探索性数据分析是数据科学模型开发和数据集研究的重要组成部分之一。在拿到一个新数据集时首先就需要花费大量时间进行 EDA 来研究数据集中内在的信息。自动化的 EDA Python 包可以用几行 Python 代码执行 EDA。在本文中整理了 10 个可以自动执行 EDA 并生成有关数据的见解的 Python 包,看看他们都有什么功能,能在多大程度上帮我们自动化解决 EDA 的需求。
D-Tale 使用 Flask 作为后端、React 前端并且可以与 ipython notebook 和终端无缝集成。D-Tale可以支持Pandas的DataFrame, Series, MultiIndex, DatetimeIndex 和 RangeIndex。import dtale
import pandas as pd
dtale.show(pd.read_csv("titanic.csv"))
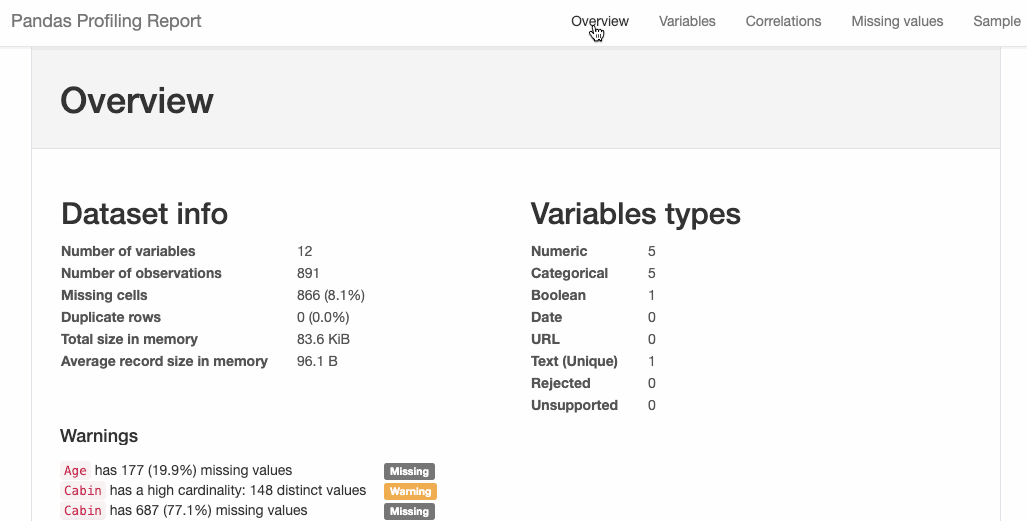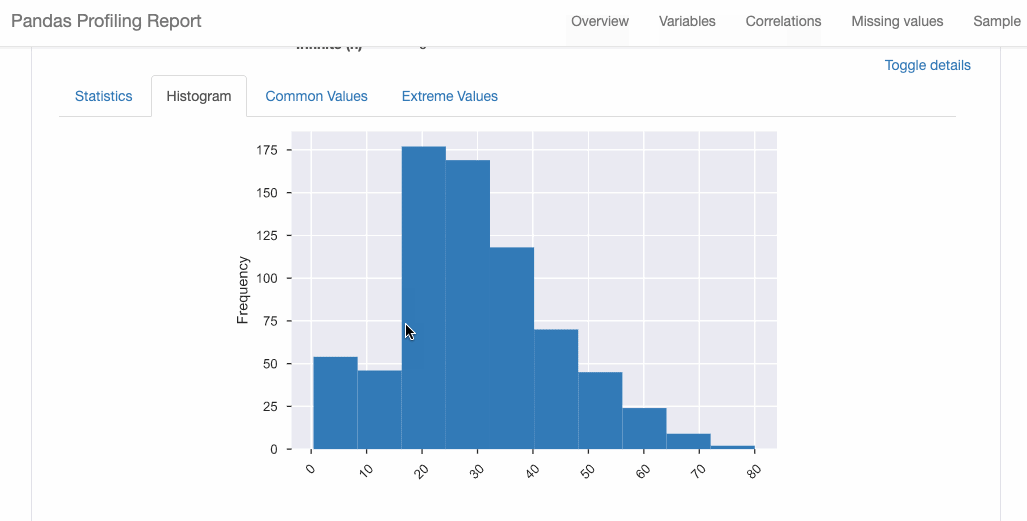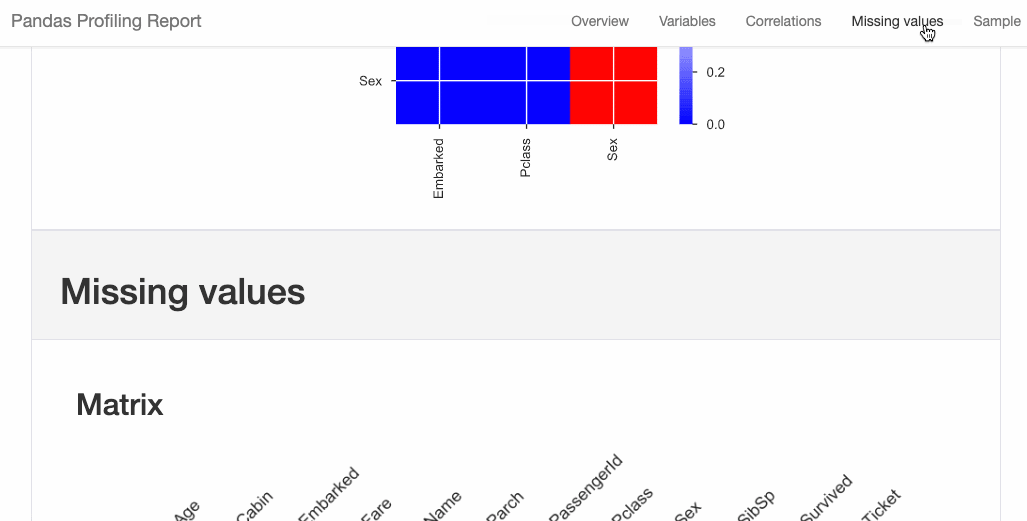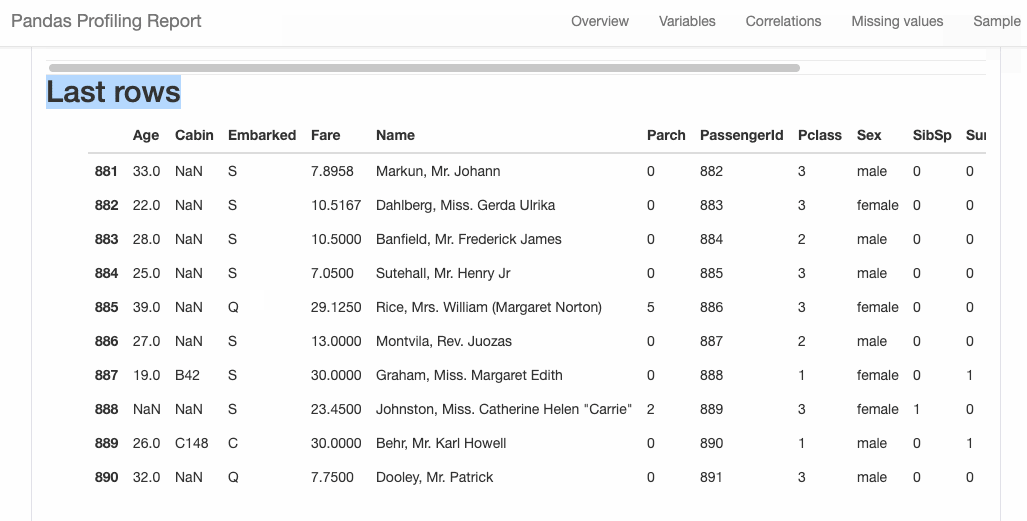
