
作者:罗罗攀 《从零开始学Python网络爬虫》书籍作者
Python爱好者社区专栏作者 Python爬虫爱好者
个人公众号:罗罗攀
博客地址:http://www.jianshu.com/u/9104ebf5e177
本系列教程为《机器学习实战》的读书笔记。首先,讲讲写本系列教程的原因:第一,《机器学习实战》的代码由Python2编写,有些代码在Python3上运行已会报错,本教程基于Python3进行代码的修订;第二:之前看了一些机器学习的书籍,没有进行记录,很快就忘记掉了,通过编写教程也是一种复习的过程;第三,机器学习相对于爬虫和数据分析而言,学习难度更大,希望通过本系列文字教程,让读者在学习机器学习的路上少走弯路。
前文传送门:
机器学习实战之KNN算法
机器学习实战之Logistic回归
今天学习的机器学习算法不是一个单独的算法,我们称之为元算法或集成算法(Ensemble)。其实就是对其他算法进行组合的一种方式。俗话说的好:“三个臭皮匠,赛过诸葛亮”。集成算法有多种形式:对同一数据集,使用多个算法,通过投票或者平均等方法获得最后的预测模型;同一算法在不同设置下的集成;同一算法在多个不同实例下的集成。本文着重讲解最后一种集成算法。
bagging
如果训练集有n个样本,我们随机抽取S次,每次有放回的获取m个样本,用某个单独的算法对S个数据集(每个数据集有m个样本)进行训练,这样就可以获得S个分类器。最后通过投票箱来获取最后的结果(少数服从多数的原则)。这就是bagging方法的核心思想,如图所示。
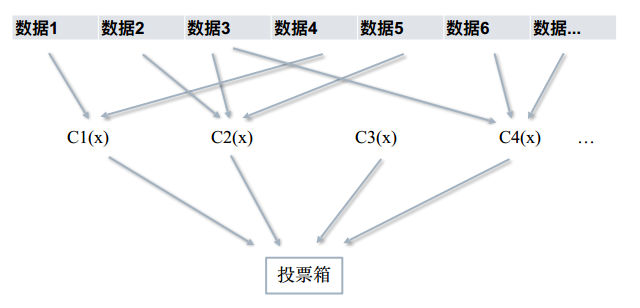
bagging中有个常用的方法,叫随机森林(random forest),该算法基于决策树,不仅对数据随机化,也对特征随机化。
每棵树无限生长,最后依旧通过投票箱来获取最后的结果。
boosting
boosting方法在模型选择方面和bagging一样:选择单个机器学习算法。但boosting方法是先在原数据集中训练一个分类器,然后将前一个分类器没能完美分类的数据重新赋权重(weight),用新的权重数据再训练出一个分类器,以此循环,最终的分类结果由加权投票决定。 所以:boosting是串行算法(必须依赖上一个分类器),而bagging是并行算法(可以同时进行);boosting的分类器权重不同,bagging相同(下文中详细讲解)。
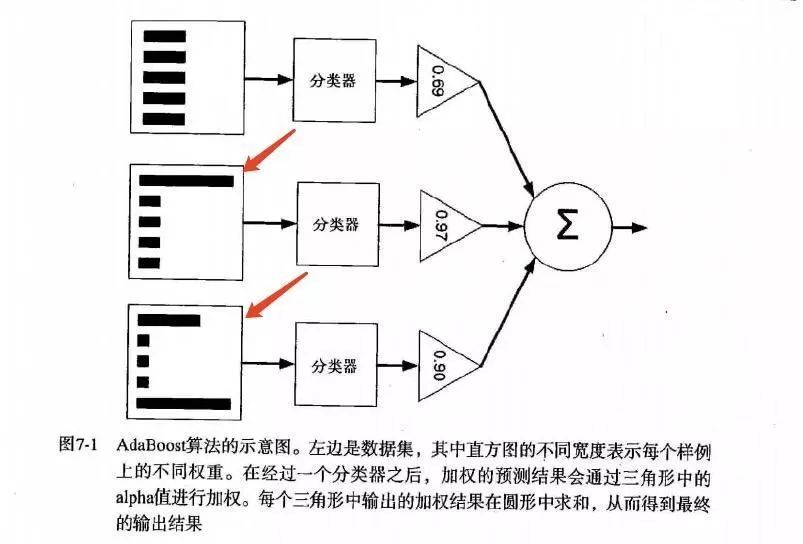
boosting也有很多版本,本文只讲解AdaBoost(自适应boosting)方法的原理和代码实践。 如图所示,为AdaBoost方法的原理示意图。
首先,训练样本赋权重,构成向量D(初始值相等,如100个数据,那每个数据权重为1/100)。
在该数据上训练一个弱分类器并计算错误率和该分类器的权重值(alpha)。
基于该alpha值重新计算权重(分错的样本权重变大,分对的权重变小)。
循环2,3步,但完成给定的迭代次数或者错误阈值时,停止循环。
最终的分类结果由加权投票决定。
alpha和D的计算见下图(来源于机器学习实战):

AdaBoost方法实践
数据来源
数据通过代码创建:
from numpy import *
def loadSimpData():
dataArr = array([[1., 2.1], [2., 1.1], [1.3, 1.], [1., 1.], [2., 1.]])
labelArr = [1.0, 1.0, -1.0, -1.0, 1.0]
return dataArr, labelArr
弱决策树
该数据有两个特征,我们只用一个特征进行分类(弱分类器),然后选择精度最高的分类器。
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr, labelArr, D):
dataMat = mat(dataArr)
labelMat = mat(labelArr).T
m, n = shape(dataMat)
numSteps = 10.0
bestStump = {}
bestClasEst = mat(zeros((m, 1)))
minError = inf
for i in range(n):
rangeMin = dataMat[:, i].min()
rangeMax = dataMat[:, i].max()
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1, int(numSteps)+1):
for inequal in ['lt', 'gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMat, i, threshVal, inequal)
# print predictedVals
errArr = mat(ones((m, 1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr
# print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
AdaBoost算法
该函数用于构造多棵树,并保存每棵树的信息。
def adaBoostTrainDS(dataArr,classLabels, numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m)
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr, classLabels, D)
print('D:',D.T)
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
print('classEst:',classEst.T)
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D, exp(expon))
D = D/D.sum()
aggClassEst += alpha*classEst
print('aggClassEst:',aggClassEst.T)
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T, ones((m,1)))
errorRate = aggErrors.sum()/m
print('total error:',errorRate,'\n')
if errorRate == 0:break
return weakClassArr
算法优缺点
零基础如何入门学习Python网络爬虫?
小编推荐作者的好书,点击阅读原文即可购买


Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“
课程”即可获取:
小编的Python入门免费视频课程!!!
【最新免费微课】小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。










