查看引用/信息源请点击:映维网Nweon
视图合成深度学习模型
(映维网Nweon 2022年10月05日)视图合成是计算机视觉和计算机图形学的一个长期问题,其目标是从场景的多张图片中创建新的场景视图。自从引入神经辐射场(NeRF)以来,这一点受到了越来越多的关注。这个问题非常有挑战性,因为若要准确地合成场景的新视图,模型需要从一小组参考图像中捕获多种类型的信息,包括详细的3D结构、材质和照明。
在日前一篇博文中,谷歌介绍了最近发布的视图合成深度学习模型。在CVPR 2022大会介绍的LFNR光场神经网络渲染中,谷歌通过使用学习组合参考像素颜色的transformer来解决精确再现视图相关效果的挑战。然后,在ECCV 2022大会介绍的GPNR中,谷歌通过使用一系列具有规范化位置编码的transformer来解决泛化到未知场景的挑战。
其中,transformer可以在一组场景进行训练,并合成新场景的视图。所述模型执行基于图像的渲染,结合参考图像的颜色和特征来渲染新视图。它们完全基于transformer,在图像patch集上操作,并利用4D光场表示进行位置编码,这有助于建模视图相关的效果。

1. 概述
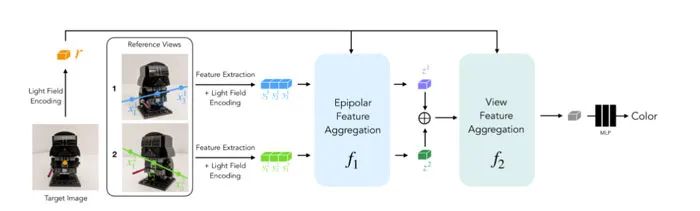
模型的输入包括一组参考图像及其camera参数(焦距、位置和空间方向),以及要确定其颜色的目标光线的坐标。为了生成新图像,研究人员从输入图像的camera参数开始,获取目标光线的坐标(每个光线对应一个像素),并查询每个光线的模型。
团队只关注可能影响目标像素的区域,而不是完全处理每个参考图像。相关区域是通过极线几何确定,它将每个目标像素映射到每个参考帧的一条线。为了增强鲁棒性,研究人员在外极线上的部分点周围选取了小片区域,从而生成了一组实际上将由模型处理的patch。然后,transformer作用于这组patch以获得目标像素的颜色。
transformer在这种设置中特别有用,因为它们的self-attention机制自然将集合作为输入,并且attention权重本身可以用于组合参考视图颜色和特征,从而预测输出像素颜色。transformer遵循ViT中介绍的架构。

2. LFNR(Light Field Neural Rendering)
在LFNR中,谷歌使用一个由两个transformer组成的序列将patch集映射到目标像素颜色。第一个transformer沿着每条外极线聚合信息,第二个沿着每条参考图像聚合信息。可以将第一个transformer解释为在每个参考帧查找目标像素的潜在对应,而第二个transformer则解释为关于遮挡和视图相关效果的推理,这是基于图像的渲染的常见挑战。
LFNR使用两个transformer序列将沿极线提取的一组patch映射到目标像素颜色。LFNR峰值信噪比(PSNR)为5dB。这相当于将像素误差减少了1.8倍。他们在下面的Shiny数据集中展示了具有挑战性场景的定性结果:


3. 泛化到新场景
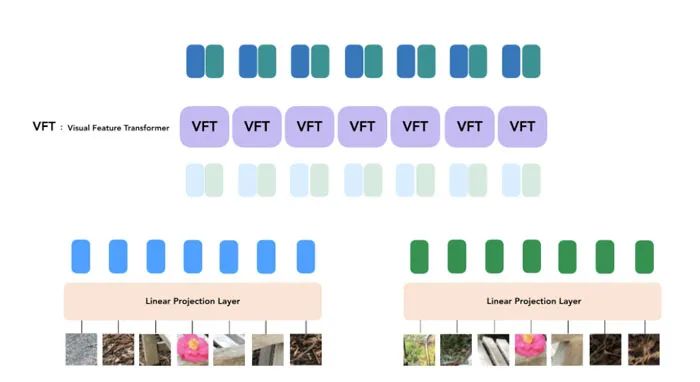
LFNR的一个局限性是,第一个transformer沿着每个外极线独立地折叠每个参考图像的信息。这意味着它仅根据每个参考图像的输出光线坐标和patch来决定要保留哪些信息,这在对单个场景进行训练时非常有效(与大多数神经渲染方法一样),但它不会在场景之间进行泛化。泛化方法非常重要,因为它们可以应用于新场景,无需重新培训。
团队在Generalizable Patch-Based Neural Rendering(GPNR)中克服了LFNR的这一局限性。他们添加了一个在其他两个之前运行的transformer,并在所有参考图像相同深度的点之间交换信息。例如,第一个transformer查看上图公园长凳的一列patch,并可以使用诸如花朵这样的线索。这项研究的另一个关键思想是规范化基于目标光线的位置编码,因为要在场景中进行泛化,必须以相对而非绝对参考帧表示数量。
为了评估泛化性能,他们在一组场景训练GPNR,并在新场景测试。GPNR在几个基准测试中平均提高了0.5–1.0 dB。在IBRNet基准测试中,GPNR的表现优于基线,并且只使用了11%的训练场景。


4. 局限
大多数神经渲染方法(包括谷歌)的一个局限性是,它们需要为每个输入图像设置camera姿势。camera姿势不容易获得,并且通常来自离线优化方法,速度较慢,限制了可能的应用。联合学习视图合成和输入姿势是一个富有前景的研究方向。谷歌模型的另一个限制是,训练它们的计算成本非常高。
相关论文:Generalizable Patch-Based Neural Rendering
https://paper.nweon.com/13167
相关论文:Light Field Neural Rendering
https://paper.nweon.com/13165
5. 潜在误用
在研究中,团队的目标是使用场景中的图像精确地再现现有场景,因此几乎没有空间生成虚假或不存在的场景。模型假设场景为静态,所以合成移动的对象行不通。
---
原文链接:https://news.nweon.com/101281