D-Tale 库用一行代码就可以生成一个报告,其中包含数据集、相关性、图表和热图的总体总结,并突出显示缺失的值等。D-Tale 还可以为报告中的每个图表进行分析,上面截图中我们可以看到图表是可以进行交互操作的。Pandas-Profiling 可以生成 Pandas DataFrame 的概要报告。panda-profiling 扩展了 pandas DataFrame df.profile_report(),并且在大型数据集上工作得非常好,它可以在几秒钟内创建报告。
#Install the below libaries before importing
import pandas as pd
from pandas_profiling import ProfileReport
#EDA using pandas-profiling
profile = ProfileReport(pd.read_csv('titanic.csv'), explorative=True)
#Saving results to a HTML file
profile.to_file("output.html")
3、SweetvizSweetviz 是一个开源的 Python 库,只需要两行 Python 代码就可以生成漂亮的可视化图,将 EDA( 探索性数据分析)作为一个 HTML 应用程序启动。Sweetviz 包是围绕快速可视化目标值和比较数据集构建的。import pandas as pd
import sweetviz as sv
#EDA using Autoviz
sweet_report = sv.analyze(pd.read_csv("titanic.csv"))
#Saving results to HTML file
sweet_report.show_html('sweet_report.html')
Sweetviz 库生成的报告包含数据集、相关性、分类和数字特征关联等的总体总结。
4、AutoViz Autoviz 包可以用一行代码自动可视化任何大小的数据集,并自动生成 HTML、bokeh 等报告。用户可以与 AutoViz 包生成的 HTML 报告进行交互。
Autoviz 包可以用一行代码自动可视化任何大小的数据集,并自动生成 HTML、bokeh 等报告。用户可以与 AutoViz 包生成的 HTML 报告进行交互。import pandas as pd
