
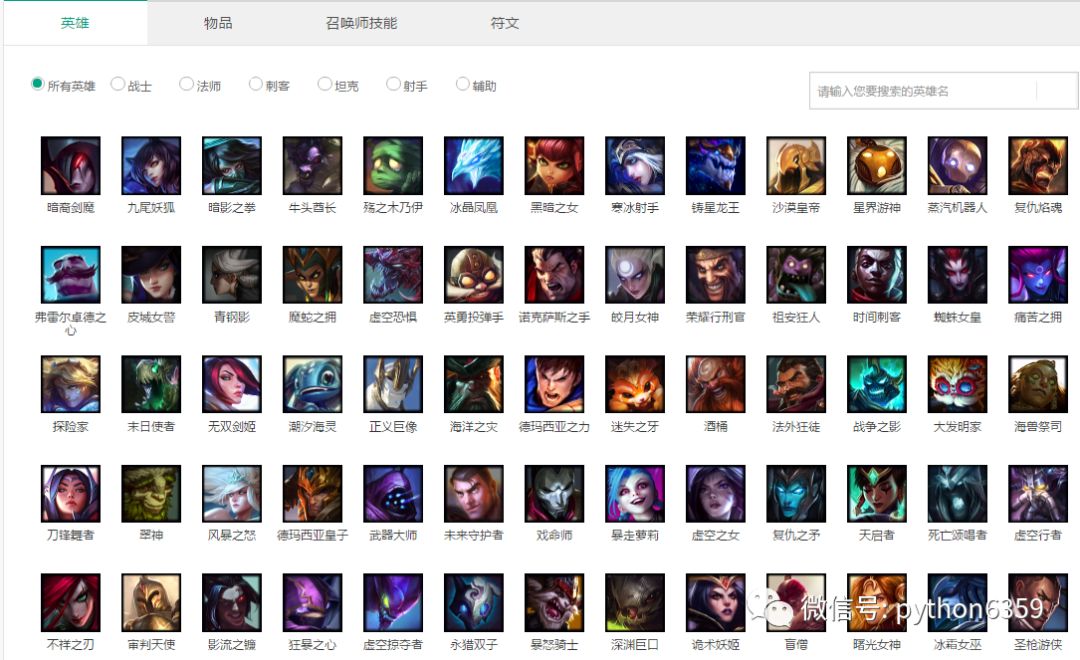
你没有看错,没错今天小编带你爬取LOL官网全英雄皮肤的图片

不要失望,也不要难过
接下咱们来讲讲怎么爬取LOL官网
本次案例使用到的模块
import requests
import re
import json
安装模块:
首先让咱们找到每个英雄皮肤的地址,F12打开开发者工具页面选择器,选中图片自动找寻到图片的地址
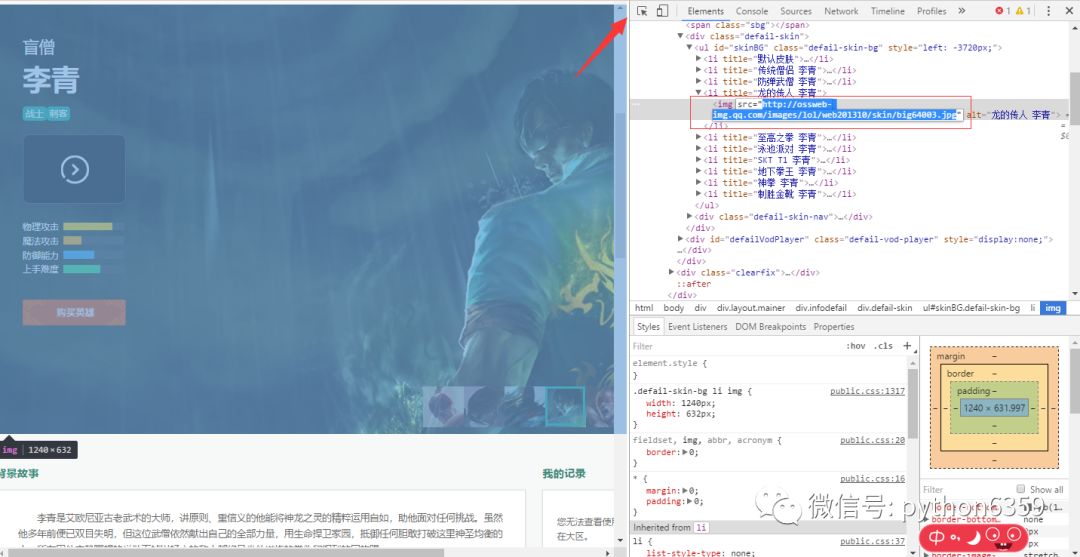
龙的传人 李青的图片地址:
http://ossweb-img.qq.com/images/lol/web201310/skin/big64003.jpg
神僧 李青图片地址:
http://ossweb-img.qq.com/images/lol/web201310/skin/big64011.jpg
不难发现其中的规律:
big64003.jpg
big64011.jpg
很明显 64是英雄的ID地址 003是皮肤顺序
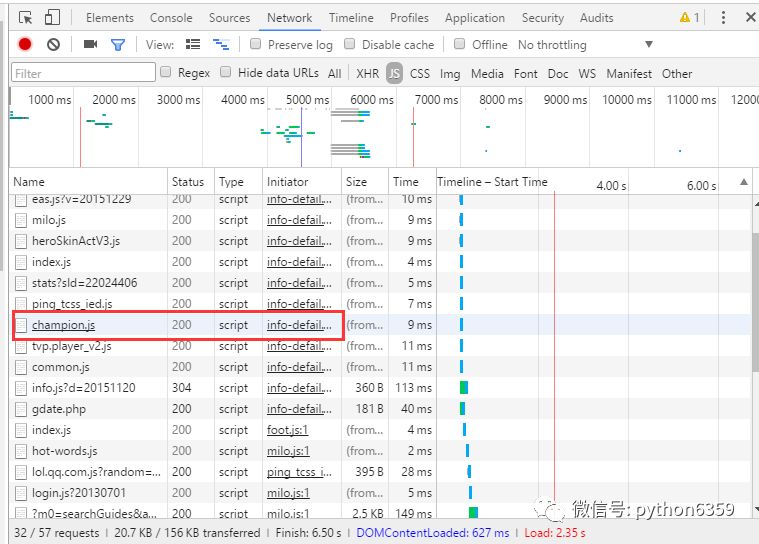

