是数据表的行数,第二个元素是数据表的列数。想想 Python 里这两个元素的下标吧,前面一个是 0,后面一个是 1,对不对?所以对于 axis 参数,0 就是前面的行数,1 就是后面的列数,怎么样,好记吧?
用 Concat、Merge 和 Join 来合并数据表
如果你熟悉 SQL,这几个概念对你来说就是小菜一碟。不过不管怎样,这几个函数从本质上来说不过就是合并多个数据表的不同方式而已。当然,要时刻记着什么情况下该用哪个函数也不是一件容易的事,所以,让我们一起再回顾一下吧。
concat() 可以把一个或多个数据表按行(或列)的方向简单堆叠起来(看你传入的 axis 参数是 0 还是 1 咯)。
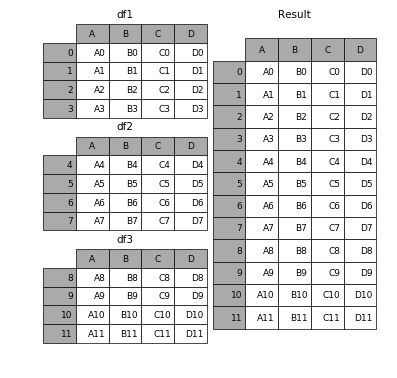
merge() 将会以用户指定的某个名字相同的列为主键进行对齐,把两个或多个数据表融合到一起。
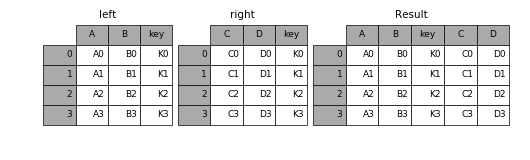
join()和 merge() 很相似,只不过 join() 是按数据表的索引进行对齐,而不是按某一个相同的列。当某个表缺少某个索引的时候,对应的值为空(NaN)。

有需要的话,你还可以查阅Pandas 官方文档 ,了解更详细的语法规则和应用实例,熟悉一些你可能会碰到的特殊情况。
Apply 函数
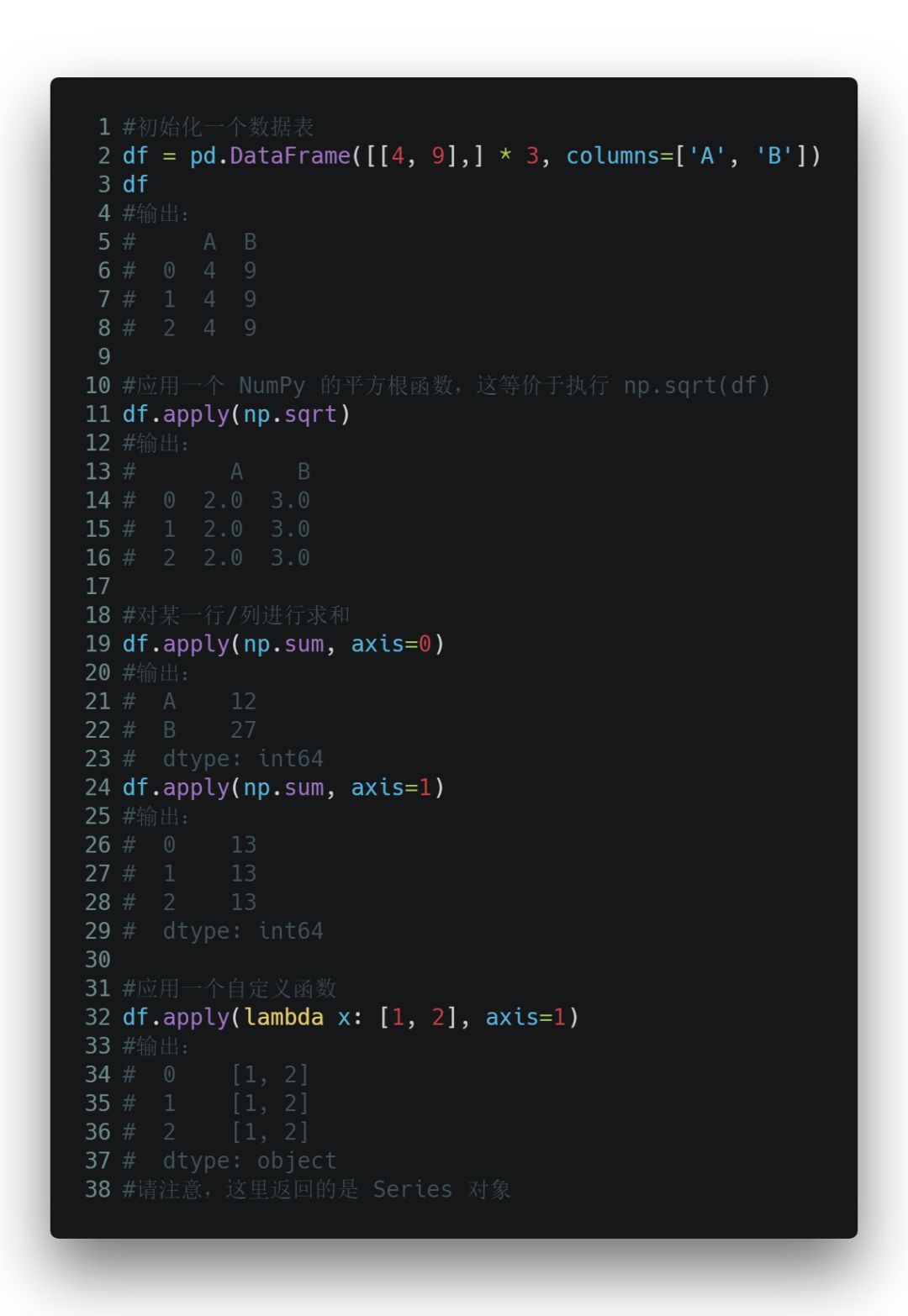
你可以把 apply() 当作是一个 map() 函数,只不过这个函数是专为 Pandas 的数据表和 series 对象打造的。对初学者来说,你可以把 series 对象想象成类似 NumPy 里的数组对象。它是一个一维带索引的数据表结构。