from autoviz.AutoViz_Class import AutoViz_Class
#EDA using Autoviz
autoviz = AutoViz_Class().AutoViz('train.csv')
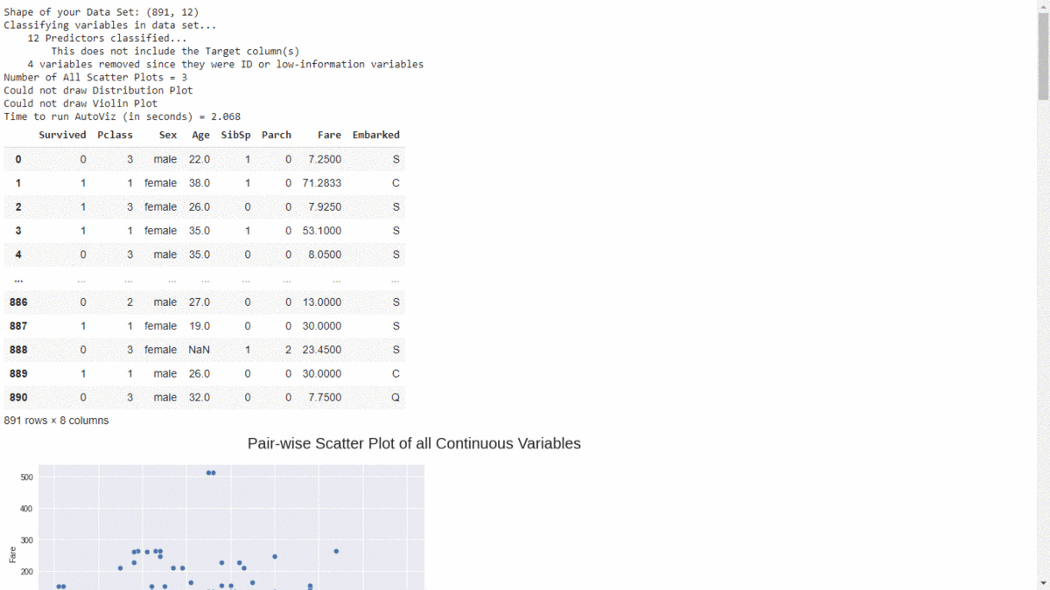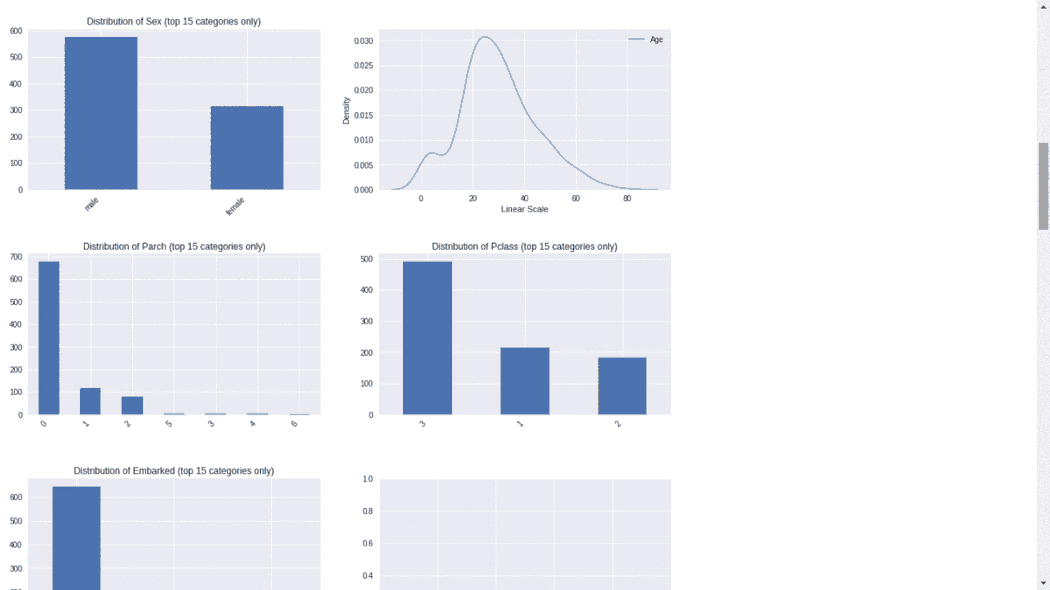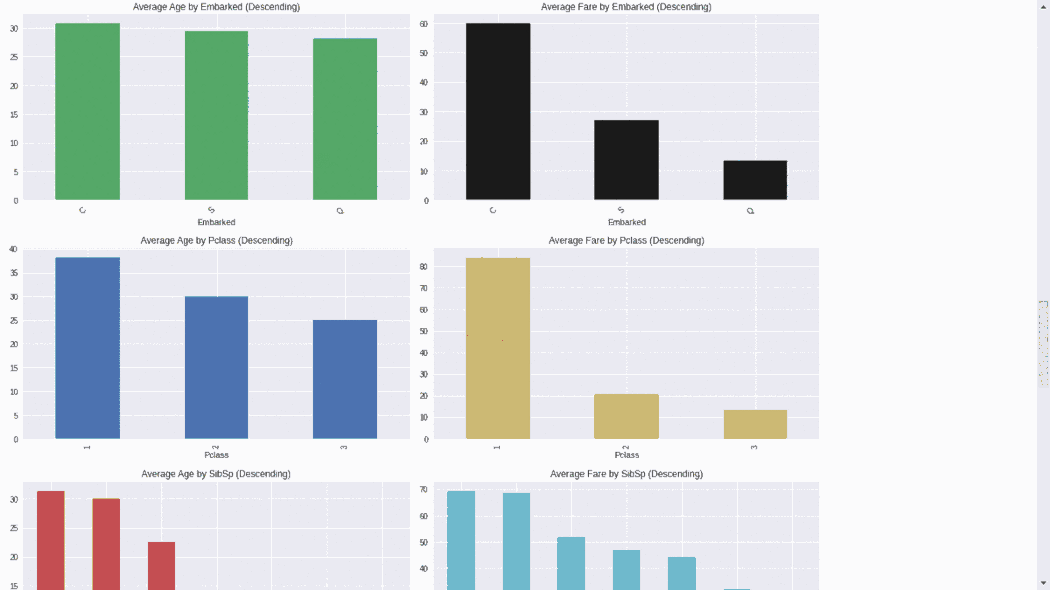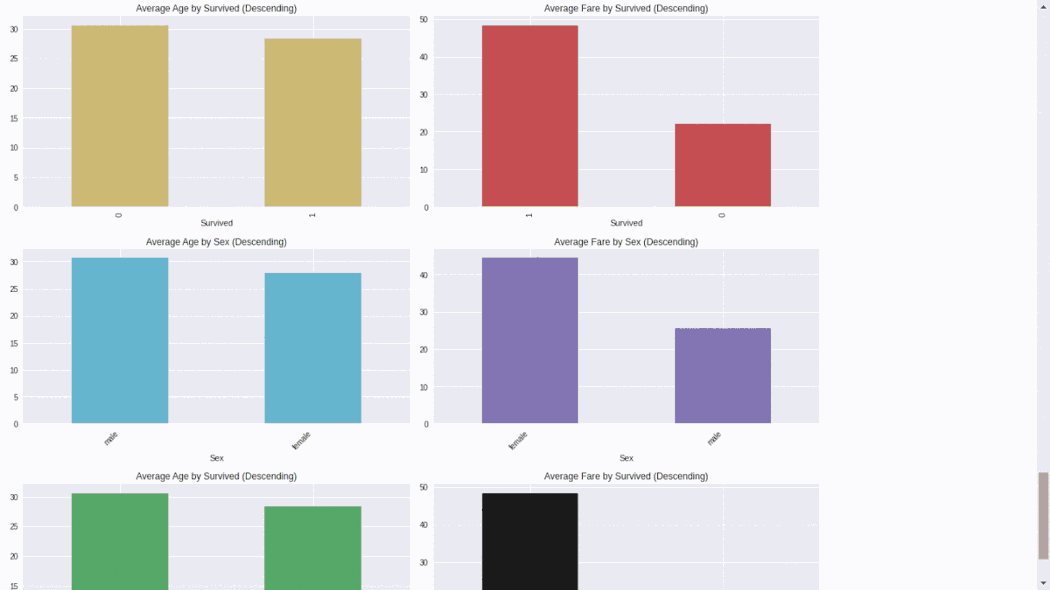
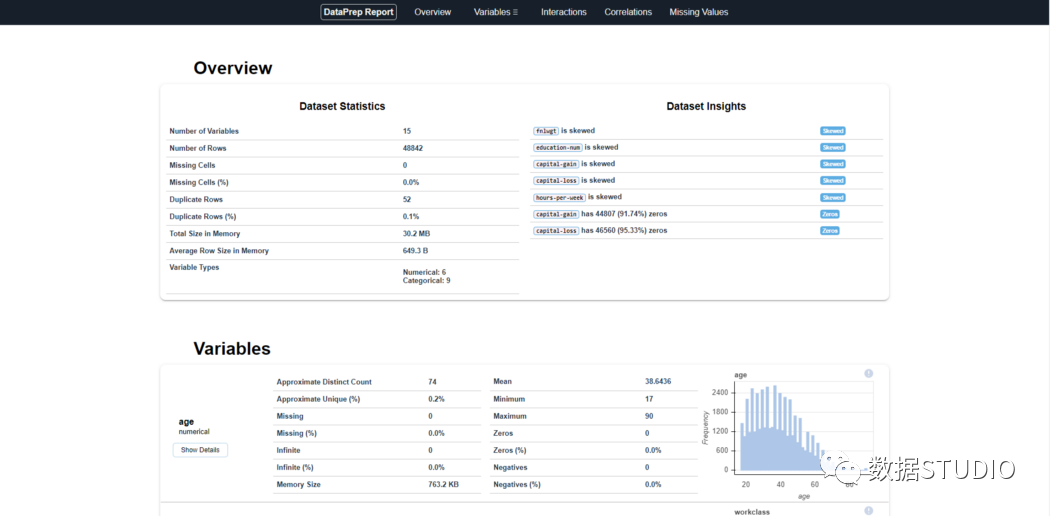
5、DataprepDataprep 是一个用于分析、准备和处理数据的开源 Python 包。DataPrep 构建在 Pandas 和 Dask DataFrame 之上,可以很容易地与其他 Python 库集成。DataPrep 的运行速度这 10 个包中最快的,他在几秒钟内就可以为 Pandas/Dask DataFrame 生成报告。from dataprep.datasets import load_dataset
