
时间序列异常检测在研究领域和应用中有着广泛的应用,包括制造业和医疗健康。异常的出现可能表明出现了新的或意料之外的事件,例如生产故障、系统缺陷或心脏跳动,因此特别值得关注。时间序列的巨大规模和复杂模式促使研究人员开发专门的深度学习模型来检测异常模式。本综述的重点是通过使用深度学习来提供结构化的、全面的、最先进的时间序列异常检测模型。它提供了基于因素的分类法,将异常检测模型划分为不同的类别。除了描述每种类型的基本异常检测技术外,还讨论了其优点和局限性。此外,本研究包含了近年来跨不同应用领域的时间序列深度异常检测实例。最后总结了在采用深度异常检测模型时研究中存在的问题和面临的挑战。
https://www.zhuanzhi.ai/paper/300e1d59715af4f2ee3ec8bf3c238000
异常检测又称异常值检测和新颖性检测,自60年代以来一直是众多研究领域的一个蓬勃发展的研究领域[74]。随着计算过程的发展,大数据和人工智能(AI)受到了积极的影响,有助于时间序列分析,包括异常检测。随着可获得的数据越来越多,算法越来越高效,计算能力越来越强,时间序列分析越来越多地被用于通过预测、分类和异常检测[59]、[26]来解决业务问题。时间序列异常检测在城市管理、入侵检测、医疗风险、自然灾害等多个领域的需求日益增长,其重要性也日益提高。
随着深度学习在过去几年的显著进步,它已经越来越有能力学习复杂时间序列的表达表示,比如同时具有空间(度量间)和时间特征的多维数据。在深度异常检测中,利用神经网络学习特征表示或异常评分来检测异常。许多深度异常检测模型已经被开发出来,在不同的现实应用中,对时间序列检测任务提供了明显高于传统异常检测的性能。虽然Chandola等人在[29]中对深度学习异常检测模型进行了广泛的综述,但本研究的目的是对深度异常检测模型进行全面的综述,重点关注时间序列数据。考虑到多变量时间序列分析比单变量时间序列分析更具挑战性,目前提出的模型主要用于处理多变量时间序列。
虽然在异常检测领域已有多篇文献综述[140],[27]、[20]、[23]和一些评价综述论文存在[154]、[102],但对时间序列数据[41]的深度异常检测方法的研究仅一篇。然而,这一综述并没有涵盖近年来出现的大量时间序列异常检测方法,如DAEMON[37]、TranAD[171]、DCT-GAN[116]和Interfusion[119]。因此,有必要进行一项涵盖该领域当前技术现状的调研,以帮助研究人员确定:1)时间序列异常检测的重要未来研究方向是什么;2)在特定的应用环境下,哪些方法适合应用。具体而言,本文有以下几点贡献:
提出了一种新的时间序列深度异常检测模型分类方法。深度异常检测模型一般分为三类:基于预测的、基于重构的和混合方法。每个类别被划分为子类别,根据模型中使用的深度神经网络架构定义子类别。模型的特征是各种不同的结构特征,这有助于其检测能力。
本研究提供了对当前技术状态的全面回顾。这一领域的发展方向和趋势已经十分清晰。
描述了该领域目前使用的主要基准和数据集,并提供了超链接。
对可能导致时间序列中不同异常发生的基本原理的讨论
本文的其余部分组织如下。在第二节中,我们从时间序列的初步定义开始。然后概述了时间序列数据异常分类的分类法。第3节讨论了深度异常检测模型如何应用于时间序列数据。然后,根据深度神经网络的主要方法(基于预测的、基于重构的、混合的)和主要架构,介绍了不同的深度模型及其功能。对于所考虑的异常检测模型,可以在第4节中找到公开可用的和常用的数据集的概述。此外,第5节探讨了时间序列深度异常检测模型在不同领域的应用领域。最后,第6节提供了该领域的几个挑战,可以作为未来的机会。
2. 深度异常检测方法
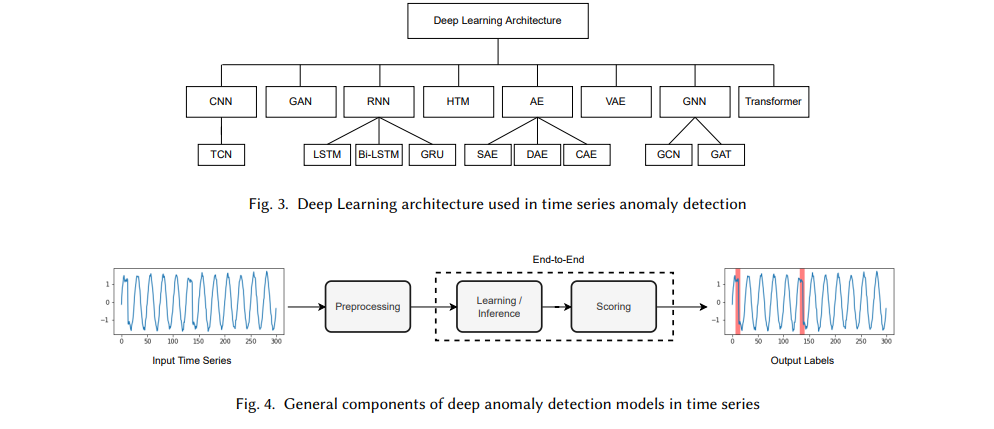
在具有复杂结构的数据中,深度神经网络是建模依赖关系的强大方法。许多学者对其在异常检测中的应用非常着迷,它使用了许多深度学习架构,如图3所示。在实践中,训练数据往往只有极少数被标记的异常。因此,大多数模型试图学习正常数据的表示或特征。然后根据异常定义检测异常,这意味着他们发现了与正常数据不同的数据。在最近的深度异常检测模型中,有四种学习方案:无监督、有监督、半监督和自监督。这是基于标签数据点的可用性(或缺乏)。监督方法采用一种独特的方法来学习异常数据和正常数据之间的边界,该方法基于在训练集中发现的所有标签。它可以确定一个适当的阈值,如果分配给这些时间戳的异常评分(第3.1节)超过阈值,则该阈值将用于将所有时间戳分类为异常。这种方法的问题是它不适用于现实世界中的应用程序,因为异常通常是未知的或标记不正确的。相反,在无监督异常检测方法中,不区分训练集和测试集。这些技术是最灵活的,因为它们完全依赖于数据的内在特征。它们在流应用程序中很有用,因为它们不需要标签进行培训和测试。尽管有这些优点,研究人员可能会遇到困难,评估异常检测模型使用非监督方法。异常检测问题通常被视为无监督学习问题,因为历史数据固有的无标记性质和异常的不可预测性质。在数据集只包含正常点且不存在异常的情况下,可以使用半监督方法。然后,训练一个模型来拟合时间序列分布,并检测任何偏离该分布的点作为异常。通过充分利用未标记数据本身(例如,通过设计文本前任务),训练自监督方法从其可观察部分预测输入的任何未观察部分(或属性)。在自监督学习中,只需要从无监督问题中自动生成少量的标记,因此将无监督问题转换为有监督问题。
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自:专知