找到JS源代码,你会发现英雄的ID地址并不是按照顺序排列下来的!
def getLOLImages():
url_js = 'http://lol.qq.com/biz/hero/champion.js'
res_js = requests.get(url_js).content
html_js = res_js.decode()
req = '"keys":(.*?),"data"'
list_js = re.findall(req,html_js)
dict_js = json.loads(list_js[0])
print(dict_js)
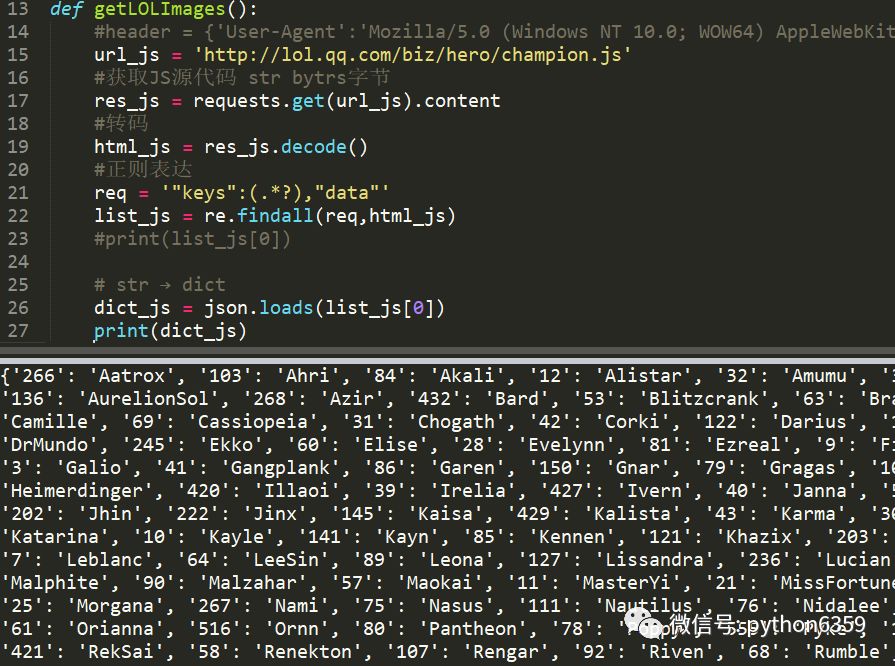
很多不明白这个正则表达式怎么写,这里简单的说明一下:

前面是 “keys”:后面是,“data” 然后我们需要提取的是中间的部分,那么不管它们是啥,我们就是.?* 通配符全部匹配出来。
后面就不详细讲解了,本篇文章最后,小编会带上详细的视频讲解
pic_list = []
for key in dict_js:
#print(key)
for i in range(20):
num = str(i)
if len(num) == 1:
hreo_num = "00"+num
elif len(num) == 2:
hreo_num = "0"+num
numstr = key+hreo_num
url = "http://ossweb-img.qq.com/images/lol/web201310/skin/big"+numstr+".jpg"
print(url)
pic_list.append(url)
list_filepath = []
path = "图片保存地址"
#print(dict_js.values())
for name in dict_js.values():
for i in range(20):
file_path = path + name + str(i) + '.jpg'
list_filepath.append(file_path)
#print(list_filepath)
n = 0
for picurl in pic_list:
res = requests.get(picurl)
n+=1
if
res.status_code ==200:
print("正在下载%s"%list_filepath[n])
with open(list_filepath[n],'wb') as f:
f.write(res.content)
链接:https://pan.baidu.com/s/1TbPuMUsKvuk9bqh3hm6wNQ
密码:ewyk
点击阅读原文即可进入百度云,在这里复制密码就好了