from dataprep.eda import create_report
df = load_dataset("titanic.csv")
create_report(df).show_browser()
6、Klib
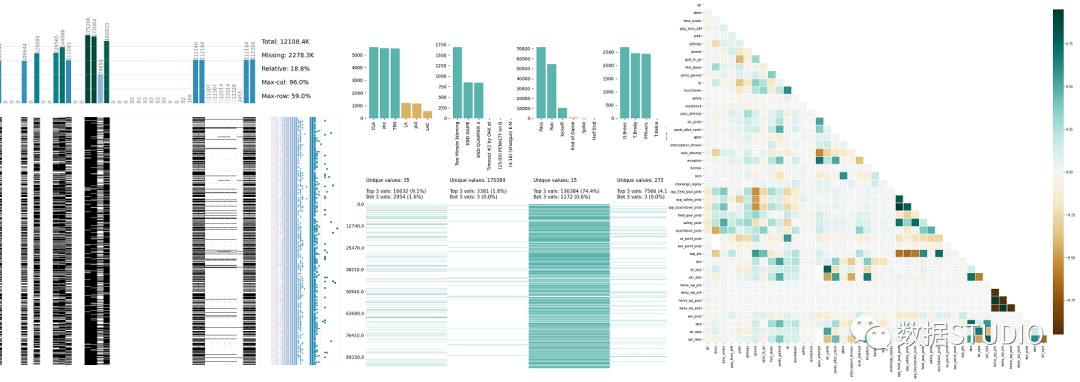 klib 是一个用于导入、清理、分析和预处理数据的 Python 库。
klib 是一个用于导入、清理、分析和预处理数据的 Python 库。import klib
import pandas as pd
df = pd.read_csv('DATASET.csv')
klib.missingval_plot(df)
klib.corr_plot(df_cleaned, annot=False)
klib.dist_plot(df_cleaned['Win_Prob'])
klib.cat_plot(df, figsize=(50,15))
klibe 虽然提供了很多的分析函数,但是对于每一个分析需要我们手动的编写代码,所以只能说是半自动化的操作,但是如果我们需要更定制化的分析,他是非常方便的。