apply() 函数作用是,将一个函数应用到某个数据表中你指定的一行或一列中的每一个元素上。是不是很方便?特别是当你需要对某一列的所有元素都进行格式化或修改的时候,你就不用再一遍遍地循环啦!
这里就举几个简单的例子,让大家熟悉一下基本的语法规则:
数据透视表(Pivot Tables)
最后也最重要的是数据透视表。如果你对微软的 Excel 有一定了解的话,你大概也用过(或听过)Excel 里的“数据透视表”功能。Pandas 里内建的 pivot_table() 函数的功能也差不多,它能帮你对一个数据表进行格式化,并输出一个像 Excel 工作表一样的表格。实际使用中,透视表将根据一个或多个键对数据进行分组统计,将函数传入参数 aggfunc 中,数据将会按你指定的函数进行统计,并将结果分配到表格中。
下面是几个 pivot_table() 的应用例子:

总结
以上就是我在自学过程中经常遇到的几个问题,及其理解方法。就我个人来说,把这些概念写下来,并用尽可能简单的语句描述它们,再分享给大家的整个过程,也让我更加深入的理解和掌握这些技术。
最后,我希望,或许以后你和数据科学中这些难以捉摸的方法、函数以及概念斗智斗勇的时候,今天看到的一些知识能派上点用场。
欢迎购买我们的可视化课程
预售20天已有1246+学员加入,数据君从市场上制作的专业性、讲解逻辑的清晰程度、案例解析、人品等方面从行业10几位可视化大咖中,唯一敲定和爱数圈合作的讲师,因为我要靠谱质量、口碑、性价比,当然要求也很苛刻,毕竟你要过数据君的法眼,呵呵~~~
注意:此课程是连载课程,每周更新2~3课时,预计7月底更新完成
课程特点:
1、全面的图表制作流程,一课包揽所有图表制作
2、视频讲解流程清晰,永久观看
3、提供售后解答
4、案例讲解
5、性价比极高
定价199、目前活动价只要128,28日活动结束,欲购从速
如何购买?扫码