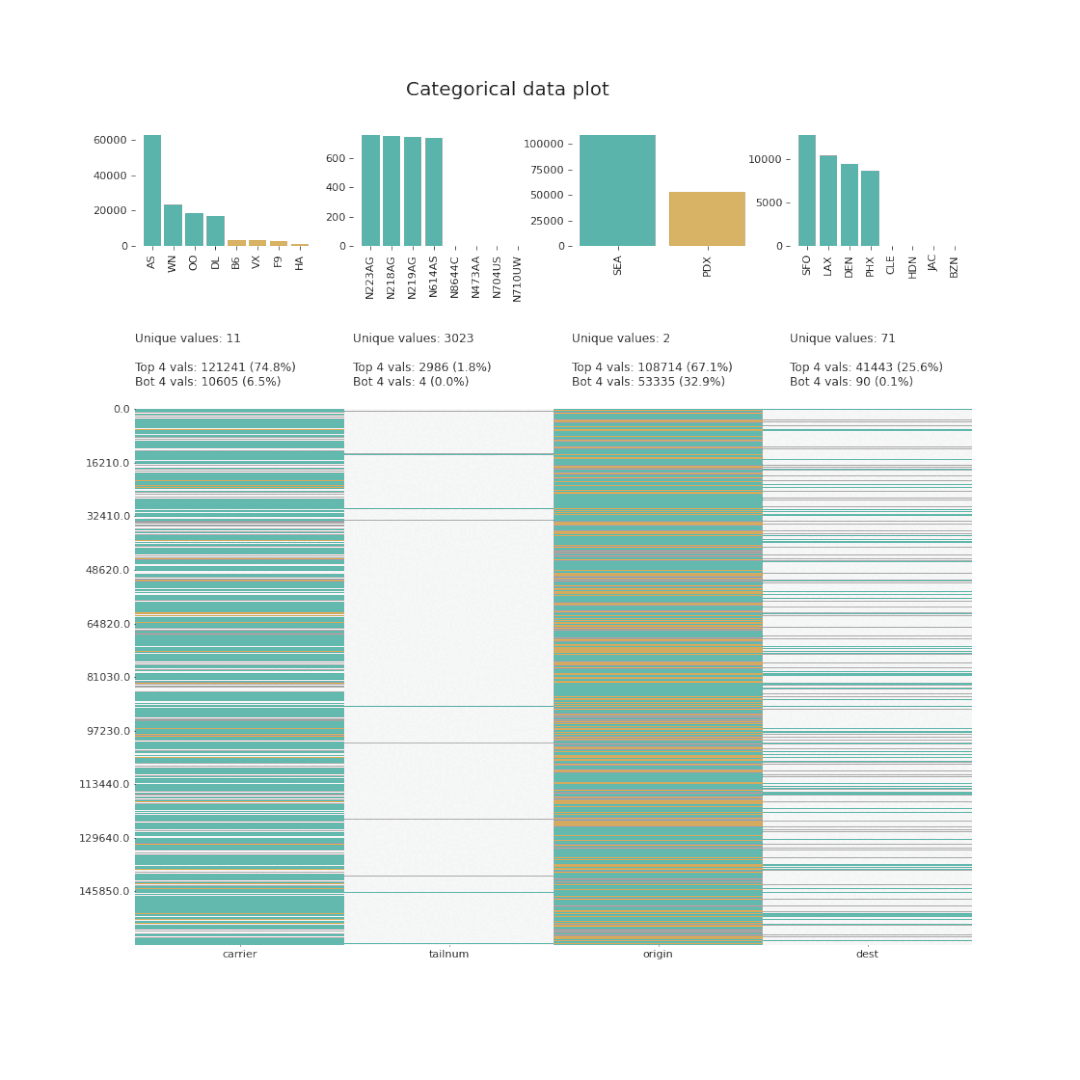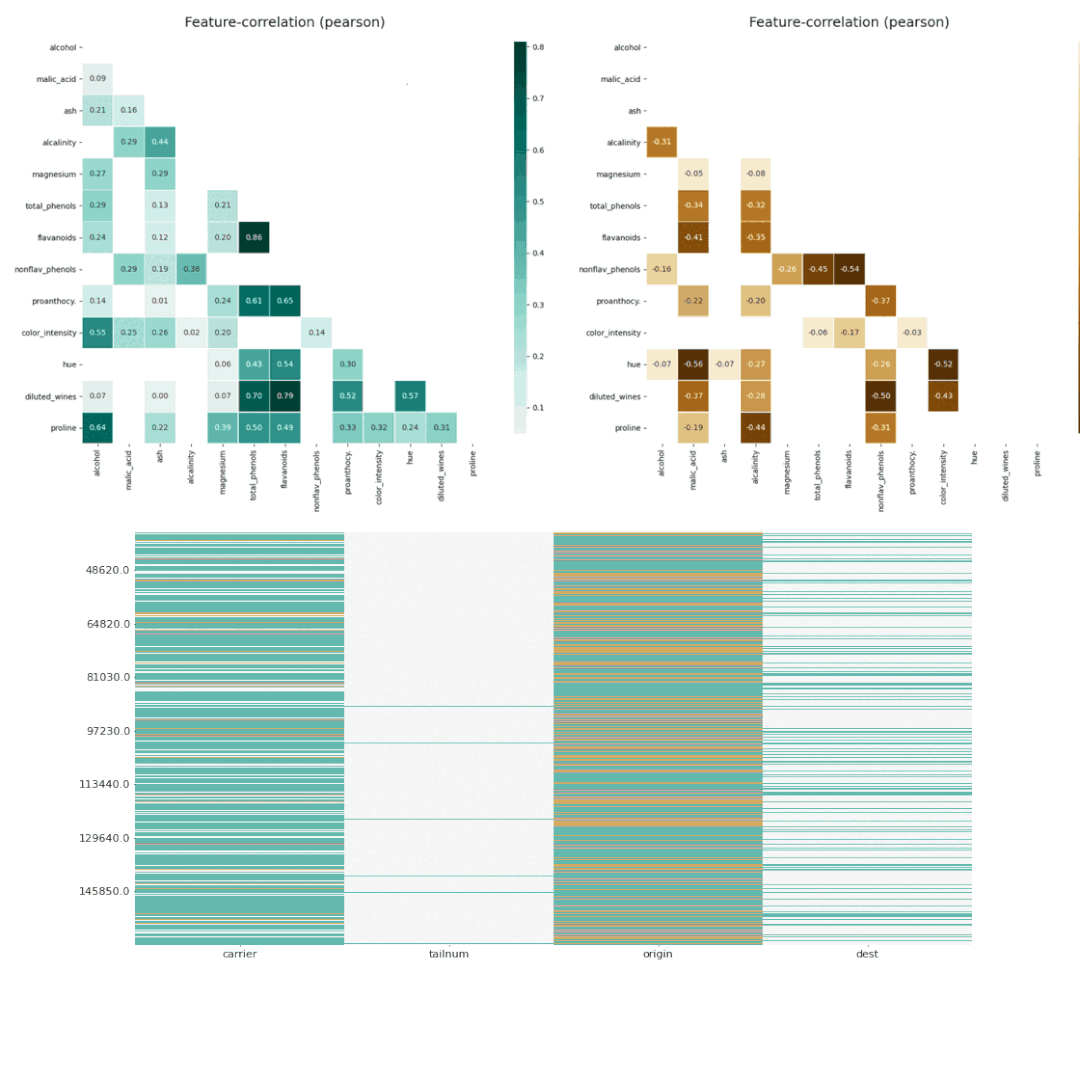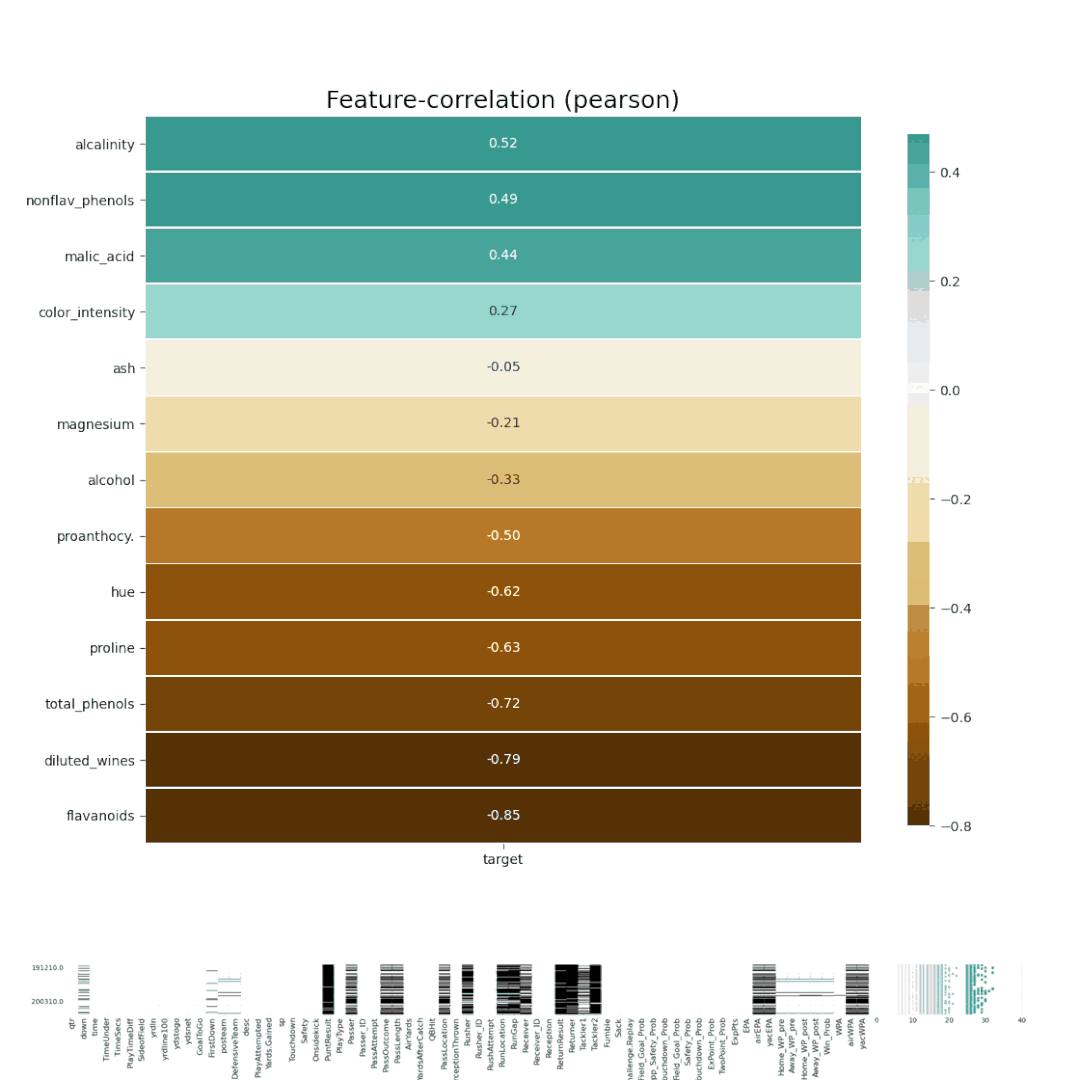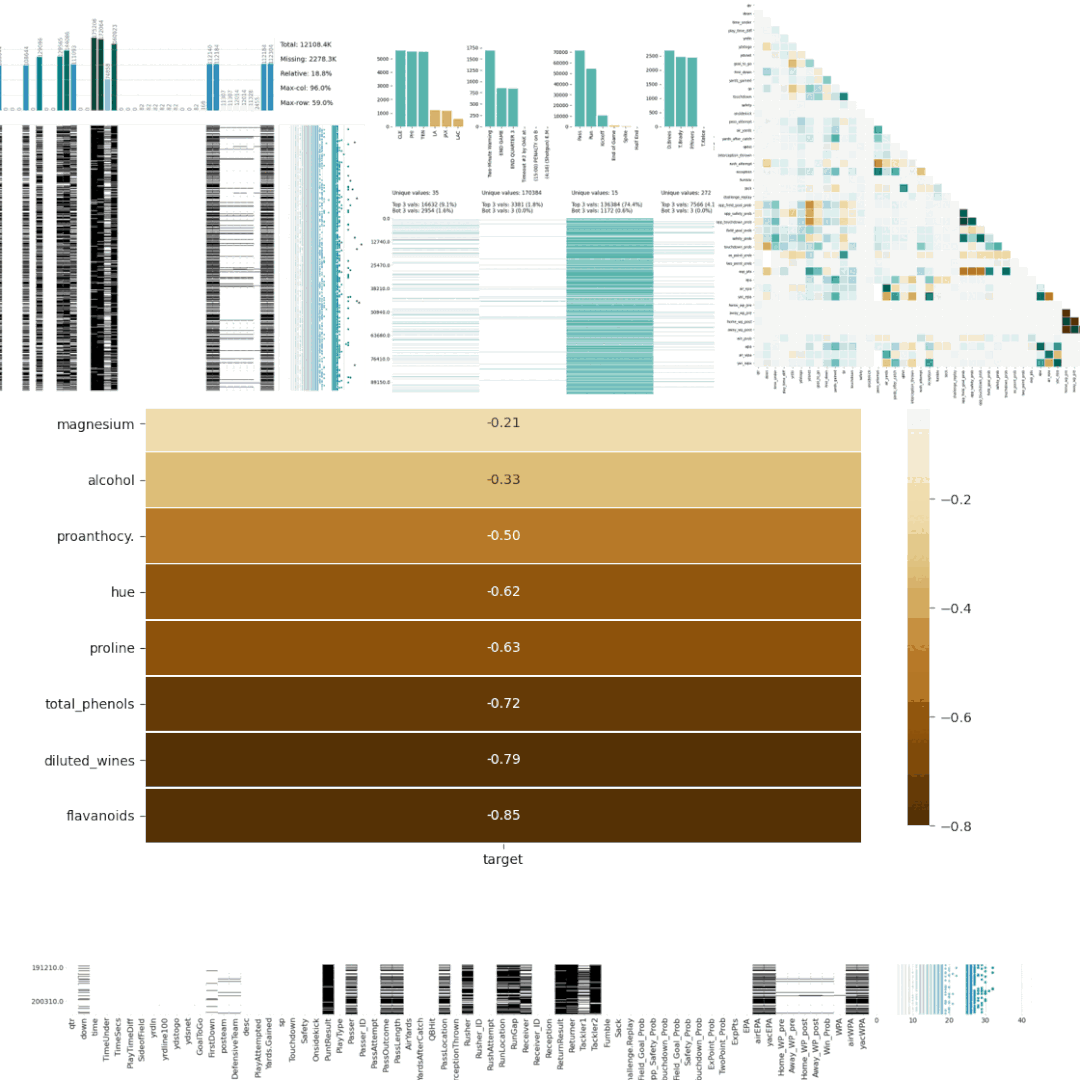
7、DablDabl 不太关注单个列的统计度量,而是更多地关注通过可视化提供快速概述,以及方便的机器学习预处理和模型搜索。dabl 中的 Plot() 函数可以通过绘制各种图来实现可视化,包括:import pandas as pd
import dabl
df = pd.read_csv("titanic.csv")
dabl.plot(df, target_col="Survived")
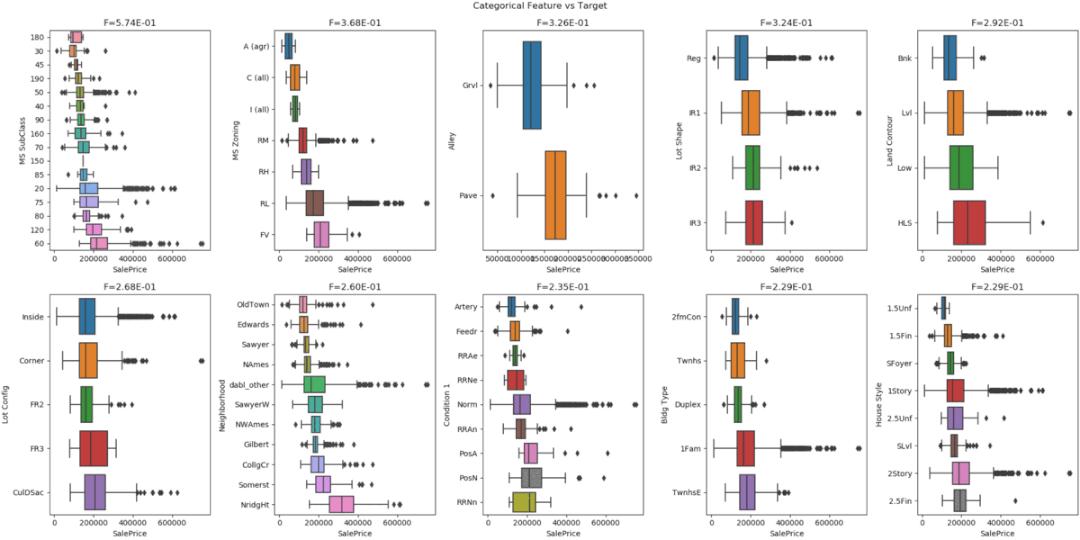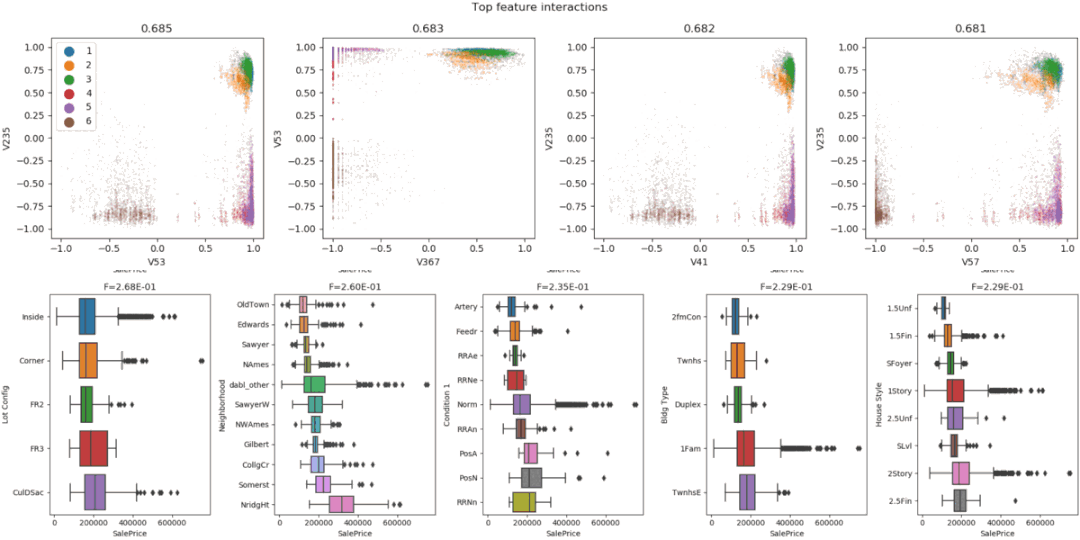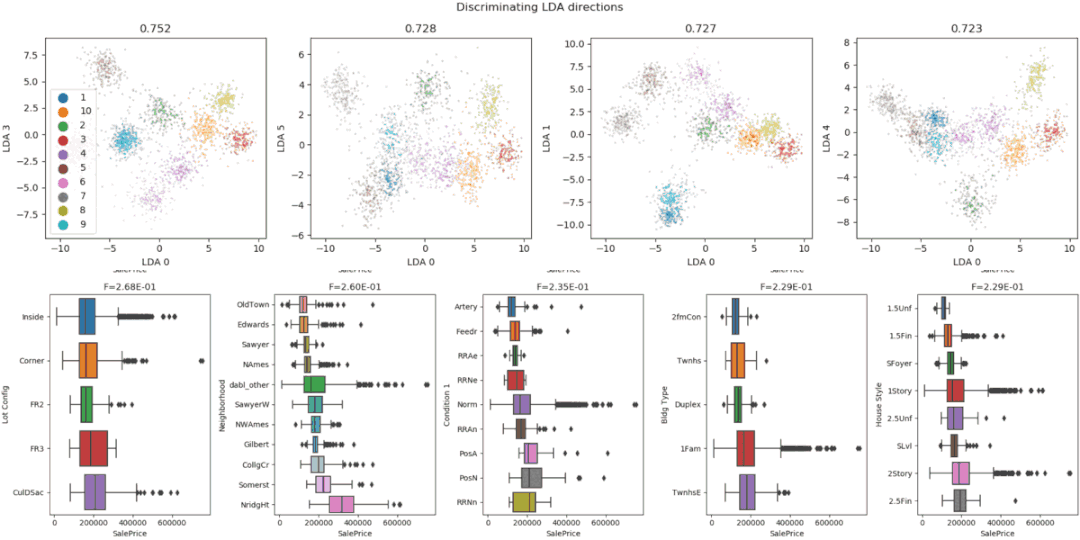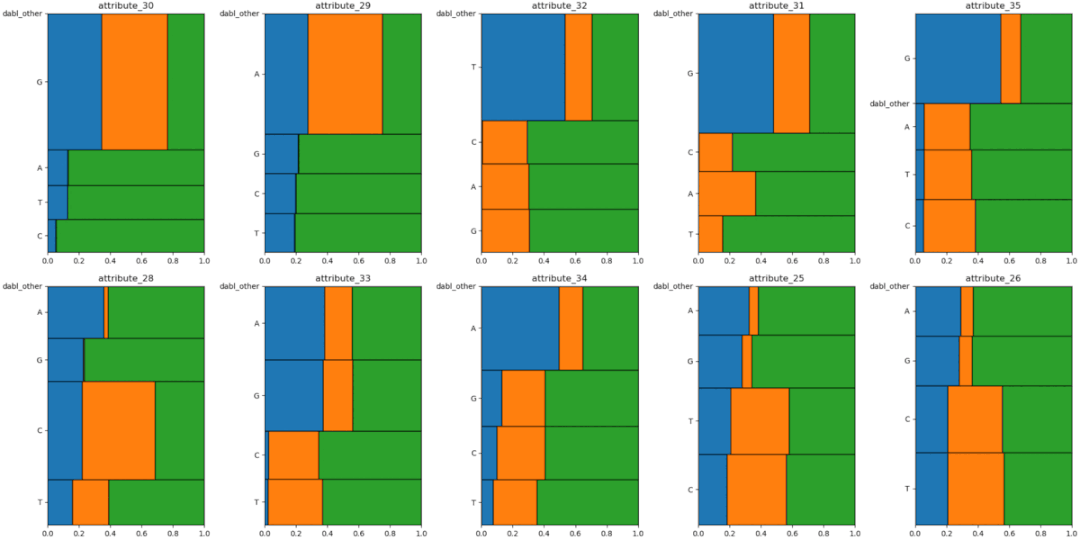
8、SpeedmlSpeedML 是用于快速启动机器学习管道的 Python 包。SpeedML 整合了一些常用的 ML 包,包括 Pandas,Numpy,Sklearn,Xgboost 和 Matplotlib,所以说其实 SpeedML 不仅仅包含自动化 EDA 的功能。SpeedML 官方说,使用它可以基于迭代进行开发,将编码时间缩短了 70%。
from speedml import Speedml
sml = Speedml('../input/train.csv', '../input/test.csv',
target = 'Survived', uid = 'PassengerId')
sml.train.head()
sml.plot.ordinal('Parch')
sml.plot.ordinal('SibSp')
sml.plot.continuous('Age')
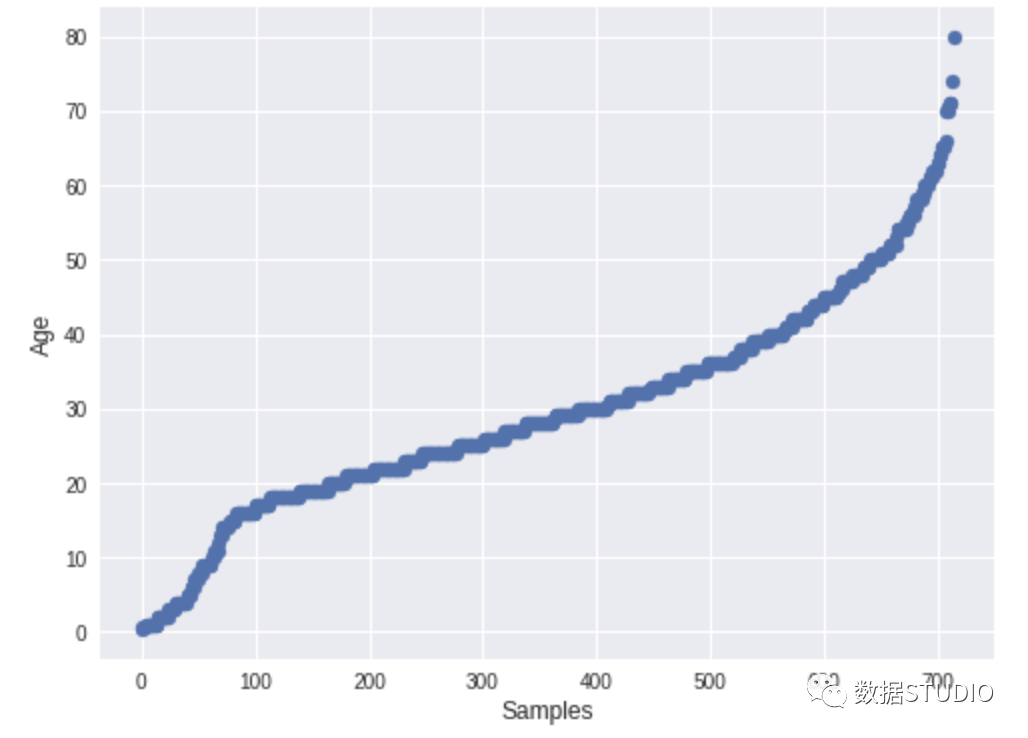
9、DataTileDataTile(以前称为Pandas-Summary)是一个开源的Python软件包,负责管理,汇总和可视化数据。DataTile基本上是PANDAS DataFrame describe()函数的扩展。import pandas as pd
from datatile.summary.df import DataFrameSummary
df = pd.read_csv('titanic.csv')
dfs = DataFrameSummary(df)
dfs.summary()
10、edavizedaviz 是一个可以在 Jupyter Notebook 和 Jupyter Lab 中进行数据探索和可视化的 python 库,他本来是非常好用的,但是后来被砖厂 (Databricks) 收购并且整合到 bamboolib 中,所以这里就简单的给个演示。在本文中,我们介绍了 10 个自动探索性数据分析 Python 软件包,这些软件包可以在几行 Python 代码中生成数据摘要并进行可视化。通过自动化的工作可以节省我们的很多时间。Dataprep 是我最常用的 EDA 包,AutoViz 和 D-table 也是不错的选择,如果你需要定制化分析可以使用 Klib,SpeedML 整合的东西比较多,单独使用它啊进行 EDA 分析不是特别的适用,其他的包可以根据个人喜好选择,其实都还是很好用的,最后 edaviz 就不要考虑了,因为已经不开源了。







